
自动化工具DrissionPage
DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和 requests 的高效率。它功能强大,内置无数人性化设计和便捷功能。它的语法简洁而优雅,代码量少,对新手友好。
DrissionPage与selenium类似,但比selenium简单很多,不需要浏览器的驱动文件,可以直接使用。因此,尝试使用一下DrissionPage。
网页自动化
网页自动化的形式通常有两种,它们各有优劣:
- 直接向服务器发送数据包,获取需要的数据
- 控制浏览器跟网页进行交互
前者轻量级,速度快,便于多线程、分布式部署,如 requests 库。但当数据包构成复杂,甚至加入加密技术时,开发过程烧脑程度直线上升。
鉴于此,DrissionPage 以页面为单位将两者整合,对 Chromium 协议 和 requests 进行了重新封装,实现两种模式的互通,并加入常用的页面和元素控制功能,可大幅降低开发难度和代码量。
用于操作浏览器的对象叫 Driver,requests 用于管理连接的对象叫 Session,Drission 就是它们两者的合体。Page 表示以 POM 模式封装。 在旧版本,本库是通过对 selenium 和 requests 的重新封装实现的。
从 3.0 版开始,作者另起炉灶,用 chromium 协议自行实现了 selenium 全部功能,从而摆脱了对 selenium 的依赖,功能更多更强,运行效率更高,开发更灵活。
基本使用逻辑
无论是控制浏览器,还是收发数据包,其操作逻辑是一致的。
即先创建页面对象,然后从页面对象中获取元素对象,通过对元素对象的读取或操作,实现数据的获取或页面的控制。
因此,最主要的对象就是两种:页面对象,及其生成的元素对象。
主要对象
主页面对象有 3 种,它们通常是程序的入口:
ChromiumPage:单纯用于操作浏览器的页面对象WebPage:整合浏览器控制和收发数据包于一体的页面对象SessionPage:单纯用于收发数据包的页面对象
衍生物:
ChromiumTab:ChromiumPage生成的标签页对象WebPageTab:WebPage生成的标签页对象ChromiumFrame:<iframe>元素对象ChromiumElement:浏览器元素对象SessionElement:静态元素对象ShadowRoot:shadow-root 元素对象
称呼
文档里经常用到这几个称呼:
ChromiumPage、WebPage统称为 Page 对象ChromiumTab、WebPageTab统称为 Tab 对象- Page 对象、Tab 对象和
ChromiumFrame统称为页面对
工具安装DrissionPage,直接使用pip进行安装即可
pip install DrissionPage
尝试读取邮箱邮件信息
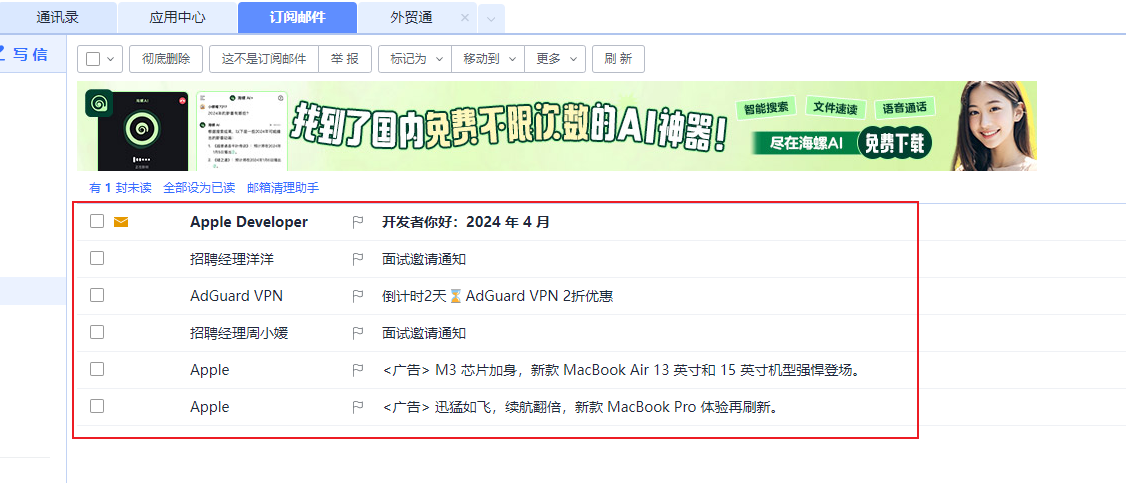
代码:
from DrissionPage import WebPage page = WebPage() # 登录邮箱 page.get("http://mail.163.com") page('mail').clear() page('mail').input("xxx") # 账户 page('#pwdtext').input("password") # 密码 page('#dologin').click() # 点击登录 # 等待加载 page.wait.load_start() # 进入订阅邮件栏 page('xpath:/html/body/div[1]/nav/div[2]/ul/li[9]/div').click() items = page('@class:tv0').eles('@class:nl0 hA0 ck0') while True: for item in items: print("发件人:"+item.ele('@class:gB0').text, "主题:"+item.ele('@class:da0').text) btn = page('下一页', timeout=2) if btn: btn.click() page.wait.load_start() else: break
运行截图
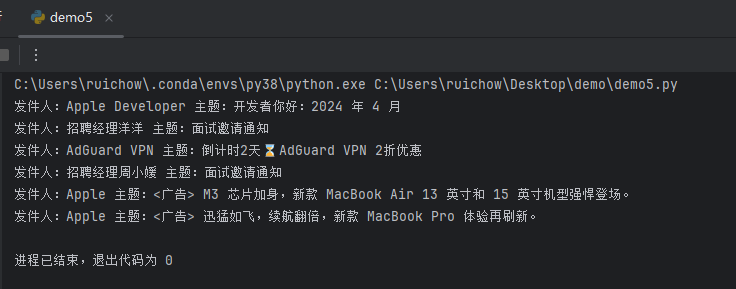
查看源码,了解一些基础内容
关键:页面元素定位
示例代码:
<html> <body> <div id="one"> <p class="p_cls" name="row1">第一行</p> <p class="p_cls" name="row2">第二行</p> <p class="p_cls">第三行</p> </div> <div id="two"> 第二个div </div> </body> </html>
用页面对象去获取其中的元素:
