
Python爬虫--爬取文字加密的番茄小说
一、学爬虫,看小说
很久没有去研究爬虫了,借此去尝试爬取小说查看小说,发现页面返回的内容居然都是加密的。
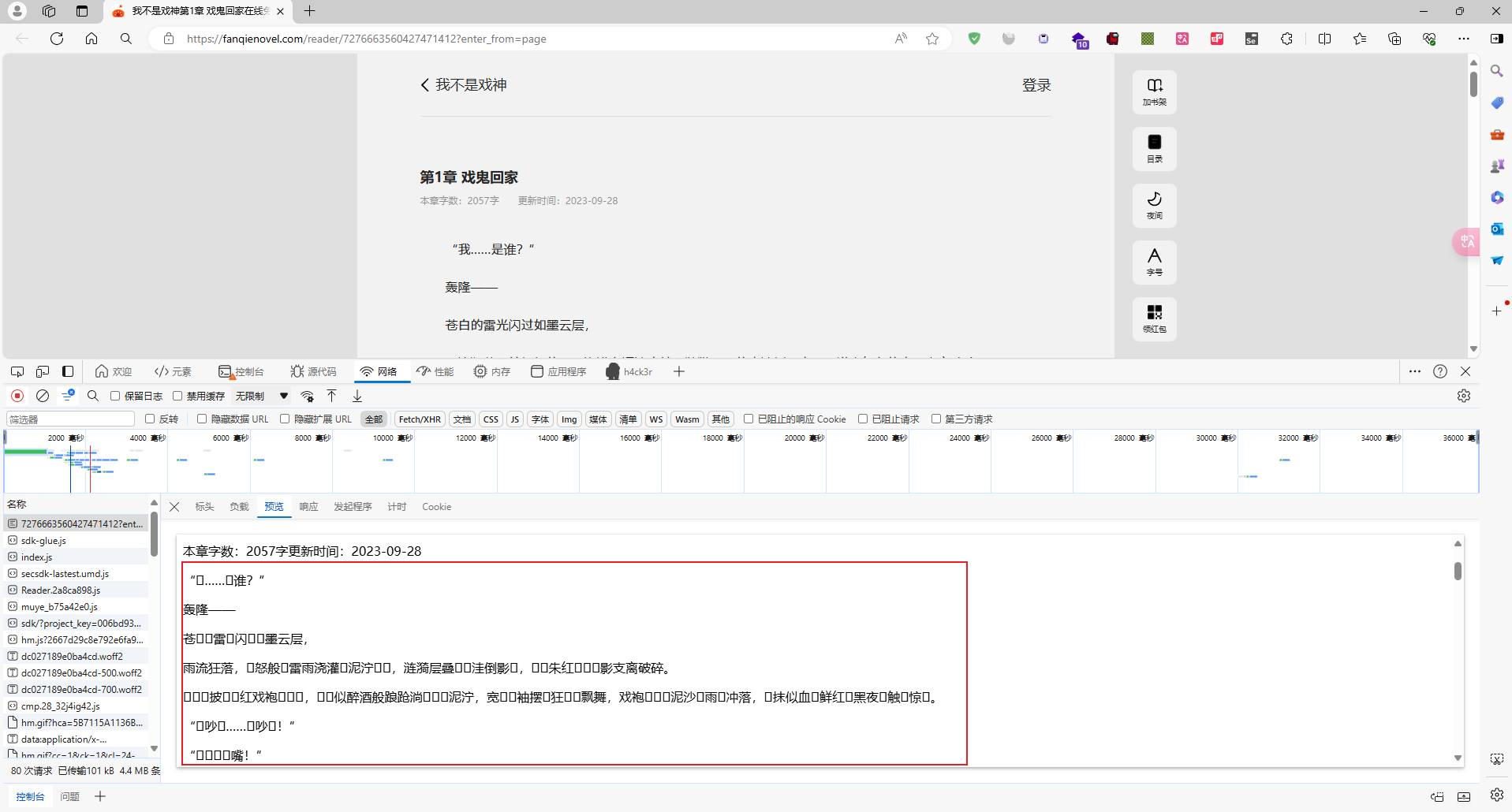
二、对小说目录进行分析
通过分析小说目录页面,获取小说名称等内容
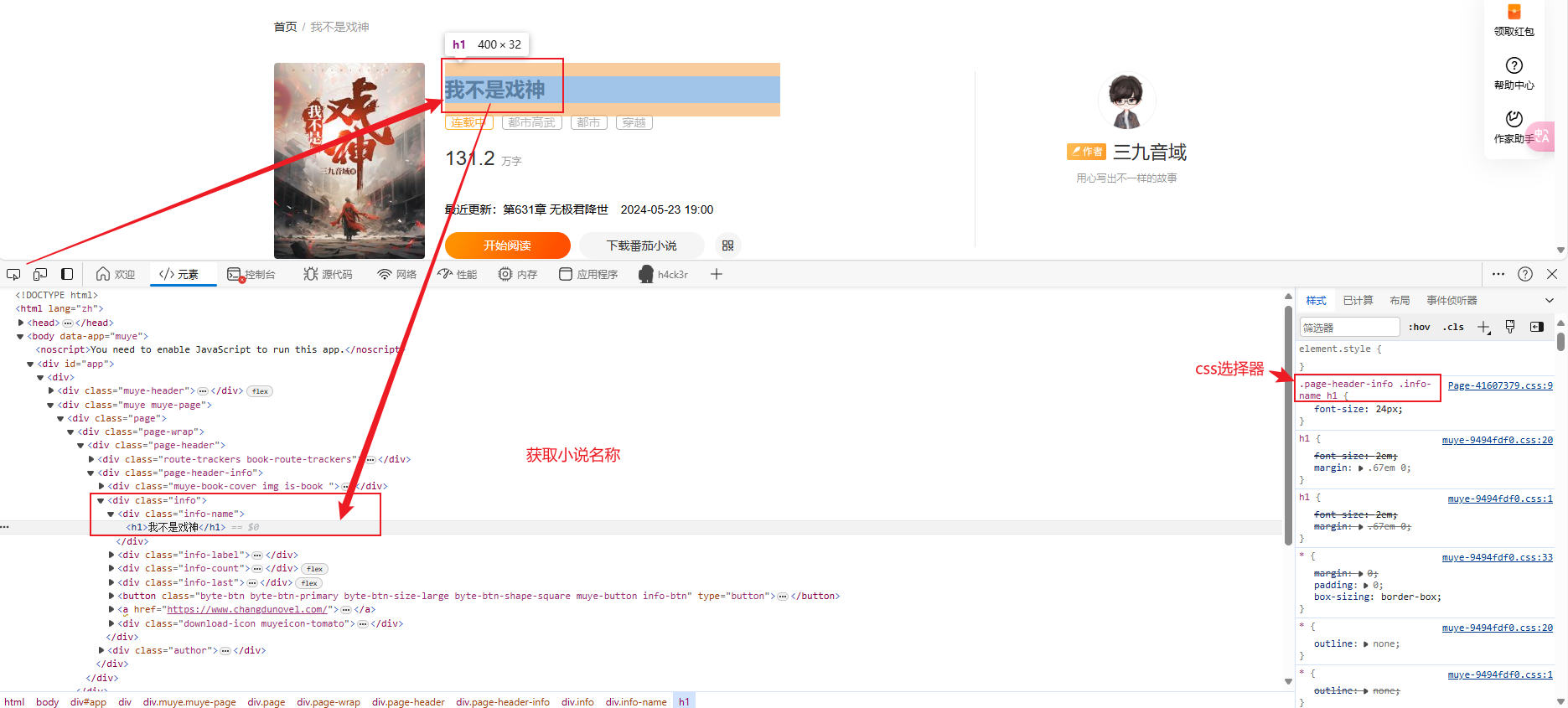
引用parsel包,对页面信息进行获取
url = "https://fanqienovel.com/reader/7276663560427471412?enter_from=page" # 发送请求 response = requests.get(url=url, headers=headers) # 获取响应得文本数据(html字符串数据) html_data = response.text """解析数据:提取需要得数据内容""" # 把html字符串数据转成可解析对象 selector = parsel.Selector(html) # xpath 匹配内容 text = selector.xpath('string(//div[@class="muye-reader-content noselect"])').get() # re 正则匹配内容 text = selector.re(r'<p>(.*?)</p>') # css选择器匹配 # 章节名 name = select.css('.muye-reader-title::text').get() print(name)
直接上代码
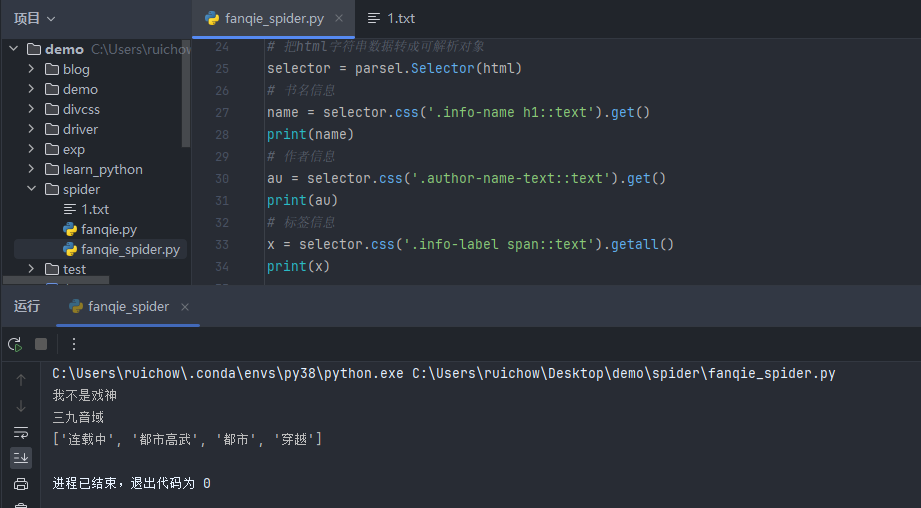
1 import requests 2 import parsel 3 4 # URL地址(请求地址) 5 url = "https://fanqienovel.com/page/7276384138653862966" 6 # 模拟浏览器 7 headers = { 8 # cookie 9 'Cookie': 'Hm_lvt_2667d29c8e792e6fa9182c20a3013175=1716438629; csrf_session_id=cb69e6cf3b1af43a88a56157e7795f2e; ' 10 'novel_web_id=7372047678422058532; s_v_web_id=verify_lwir8sbl_HcMwpu3M_DoJp_4RKG_BcMo_izZ4lEmNBlEQ; ' 11 'Hm_lpvt_2667d29c8e792e6fa9182c20a3013175=1716454389; ttwid=1%7CRpx4a-wFaDG9-ogRfl7wXC7k61DQkWYwkb_Q2THE' 12 'qb4%7C1716454388%7Cb80bb1f8f2ccd546e6a1ccd1b1abb9151e31bbf5d48e3224451a90b7ca5d534c; msToken=-9U5-TOe5X2' 13 'axgeeY4G28F-tp-R7o8gDaOF5p2fPPvcNdZYLXWU9JiPv_tOU81HeXCDT52o4UtGOLCZmuDMN2I8yulNK-8hIUpNSHiEVK3ke5aEeG' 14 'J4wDhk_cQgJ3g==', 15 # User-Agent 16 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 ' 17 'Safari/537.36' 18 } 19 # 发送请求 20 response = requests.get(url=url, headers=headers) 21 # 获取响应得文本数据(html字符串数据) 22 html = response.text 23 """解析数据:提取需要得数据内容""" 24 # 把html字符串数据转成可解析对象 25 selector = parsel.Selector(html) 26 # 书名信息 27 name = selector.css('.info-name h1::text').get() 28 print(name) 29 # 作者信息 30 au = selector.css('.author-name-text::text').get() 31 print(au) 32 # 标签信息 33 x = selector.css('.info-label span::text').getall() 34 print(x)
运行结果如下:
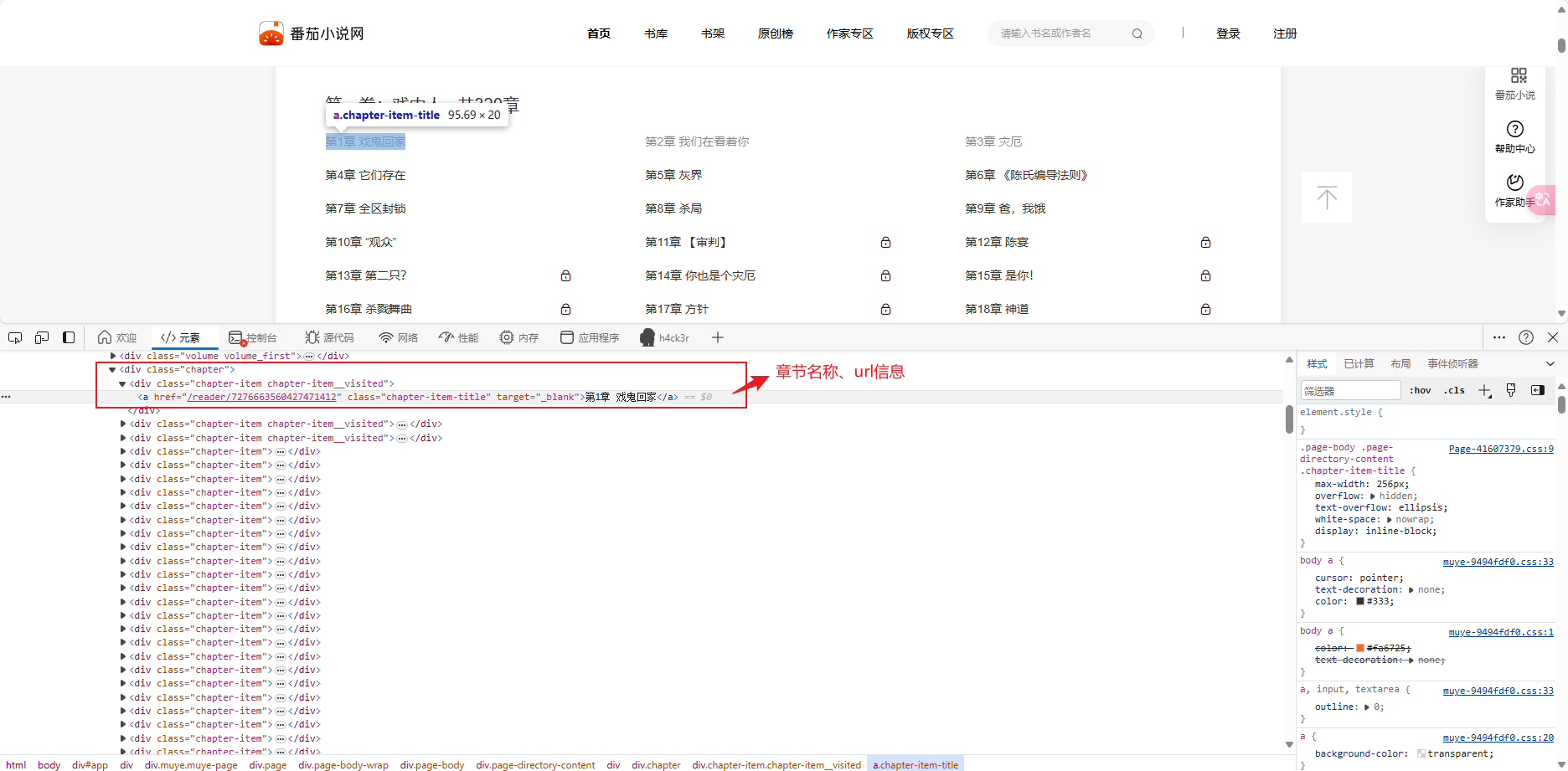
继续获取章节名称信息、章节URL
获取章节名称、章节URL信息
分析页面信息,使用css选择器,进行提取对应字段
# css选择器 # 章节名称 .chapter-item-title::text # 章节对应url .chapter-item-title::attr(href)
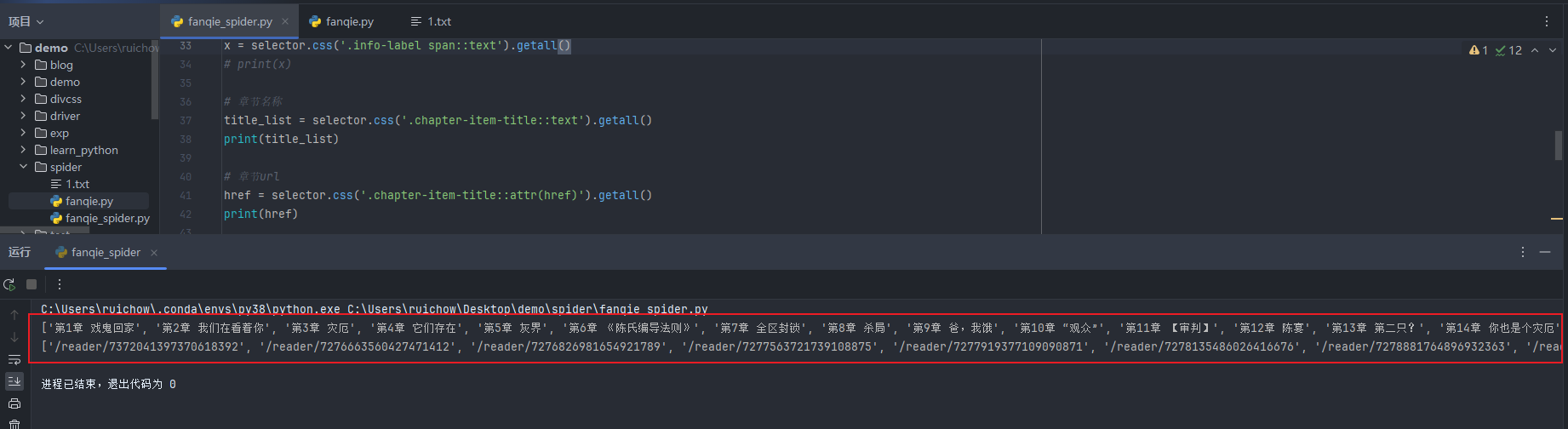
# 章节名称 title_list = selector.css('.chapter-item-title::text').getall() print(title_list) # 章节url href = selector.css('.chapter-item-title::attr(href)').getall() print(href)
代码运行结果
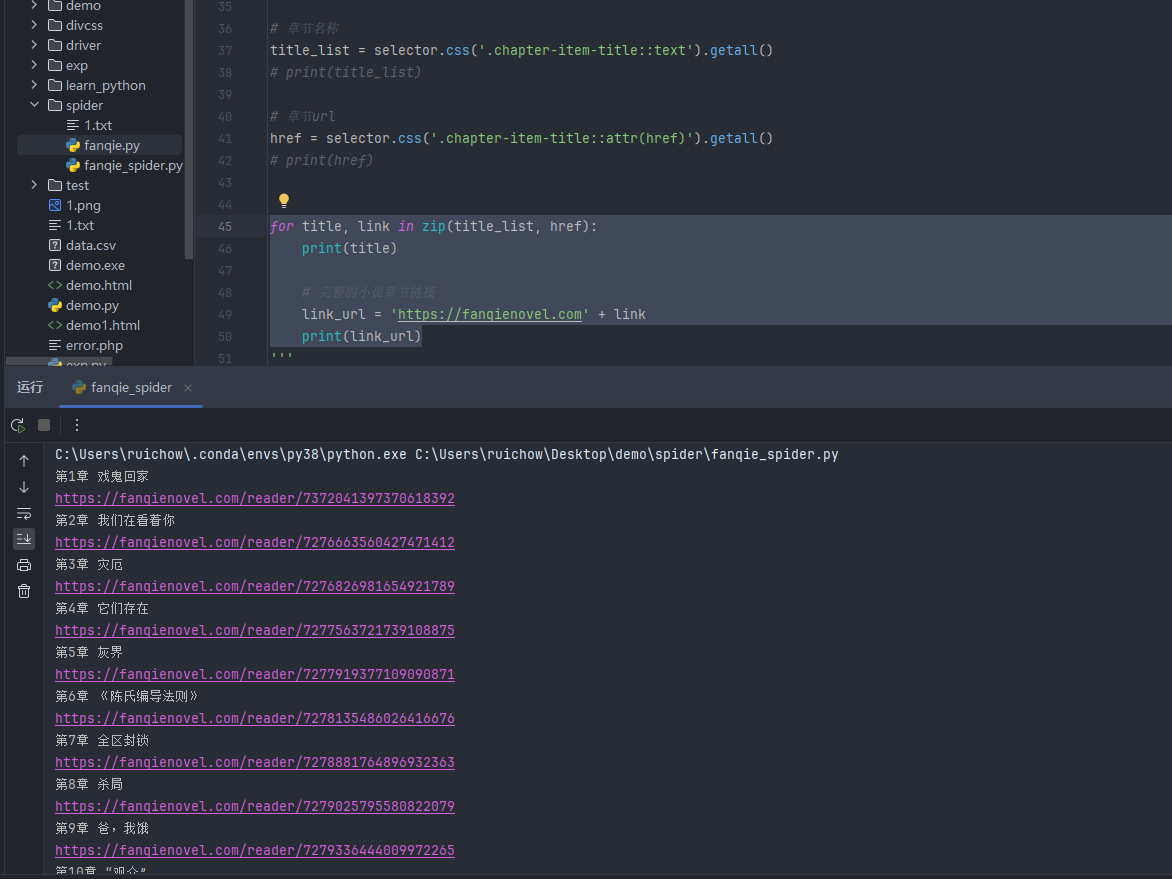
对url进行拼接
for title, link in zip(title_list, href): print(title) # 完整的小说章节链接 link_url = 'https://fanqienovel.com' + link print(link_url)
代码运行
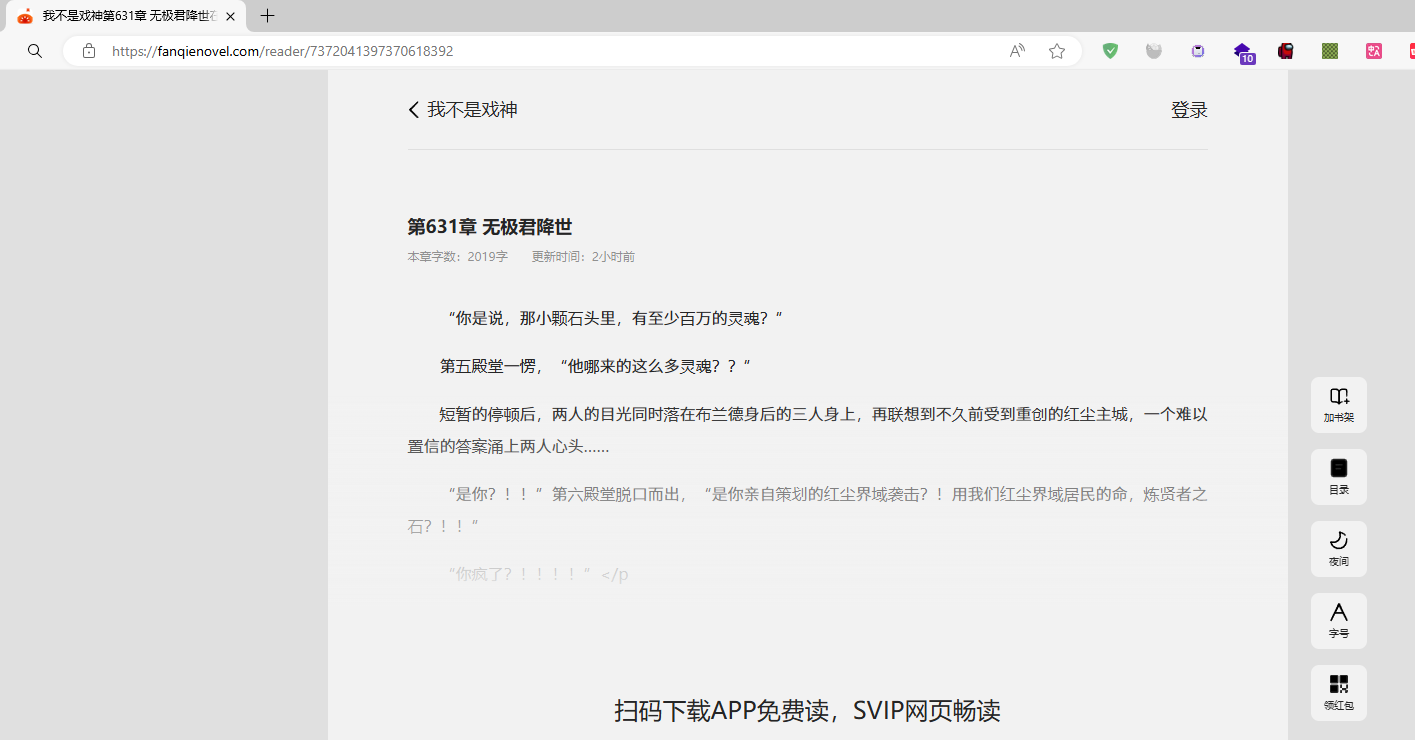
对url进行检查,发现第1章的url显示并不正确,访问后并不是第1章的内容,7372041397370618392
代码修改
检查页面herf信息,发现会显示最近更新的href,对应id与代码运行时显示第一章的id一样。需要对代码进行修改
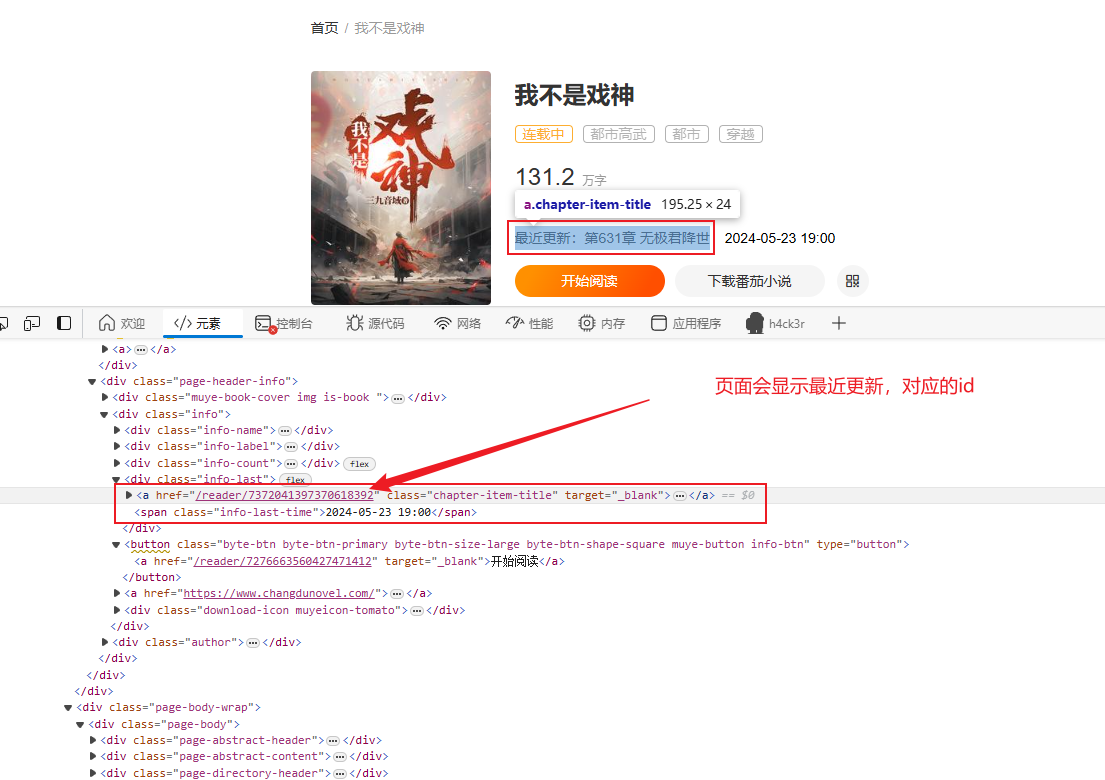
修改代码
for title, link in zip(title_list, href[1:]): print(title) # 完整的小说章节链接 link_url = 'https://fanqienovel.com' + link print(link_url)
代码运行成功
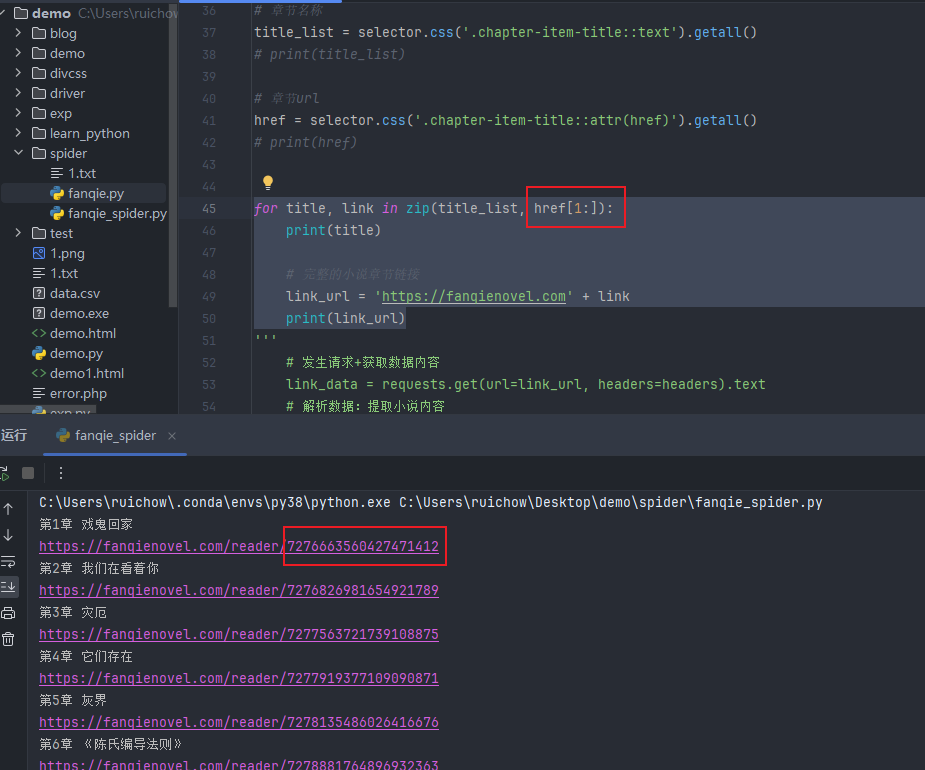
url检查成功
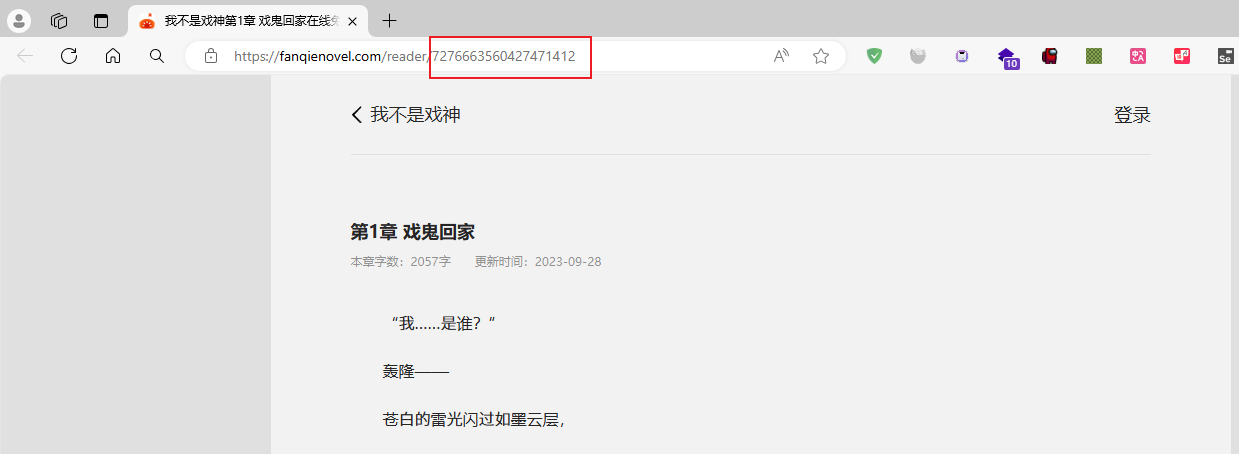
三、获取url页面的数据
提取页面的数据信息
# 发生请求+获取数据内容 link_data = requests.get(url=link_url, headers=headers).text # 解析数据:提取小说内容 link_selector = parsel.Selector(link_data) # 提取小说内容 content_list = link_selector.css('.muye-reader-content-16 p::text').getall() # 把列表合并成字符串 content = '\n'.join(content_list)
代码运行
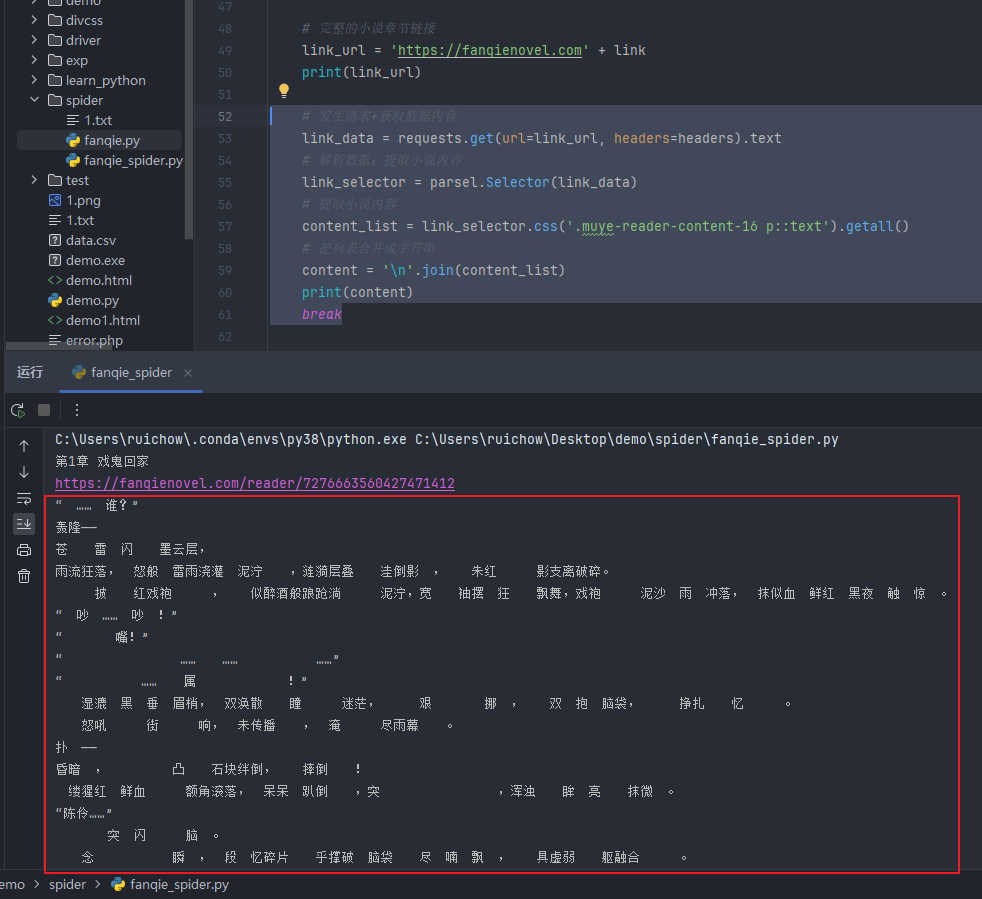
发现可以获取页面的部分内容,但内容并不完整,很多文字被加密,无法展示
四、文字内容解密
对页面进行分析,双击下载字体库