1 # 获取 id 为 one 的元素 2 div1 = page.ele('#one') 3 4 # 获取 name 属性为 row1 的元素 5 p1 = page.ele('@name=row1') 6 7 # 获取包含“第二个div”文本的元素 8 div2 = page.ele('第二个div') 9 10 # 获取所有div元素 11 div_list = page.eles('tag:div') 12 13 # 也可以获取到一个元素,然后在它里面或周围查找元素 14 # 获取到一个元素div1 15 div1 = page.ele('#one') 16 17 # 在div1内查找所有p元素 18 p_list = div1.eles('tag:p') 19 20 # 获取div1后面一个元素 21 div2 = div1.next()
页面元素查找语法
id 匹配符 #
表示id属性,只在语句最前面且单独使用时生效,可配合匹配模式使用。
1 # 在页面中查找id属性为one的元素 2 ele1 = page.ele('#one') 3 4 # 在ele1元素内查找id属性包含ne文本的元素 5 ele2 = ele1.ele('#:ne')
class 匹配符 .
表示class属性,只在语句最前面且单独使用时生效,可配合匹配模式使用。
1 # 查找class属性为p_cls的元素 2 ele2 = ele1.ele('.p_cls') 3 4 # 查找class属性'_cls'文本开头的元素 5 ele2 = ele1.ele('.^_cls')
因为只加 . 时默认是精确匹配元素属性 class,所以如果某元素有多个类名,必须写 class 属性的完整值(类名的顺序也不能变)。如果需要只匹配多个类名中的一个,可以使用模糊匹配符 :。
1 # 精确查找class属性为`p_cls1 p_cls2 `的元素 2 ele2 = ele1.ele('.p_cls1 p_cls2 ') 3 4 # 模糊查找class属性含有类名 'p_cls2' 的元素 5 ele2 = ele1.ele('.:p_cls2')
单属性匹配符 @
表示某个属性,只匹配一个属性。可单独使用,也可与tag配合使用。
@关键字只有一个简单功能,就是匹配@后面的内容,不再对后面的字符串进行解析。因此即使后面的字符串也存在@或@@ ,也作为要匹配的内容对待。所以只要是多属性匹配,包括第一个属性在内的所有属性都必须用@@开头。
如果属性中包含特殊字符(如包含@),用这个方式不能正确匹配到,需使用 css selector 方式查找。且特殊字符要用\转义。
1 # 查找name属性为row1的元素 2 ele2 = ele1.ele('@name=row1') 3 4 # 查找name属性包含row文本的元素 5 ele2 = ele1.ele('@name:row') 6 7 # 查找name属性以row开头的元素 8 ele2 = ele1.ele('@name^row') 9 10 # 查找有name属性的元素 11 ele2 = ele1.ele('@name') 12 13 # 查找没有任何属性的元素 14 ele2 = ele1.ele('@') 15 16 # 查找email属性为abc@def.com的元素,有多个@也不会重复处理 17 ele2 = ele1.ele('@email=abc@def.com') 18 19 # 属性中有特殊字符的情形,匹配abc@def属性等于v的元素 20 ele2 = ele1.ele('css:div[abc\@def="v"]')
多属性与匹配符 @@
匹配同时符合多个条件的元素时使用,每个条件前面添加@@作为开头。
可单独使用,也可与tag配合使用。
- 匹配文本或属性中出现@@、
@|、@!时,不能使用多属性匹配,需改用 xpath 的方式。 - 如果属性中包含特殊字符(如包含
@),用这个方式不能正确匹配到,需使用 css selector 方式查找。且特殊字符要用\转义。
# 查找name属性为row1且class属性包含cls文本的元素 ele2 = ele1.ele('@@name=row1@@class:cls')
@@可以与下文介绍的tag配合使用:
ele = page.ele('tag:div@@class=p_cls@@name=row1')
多属性或匹配符@|
匹配符合多个条件中任一项的元素时使用,每个条件前面添加@|作为开头。
可单独使用,也可与tag配合使用。
用法与@@一致,注意事项与@@一致。
@@和@|不能同时出现在语句中。
1 # 查找id属性为one或id属性为two的元素 2 ele2 = ele1.ele('@|id=one@|id=two')
@|可以与下文介绍的tag配合使用:
1 ele = page.ele('tag:div@|class=p_cls@|name=row1')
属性否定匹配符@!