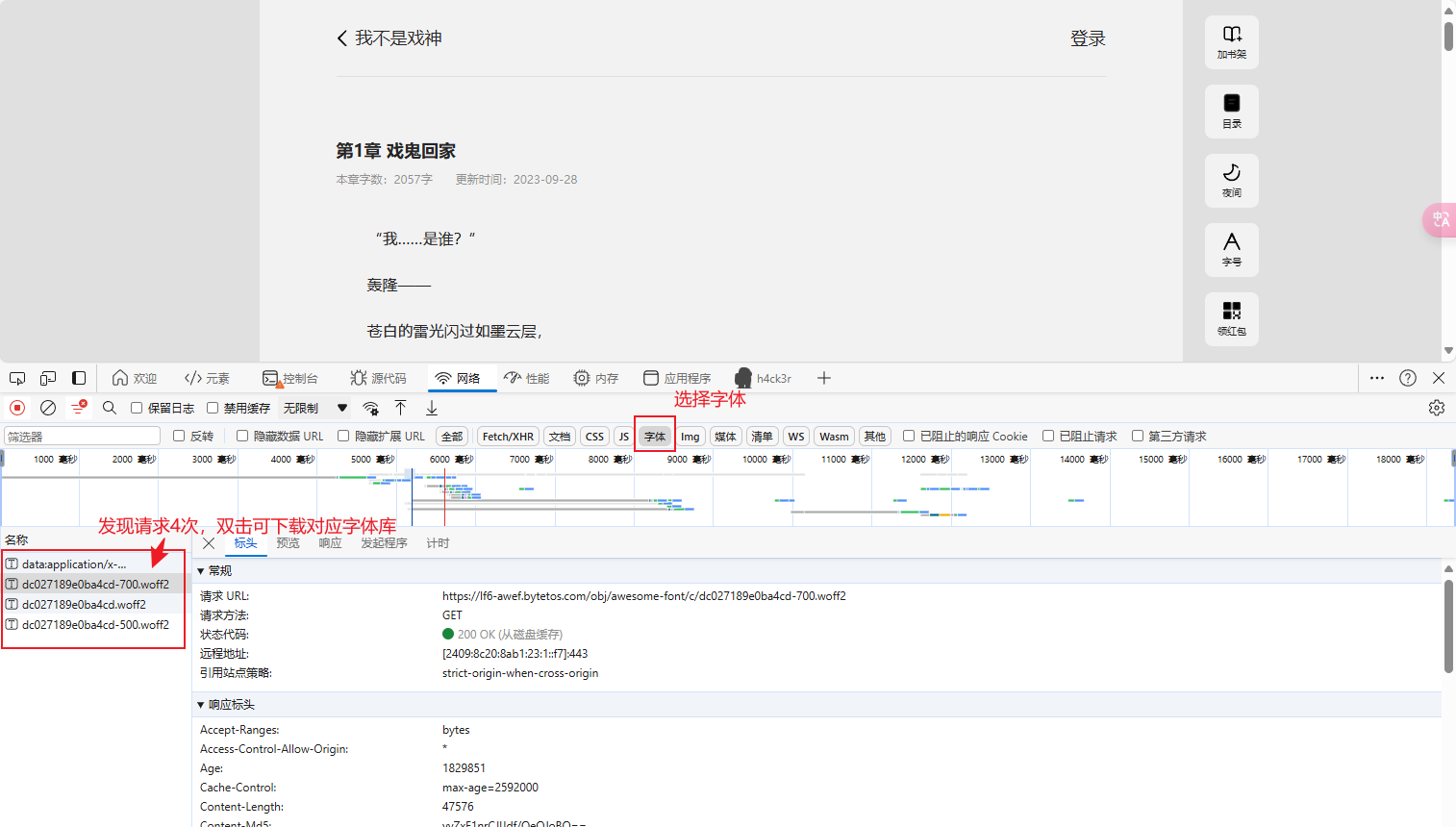
成功下载字体库

使用软件FontCreator.exe打开,可查看字体库内容
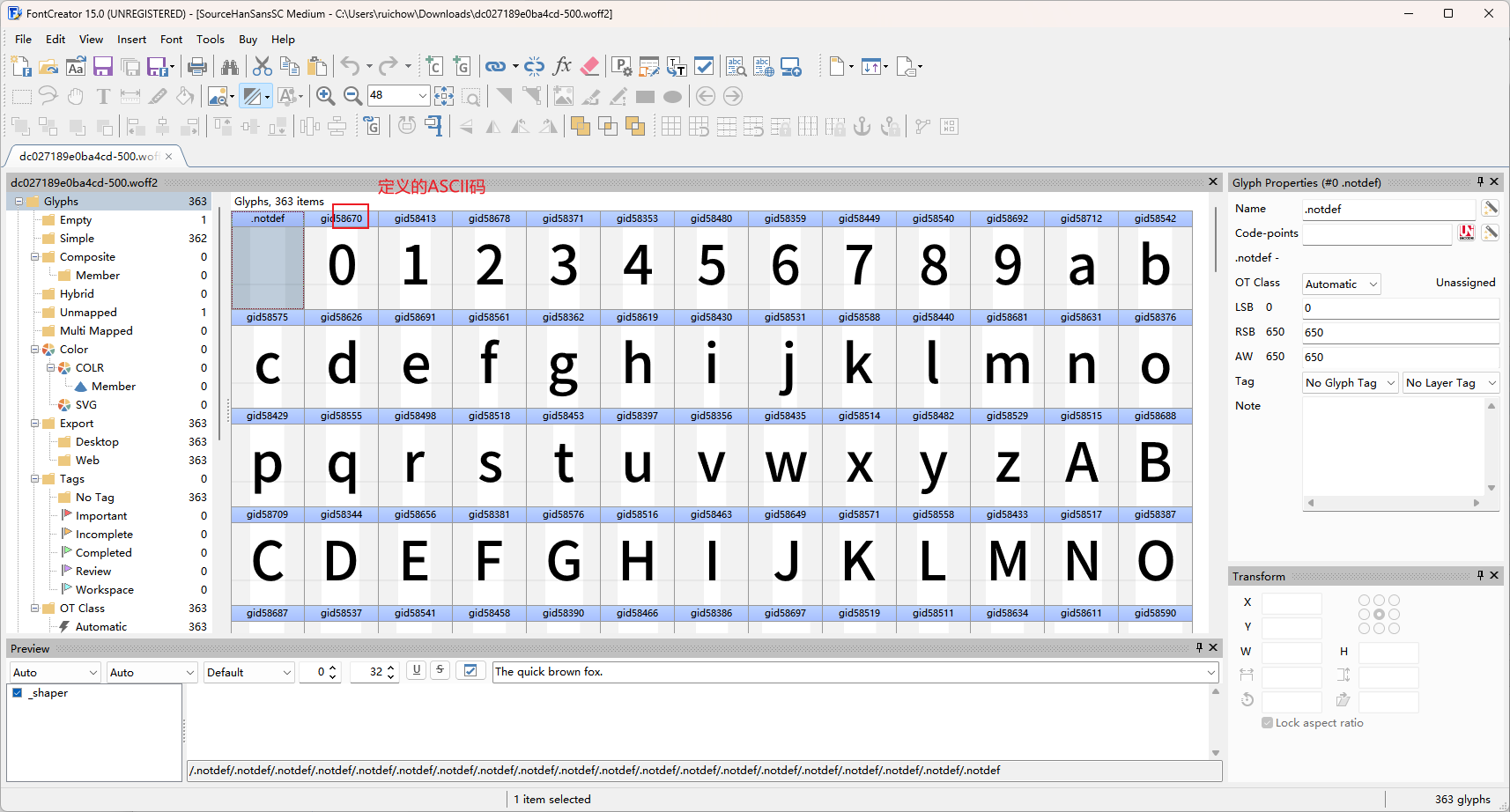
对获取的小说内容进行转换
使用ord函数,对获取的内容转码
# 发生请求+获取数据内容 link_data = requests.get(url=link_url, headers=headers).text # 解析数据:提取小说内容 link_selector = parsel.Selector(link_data) # 提取小说内容 content_list = link_selector.css('.muye-reader-content-16 p::text').getall() # 把列表合并成字符串 content = '\n'.join(content_list) for i in content: print(i, "-->", ord(i))
运行结果:
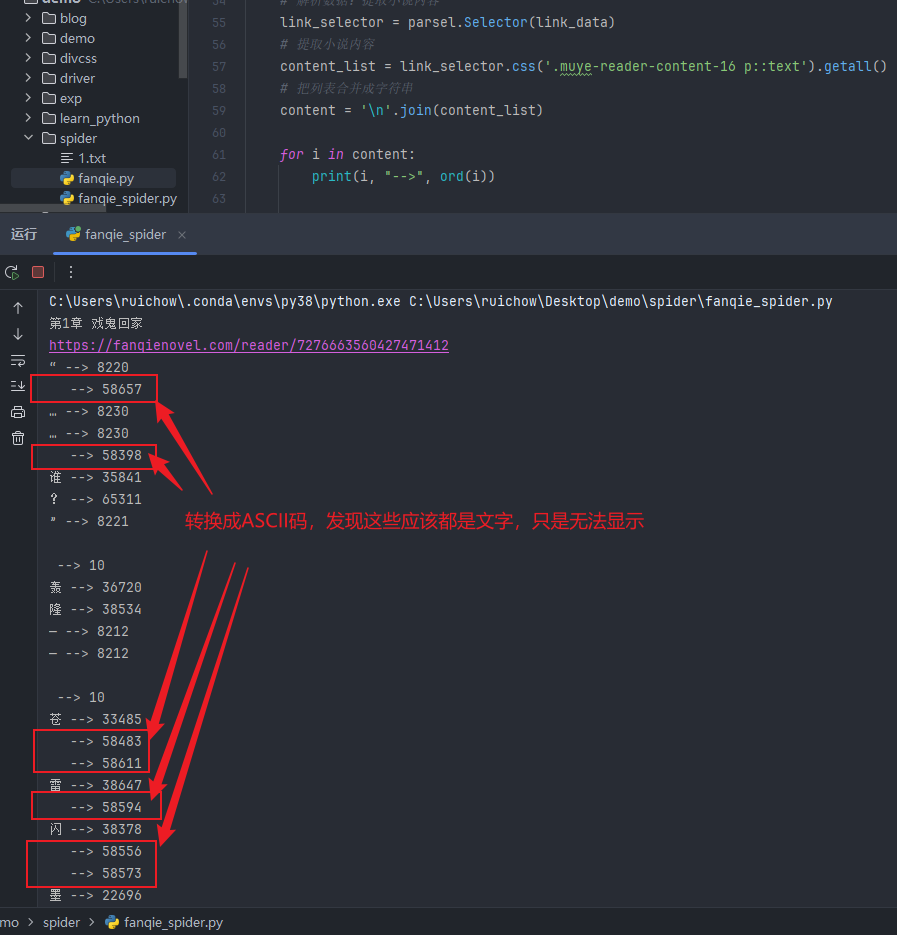
针对获得的数据信息进行分析
在下载的字体库中可以找到对应的汉字
如 ascii码 58657 ---> 我
58398 ---> 是
58483 ---> 白
58611 ---> 的

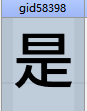


以此类推
需要整理一份对应的字典表,将字体库中的对应关系整理出来才行。
通过将获取的内容进行替换之后,即可获得完整的信息
解密处理
1 text = select.css('.muye-reader-content-16 p::text').getall() 2 content = '\n'.join(text) 3 # print(content) 4 for index in content: 5 try: 6 t1 = dict_data[str(ord(index))] 7 print(t1, end="") 8 except: 9 t1 = index 10 print(t1, end="")
运行结果
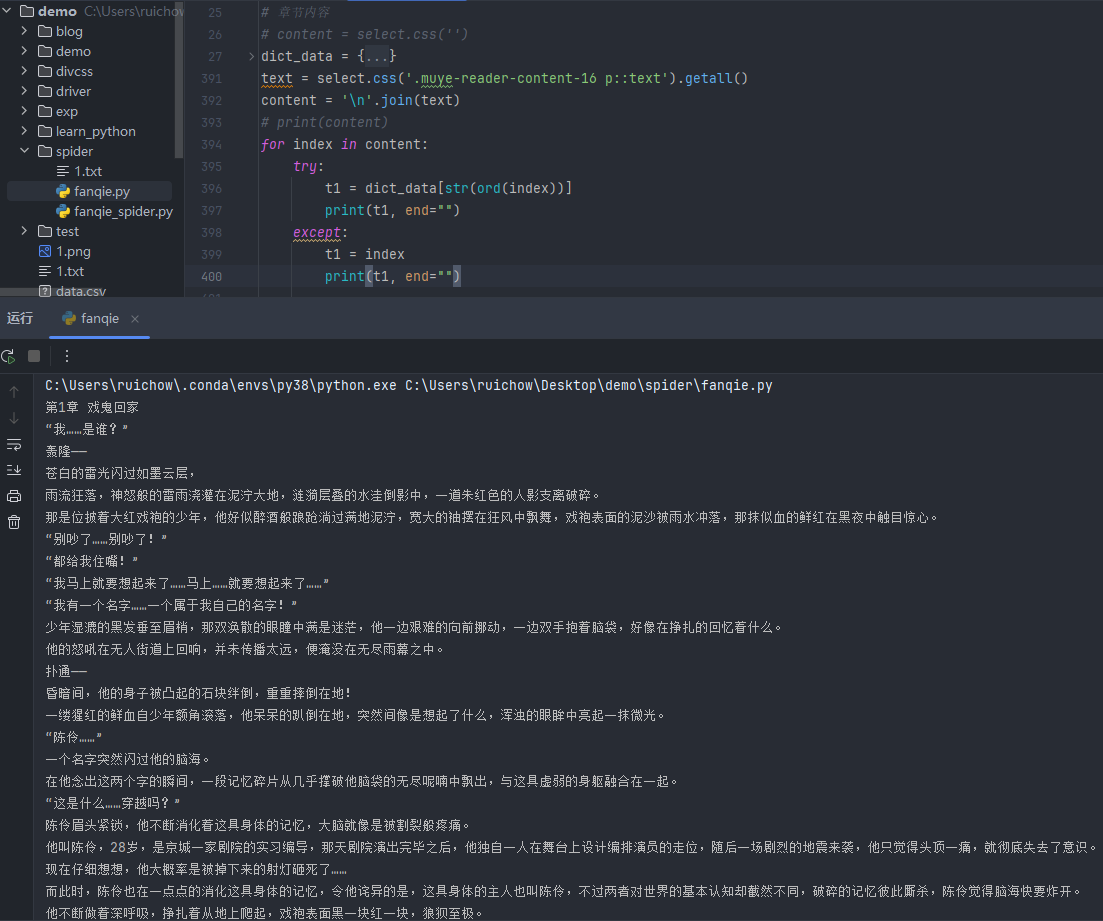
结果显示与页面显示的内容一致

数据保存
对获取的内容进行保存即可
text = select.css('.muye-reader-content-16 p::text').getall() content = '\n'.join(text) # print(content) result = [] for index in content: try: t1 = dict_data[str(ord(index))] # print(t1, end="") result.append(t1) except: t1 = index # print(t1, end="") result.append(t1) # 写入文件 with open('2.txt', mode='a', encoding='utf8') as f: f.write(name + '\n') # 写入章节名称 for i in result: f.write(i)
运行结果:
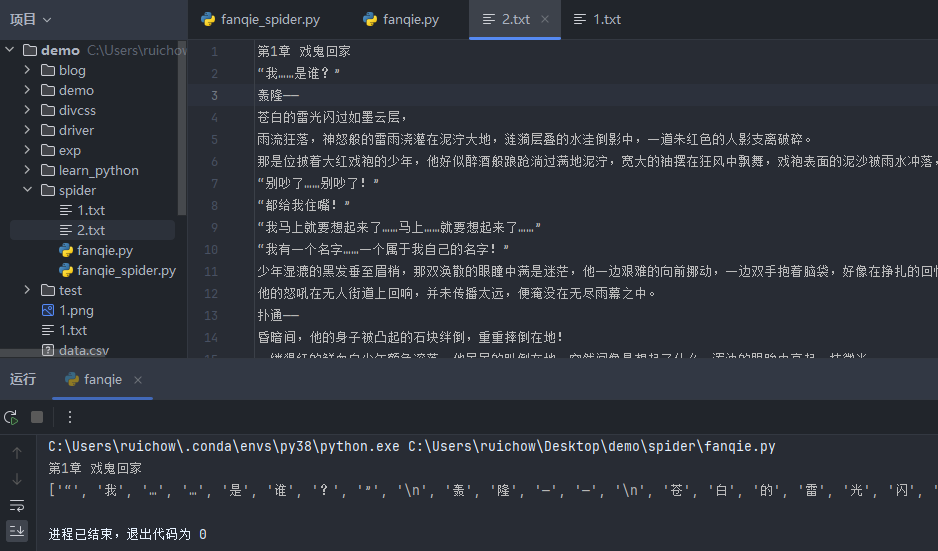
完整代码:
PS:由于其中的解密字典,是手动整理的,不保证准确性。思路仅供参考。
1 import requests 2 import parsel 3 4 # URL地址(请求地址) 5 url = "https://fanqienovel.com/page/7276384138653862966" 6 # 模拟浏览器 7 headers = { 8 # cookie 9 'Cookie': 'Hm_lvt_2667d29c8e792e6fa9182c20a3013175=1716438629; csrf_session_id=cb69e6cf3b1af43a88a56157e7795f2e; ' 10 'novel_web_id=7372047678422058532; s_v_web_id=verify_lwir8sbl_HcMwpu3M_DoJp_4RKG_BcMo_izZ4lEmNBlEQ; ' 11 'Hm_lpvt_2667d29c8e792e6fa9182c20a3013175=1716454389; ttwid=1%7CRpx4a-wFaDG9-ogRfl7wXC7k61DQkWYwkb_Q2THE' 12 'qb4%7C1716454388%7Cb80bb1f8f2ccd546e6a1ccd1b1abb9151e31bbf5d48e3224451a90b7ca5d534c; msToken=-9U5-TOe5X2' 13 'axgeeY4G28F-tp-R7o8gDaOF5p2fPPvcNdZYLXWU9JiPv_tOU81HeXCDT52o4UtGOLCZmuDMN2I8yulNK-8hIUpNSHiEVK3ke5aEeG' 14 'J4wDhk_cQgJ3g==', 15 # User-Agent 16 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 ' 17 'Safari/537.36' 18 } 19 # 发送请求 20 response = requests.get(url=url, headers=headers) 21 # 获取响应得文本数据(html字符串数据) 22 html = response.text 23 """解析数据:提取需要得数据内容""" 24 # 把html字符串数据转成可解析对象 25 selector = parsel.Selector(html) 26 # 书名信息 27 name = selector.css('.info-name h1::text').get() 28 # print(name) 29 # 作者信息 30 au = selector.css('.author-name-text::text').get() 31 # print(au) 32 # 标签信息 33 x = selector.css('.info-label span::text').getall() 34 # print(x) 35 36 # 章节名称 37 title_list = selector.css('.chapter-item-title::text').getall() 38 # print(title_list) 39 40 # 章节url 41 href = selector.css('.chapter-item-title::attr(href)').getall() 42 # print(href) 43 44 45 for title, link in zip(title_list, href[1:]): 46 print(title) 47 48 # 完整的小说章节链接 49 link_url = 'https://fanqienovel.com' + link 50 print(link_url) 51 52 # 发生请求+获取数据内容 53 link_data = requests.get(url=link_url, headers=headers).text 54 # 解析数据:提取小说内容 55 link_selector = parsel.Selector(link_data) 56 # 提取小说内容 57 content_list = link_selector.css('.muye-reader-content-16 p::text').getall() 58 # 把列表合并成字符串 59 content = '\n'.join(content_list) 