用于否定某个条件,可与@@或@|混用,也可单独使用。
混用时,与还是或关系视@@还是@|而定。
示例:
# 匹配arg1等于abc且arg2不等于def的元素 page.ele('@@arg1=abc@!arg2=def') # 匹配arg1等于abc或arg2不等于def的div元素 page.ele('t:div@|arg1=abc@!arg2=def') # 匹配arg1不等于abc page.ele('@!arg1=abc') # 匹配没有arg1属性的元素 page.ele('@!arg1')
文本匹配符 text
要匹配的文本,查询字符串如开头没有任何关键字,也表示根据传入的文本作模糊查找。
如果元素内有多个直接的文本节点,精确查找时可匹配所有文本节点拼成的字符串,模糊查找时可匹配每个文本节点。
没有任何匹配符时,默认匹配文本。
如果要匹配的文本包含特殊字符(如' '、'>'),需将其转换为十六进制形式,详见《语法速查表》一节。
# 查找文本为“第二行”的元素 ele2 = ele1.ele('text=第二行') # 查找文本包含“第二”的元素 ele2 = ele1.ele('text:第二') # 与上一行一致 ele2 = ele1.ele('第二') # 匹配包含 文本的元素 ele2 = ele1.ele('第\u00A0二') # 需将 转为\u00A0
若要查找的文本包含text: ,可下面这样写,即第一个text: 为关键字,第二个是要查找的内容:
ele2 = page.ele('text:text:')
文本匹配符 text()
作为查找属性时使用的文本关键字,必须与@或@@配合使用。
text在作为属性查找条件是改为text(),是为了避免遇到名为text的属性时产生冲突。
# 查找文本为“第二行”的元素 ele2 = ele1.ele('@text()=第二行') # 查找文本包含“第二行”的元素 ele2 = ele1.ele('@text():二行') # 查找文本以“第二”开头且class属性为p_cls的元素 ele2 = ele1.ele('@@text()^第二@@class=p_cls') # 查找文本为“二行”且没有任何属性的元素(因第一个 @@ 后为空) ele2 = ele1.ele('@@@@text():二行') # 查找直接子文本包含“二行”字符串的元素 ele = page.ele('@text():二行')
@@text()的技巧
值得一提的是,text()配合@@或@|能实现一种很便利的按查找方式。
网页种经常会出现元素和文本混排的情况,比如:
<li class="explore-categories__item"> <a href="/explore/new-tech" class=""> <i class="explore"></i> 前沿技术 </a> </li> <li class="explore-categories__item"> <a href="/explore/program-develop" class=""> <i class="explore"></i> 程序开发 </a> </li>
示例中,如果要用文本获取'前沿技术'的<a>元素,可以这样写:
ele = page.ele('text:前沿技术') # 或 ele = page.ele('@text():前沿技术')
这两种写法都能获取到包含直接文本的元素。
但如果要用文本获取<li>元素,就获取不到,因为文本不是<li>的直接内容。
我们可以这样写:
ele = page.ele('tag:li@@text():前沿技术')
@@text()与@text()不同之处在于,前者可以搜索整个元素内所有文本,而不仅仅是直接文本,因此能实现一些非常灵活的查找。
需要注意的是,使用@@或@|时,text()不要作为唯一的查询条件,否则会定位到整个文档最高层的元素。
❌ 错误做法:
ele = page.ele('@@text():前沿技术') ele = page.ele('@|text():前沿技术@|text():程序开发')
⭕ 正确做法:
ele = page.ele('tag:li@|text():前沿技术@|text():程序开发')
类型匹配符 tag
表示元素的标签,只在语句最前面且单独使用时生效,可与@、@@或@|配合使用。tag:与tag=效果一致,没有tag^和tag$语法。