60 61 # for i in content: 62 # print(i, "-->", ord(i)) 63 64 dict_data = { 65 '58670': '0', 66 '58413': '1', 67 '58678': '2', 68 '58371': '3', 69 '58353': '4', 70 '58480': '5', 71 '58359': '6', 72 '58449': '7', 73 '58540': '8', 74 '58692': '9', 75 '58712': 'a', 76 '58542': 'b', 77 '58575': 'c', 78 '58626': 'd', 79 '58691': 'e', 80 '58561': 'f', 81 '58362': 'g', 82 '58619': 'h', 83 '58430': 'i', 84 '58531': 'j', 85 '58588': 'k', 86 '58440': 'l', 87 '58681': 'm', 88 '58631': 'n', 89 '58376': 'o', 90 '58429': 'p', 91 '58555': 'q', 92 '58498': 'r', 93 '58518': 's', 94 '58453': 't', 95 '58397': 'u', 96 '58356': 'v', 97 '58435': 'w', 98 '58514': 'x', 99 '58482': 'y', 100 '58529': 'z', 101 '58515': 'A', 102 '58688': 'B', 103 '58709': 'C', 104 '58344': 'D', 105 '58656': 'E', 106 '58381': 'F', 107 '58576': 'G', 108 '58516': 'H', 109 '58463': 'I', 110 '58649': 'J', 111 '58571': 'K', 112 '58558': 'L', 113 '58433': 'M', 114 '58517': 'N', 115 '58387': 'O', 116 '58687': 'P', 117 '58537': 'Q', 118 '58541': 'R', 119 '58458': 'S', 120 '58390': 'T', 121 '58466': 'U', 122 '58386': 'V', 123 '58697': 'W', 124 '58519': 'X', 125 '58511': 'Y', 126 '58634': 'Z', 127 '58611': '的', 128 '58590': '一', 129 '58398': '是', 130 '58422': '了', 131 '58657': '我', 132 '58666': '不', 133 '58562': '人', 134 '58345': '在', 135 '58510': '他', 136 '58496': '有', 137 '58654': '这', 138 '58441': '个', 139 '58493': '上', 140 '58714': '们', 141 '58618': '来', 142 '58528': '到', 143 '58620': '时', 144 '58403': '大', 145 '58461': '地', 146 '58481': '为', 147 '58700': '子', 148 '58708': '中', 149 '58503': '你', 150 '58442': '说', 151 '58639': '生', 152 '58506': '国', 153 '58663': '年', 154 '58436': '着', 155 '58563': '就', 156 '58391': '那', 157 '58357': '和', 158 '58354': '要', 159 '58695': '她', 160 '58372': '出', 161 '58696': '也', 162 '58551': '得', 163 '58445': '里', 164 '58408': '后', 165 '58599': '自', 166 '58424': '以', 167 '58394': '会', 168 '58348': '家', 169 '58426': '可', 170 '58673': '下', 171 '58417': '而', 172 '58556': '过', 173 '58603': '天', 174 '58565': '去', 175 '58604': '能', 176 '58522': '对', 177 '58632': '小', 178 '58622': '多', 179 '58350': '然', 180 '58605': '于', 181 '58617': '心', 182 '58401': '学', 183 '58637': '么', 184 '58684': '之', 185 '58382': '都', 186 '58464': '好', 187 '58487': '看', 188 '58693': '起', 189 '58608': '发', 190 '58392': '当', 191 '58474': '没', 192 '58601': '成', 193 '58355': '只', 194 '58573': '如', 195 '58499': '事', 196 '58469': '把', 197 '58361': '还', 198 '58698': '用', 199 '58489': '第', 200 '58711': '样', 201 '58457': '道', 202 '58635': '想', 203 '58492': '作', 204 '58647': '种', 205 '58623': '开', 206 '58521': '美', 207 '58609': '总', 208 '58530': '从', 209 '58665': '无', 210 '58652': '情', 211 '58676': '己', 212 '58456': '面', 213 '58581': '最', 214 '58509': '女', 215 '58488': '但', 216 '58363': '现', 217 '58685': '前', 218 '58396': '些', 219 '58523': '所', 220 '58471': '同', 221 '58485': '日', 222 '58613': '手', 223 '58533': '又', 224 '58589': '行', 225 '58527': '意', 226 '58593': '动', 227 '58699': '方', 228 '58707': '期', 229 '58414': '它', 230 '58596': '头', 231 '58570': '经', 232 '58660': '长', 233 '58364': '儿', 234 '58526': '回', 235 '58501': '位', 236 '58638': '分', 237 '58404': '爱', 238 '58677': '老', 239 '58535': '因', 240 '58629': '很', 241 '58577': '给', 242 '58606': '名', 243 '58497': '法', 244 '58662': '间', 245 '58479': '斯', 246 '58532': '知', 247 '58380': '世', 248 '58385': '什', 249 '58405': '两', 250 '58644': '次', 251 '58578': '使', 252 '58505': '身', 253 '58564': '者', 254 '58412': '被', 255 '58686': '高', 256 '58624': '已', 257 '58667': '亲', 258 '58607': '其', 259 '58616': '进', 260 '58368': '此', 261 '58427': '话', 262 '58423': '常', 263 '58633': '与', 264 '58525': '活', 265 '58543': '正', 266 '58418': '感', 267 '58597': '见', 268 '58683': '明', 269 '58507': '问', 270 '58621': '力', 271 '58703': '理', 272 '58438': '尔', 273 '58536': '点', 274 '58384': '文', 275 '58484': '几', 276 '58539': '定', 277 '58554': '本', 278 '58421': '公', 279 '58347': '特', 280 '58569': '做', 281 '58710': '外', 282 '58574': '孩', 283 '58375': '相', 284 '58645': '西', 285 '58592': '果', 286 '58572': '走', 287 '58388': '将', 288 '58370': '月', 289 '58399': '十', 290 '58651': '实', 291 '58546': '向', 292 '58504': '声', 293 '58419': '车', 294 '58407': '全', 295 '58672': '信', 296 '58675': '重', 297 '58538': '三', 298 '58465': '机', 299 '58374': '工', 300 '58579': '物', 301 '58402': '气', 302 '58702': '每', 303 '58553': '并', 304 '58360': '别', 305 '58389': '真', 306 '58560': '打', 307 '58690': '太', 308 '58473': '新', 309 '58512': '比', 310 '58653': '才', 311 '58704': '便', 312 '58545': '夫', 313 '58641': '再', 314 '58475': '书', 315 '58583': '部', 316 '58472': '水', 317 '58478': '像', 318 '58664': '眼', 319 '58586': '等', 320 '58568': '体', 321 '58674': '却', 322 '58490': '加', 323 '58476': '电', 324 '58346': '主', 325 '58630': '界', 326 '58595': '门', 327 '58502': '利', 328 '58713': '海', 329 '58587': '受', 330 '58548': '听', 331 '58351': '表', 332 '58547': '德', 333 '58443': '少', 334 '58460': '克', 335 '58636': '代', 336 '58585': '员', 337 '58625': '许', 338 '58694': '稜', 339 '58428': '先', 340 '58640': '口', 341 '58628': '由', 342 '58612': '死', 343 '58446': '安', 344 '58468': '写', 345 '58410': '性', 346 '58508': '马', 347 '58594': '光', 348 '58483': '白', 349 '58544': '或', 350 '58495': '住', 351 '58450': '难', 352 '58643': '望', 353 '58486': '教', 354 '58406': '命', 355 '58447': '花', 356 '58669': '结', 357 '58415': '乐', 358 '58444': '色', 359 '58549': '更', 360 '58494': '拉', 361 '58409': '东', 362 '58658': '神', 363 '58557': '记', 364 '58602': '处', 365 '58559': '让', 366 '58610': '母', 367 '58513': '父', 368 '58500': '应', 369 '58378': '直', 370 '58680': '字', 371 '58352': '场', 372 '58383': '平', 373 '58454': '报', 374 '58671': '友', 375 '58668': '关', 376 '58452': '放', 377 '58627': '至', 378 '58400': '张', 379 '58455': '认', 380 '58416': '接', 381 '58552': '告', 382 '58614': '入', 383 '58582': '笑', 384 '58534': '内', 385 '58701': '英', 386 '58349': '军', 387 '58491': '候', 388 '58467': '民', 389 '58365': '岁', 390 '58598': '往', 391 '58425': '何', 392 '58462': '度', 393 '58420': '山', 394 '58661': '觉', 395 '58615': '路', 396 '58648': '带', 397 '58470': '万', 398 '58377': '男', 399 '58520': '边', 400 '58646': '风', 401 '58600': '解', 402 '58431': '叫', 403 '58715': '任', 404 '58524': '金', 405 '58439': '快', 406 '58566': '原', 407 '58477': '吃', 408 '58642': '妈', 409 '58437': '变', 410 '58411': '通', 411 '58451': '师', 412 '58395': '立', 413 '58369': '象', 414 '58706': '数', 415 '58705': '四', 416 '58379': '失', 417 '58567': '满', 418 '58373': '战', 419 '58448': '远', 420 '58659': '格', 421 '58434': '士', 422 '58679': '音', 423 '58432': '轻', 424 '58689': '目', 425 '58591': '条', 426 '58682': '呢' 427 } 428 for index in content: 429 try: 430 t1 = dict_data[str(ord(index))] 431 print(t1, end="") 432 except: 433 t1 = index 434 print(t1, end="")
最后执行结果如下:
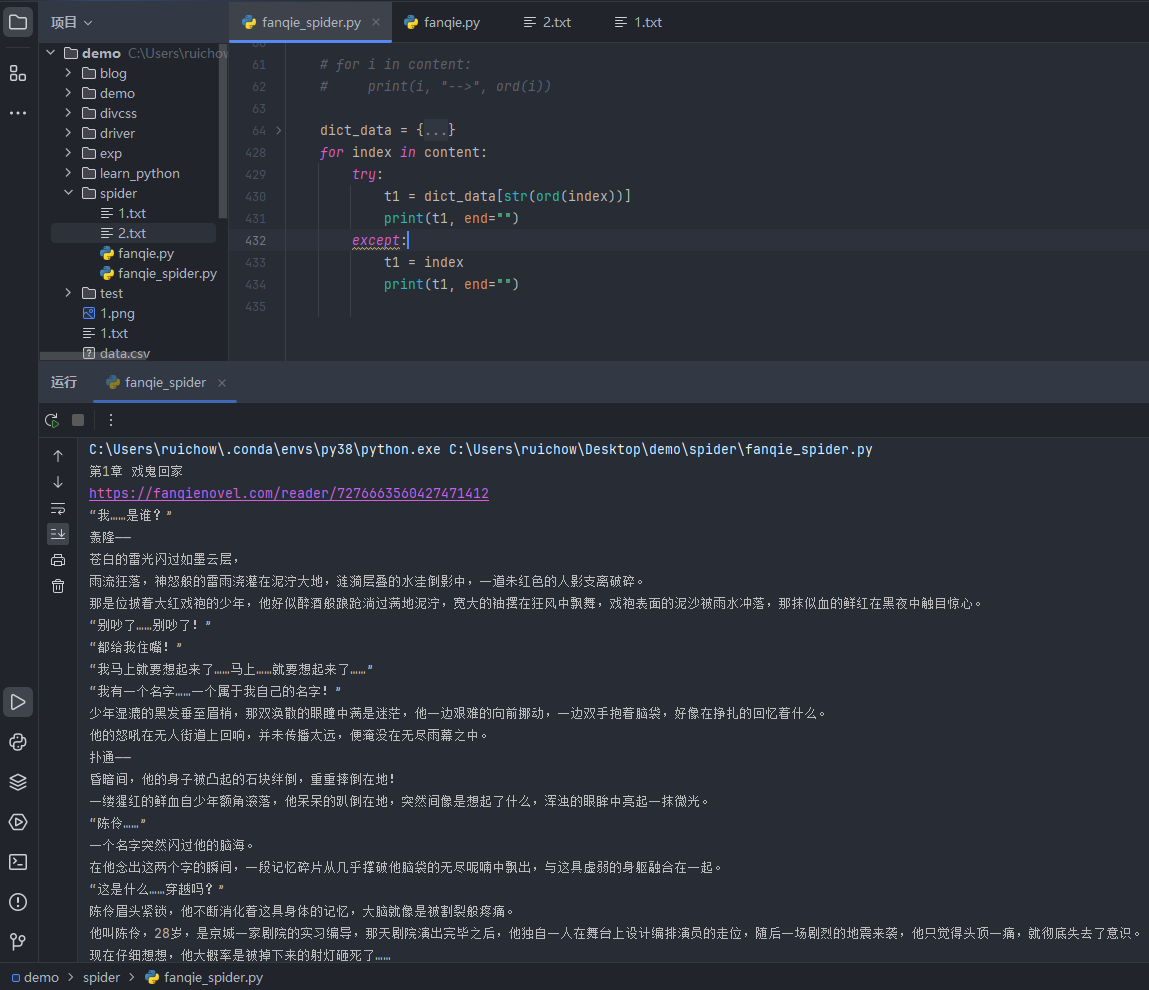

 浙公网安备 33010602011771号
浙公网安备 33010602011771号