# 定位div元素 ele2 = ele1.ele('tag:div') # 定位class属性为p_cls的p元素 ele2 = ele1.ele('tag:p@class=p_cls') # 定位文本为"第二行"的p元素 ele2 = ele1.ele('tag:p@text()=第二行') # 定位class属性为p_cls且文本为“第二行”的p元素 ele2 = ele1.ele('tag:p@@class=p_cls@@text()=第二行') # 定位class属性为p_cls或文本为“第二行”的p元素 ele2 = ele1.ele('tag:p@|class=p_cls@|text()=第二行') # 查找直接文本节点包含“二行”字符串的p元素 ele2 = ele1.ele('tag:p@text():二行') # 查找内部文本节点包含“二行”字符串的p元素 ele2 = ele1.ele('tag:p@@text():二行')
tag:div@text():text 和 tag:div@@text():text 是有区别的,前者只在div的直接文本节点搜索,后者搜索div的整个内部。
css selector 匹配符 css
表示用 css selector 方式查找元素。css:与css=效果一致,没有css^和css$语法。
# 查找 div 元素 ele2 = ele1.ele('css:.div') # 查找 div 子元素元素,这个写法是本库特有,原生不支持 ele2 = ele1.ele('css:>div')
xpath 匹配符 xpath
表示用 xpath 方式查找元素。xpath:与xpath=效果一致,没有xpath^和xpath$语法。
另外,元素对象的ele()支持完整的 xpath 语法,如能使用 xpath 直接获取元素属性(字符串类型)。
# 查找后代中第一个 div 元素 ele2 = ele1.ele('xpath:.//div') # 和上面一行一样,查找元素的后代时,// 前面的 . 可以省略 ele2 = ele1.ele('xpath://div') # 使用xpath获取div元素的class属性(页面元素无此功能) ele_class_str = ele1.ele('xpath://div/@class')
查找元素的后代时,selenium 原生代码要求 xpath 前面必须加.,否则会变成在全个页面中查找。 作者觉得这个设计是画蛇添足,既然已经通过元素查找了,自然应该只查找这个元素内部的元素。 所以,用 xpath 在元素下查找时,最前面//或/前面的.可以省略。
selenium 的 loc 元组
查找方法能直接接收 selenium 原生定位元组进行查找,便于项目迁移。
from DrissionPage.common import By # 查找id为one的元素 loc1 = (By.ID, 'one') ele = page.ele(loc1) # 按 xpath 查找 loc2 = (By.XPATH, '//p[@class="p_cls"]') ele = page.ele(loc2)
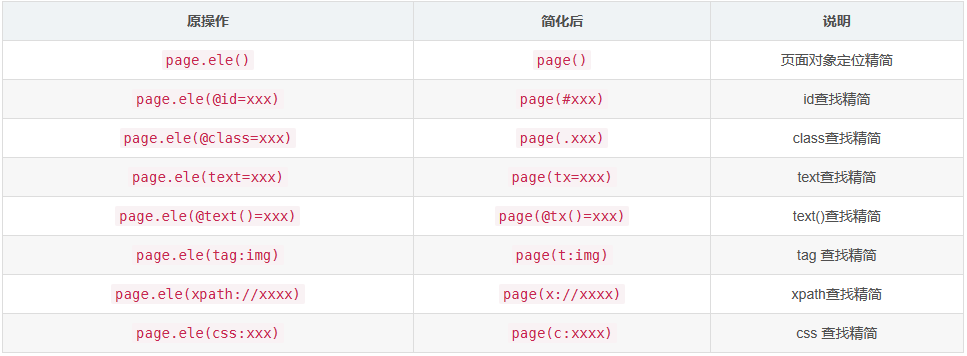
简化写法
定位符语法简化
- 定位语法都有其简化形式
- 页面和元素对象都实现了
__call__()方法,所以page.ele('...')可简化为page('...') - 查找方法都支持链式操作
示例:
# 查找tag为div的元素 ele = page.ele('tag:div') # 原写法 ele = page('t:div') # 简化写法 # 用xpath查找元素 ele = page.ele('xpath://xxxxx') # 原写法 ele = page('x://xxxxx') # 简化写法 # 查找text为'something'的元素 ele = page.ele('text=something') # 原写法 ele = page('tx=something') # 简化写法
简化写法对应列表
| 原写法 | 简化写法 | 说明 |
|---|---|---|
@id |
# |
表示 id 属性,简化写法只在语句最前面且单独使用时生效 |
@class |
. |
表示 class 属性,简化写法只在语句最前面且单独使用时生效 |
text |
tx |
按文本匹配 |
@text() |
@tx() |
按文本查找与 @ 或 @@ 配合使用时 |
tag |
t |
按标签类型匹配 |
xpath |
x |
用 xpath 方式查找元素 |
css |
c |
用 css selector 方式查找元素 |
详细内容,可参考:🌏 安装 | DrissionPage官网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号