基于Tesseract的OCR识别小程序
一、背景
先说下开发背景,今年有次搬家找房子(2020了应该叫去年了),发现每天都要对着各种租房广告打很多电话。(当然网上也找了实地也找),每次基本都是对着墙面看电话号码然后拨打,次数一多就感觉非常麻烦,如果没看清还容易输错一个号码。

图片来自于网络
当时就想现在OCR技术那么流行,为什么不能做个程序来解决这个问题。因为租房电话有部分还是手写号码,所以也要解决手写识别的问题。同时租房信息其实也有很多是中介或者其他诈骗类等等。所以有部分并不是我们所需要的,为什么这块信息就不能做个平台进行共享,类似于手机里面识别和提交诈骗电话一样。然后自己也搜索了下微信小程序里有没有类似的小程序,发现基本没有,有些OCR相关程序但是使用相对繁琐,并多数需要收费或开通会员等。
所以自己就想着还是自己来开发一个相关的小程序,功能简单,通过相机拍照获取电话号码,进行识别;可直接在里面调用电话进行拨号。同时允许提交该识别后的号码作为标记,标记成诈骗、中介等。当某个号码被人标记后,下次任何人再识别该号码后就能显示对应的标记信息。
二、核心问题
本次核心问题可能就是手写识别了,普通的打印文字识别。已经很常见也很成熟了。我们主要是识别数字,所以只针对数字手写识别。这些年第三方的例如BAT其实都有类似的服务接口提供,我也研究了下,对接很简单。识别率还算行,能够达到70%左右。毕竟手写每个人千差万别。但是第三方的终究都是要收费的,当然有一定的免费额度。我开发这个软件也没打算收费什么的,所以第三方的暂且放弃使用了。
MNIST机器学习
现在比较热门的都是基于机器学习的手写识别,机器学习框架有很多常用的比如TensorFlow ,在手写数字识别里面MNIST 数据集是最常用的,甚至流行到一般机器学习框架都使用MNIST 做入门教程了。关于MNIST我在这里不做具体介绍,有兴趣的可以自行上网了解。
然后我就网上找python机器学习手写数字识别之类的,学习了很久。最后感觉使用MNIST数据集做识别更多还是一种识别算法的比较。因为MNIST里本身就包含了样本和测试数据集。通过机器学习将样本的进行学习然后生成一个模型数据,然后根据模型数据去读取样本数据进行比较以此来查识别成功率。并且网上的案例基本都是类似,即根据数据集来学习和识别正确率。
我还找到了.NET Core使用ML.NET 基于MNIST数据集的手写数字识别,运行结果如下图所示。原理和过程和Python处理是一样的,包括输出结果。

MNIST数据集是每张均为28*28像素的黑白图片,并且是一个字符占用一张图片。我们平时OCR识别的时候都是一张图一起识别所有文字(数字)。所以如果使用MNIST我们必须要对图片文字(数字)进行精准分割再把图像进行二值化保存为20*28像素的。手写数字很多可能连载在一起,在此基础上做分割还是有一定难度。
所以这里暂时放弃使用了,后续抽时间会继续研究使用MNIST进行识别。
Tesseract
Tesseract 是一个相对于比较有名的开源OCR识别软件早期由惠普实验室开发,现在是由Google在开发和维护。支持的平台有Windows、linux、macos。支持的很多常用语言识别多达几十种;还可以自己训练文字库,如果使用手写识别所以需要自己去训练字库进行识别。
具体我就不过多阐述介绍了,感兴趣的自行了解。我本次开发就是选用的Tesseract进行识别。
GitHub: https://github.com/tesseract-ocr/tesseract
三、前端开发
本次前端使用的是微信小程序,小程序因为不用安装并且完全跨平台。自己不是专业前端开发,所以不过多介绍,只介绍小程序里如何使用相机拍照并且裁剪指定区域等。
1、拍照
相机拍照界面,因为只识别一个号码所以拍照区域不需要很大,如果单纯的把相机缩小又感觉很丑的样子。所以有点类似微信扫描那样的,需要的部分全亮其他部分半透明的效果。
如下图所示

一开始一直在想小程序的相机是否提供类似的功能,让我通过设置甚直接达到这样的效果。但是很可惜没找到,相机上面加文字图片都是可以的。其实这个一部分透明一般分半透明就是一个图片。整个背景是个图片,这也是自己想好了好久才想到的,然后自己通过PS把一张图做成透明和半透明的效果。
代码如下:
1 <camera device - position="width" flash="off" style="height:{{height}}px;"> 2 <cover-view class='camerabgImage-view'> 3 <cover-image class='bgImage' src='../images/bg2.png'> </cover-image> 4 <cover-view class='cameraTips'>请对准电话号码扫描</cover-view> 5 <cover-view class="cameraTips2">*支持打印和手写号码识别</cover-view> 6 <cover-view class="cameraBgView"> 7 <cover-image class='cancelphoto' src='../images/cancelPhoto2.png' bindtap='cancelPhoto'></cover-image> 8 <cover-view class='cameraButton-view'> 9 <cover-image class='takephoto' src='../images/takephoto.png' bindtap='takePhoto'></cover-image> 10 </cover-view> 11 </cover-view> 12 </cover-view> 13 </camera>
具体详细代码,请看文章结尾github地址。
2、裁剪
拍照界面实现了,下一步就是要实现拍照功能了,拍照代码简单,不做过多阐述。因为我们是要取完全透明的那一块区域的图像。也就是照片的指定位置,在拍照的api里面微信没有提供类似的获取指定区域图像的功能,所以我们要实现这功能就需要自己针对一个完整的图片信息进行裁剪。

如何截取这部分图像呢?目前我的做法是根据框框的位置去找出在整个图像中的位置即对应的X,Y。因为我们整个框框本来就是一张背景图的一部分,所以它在代码中是没有一个实际坐标位置的。我们需要将裁剪后的图像展示出来,所以在另个页面还需要一个canvas用来展示裁剪后的图像。
下面代码看到了我使用了延迟和出错重试机制,因为在实际真机测试中偶尔还是会出现canvasToTempFilePath 方法报错问题。原因就是在调用canvasToTempFilePath 前面需要绘制一个矩形框用于展示我们截取后的图片。但是canvas.draw()方法是异步的,这样就会导致前面还没绘制完下面canvasToTempFilePath方法报错。
裁剪主要代码如下:
1 canvasToTempFile: function() { 2 var that = this; 3 setTimeout(function() { 4 wx.canvasToTempFilePath({ // 裁剪对参数 5 canvasId: "image-canvas", 6 x: that.data.image_x, // 画布x轴起点 7 y: that.data.image_y, // 画布y轴起点 8 width: that.data.width, // 画布宽度 9 height: that.data.image_height, // 画布高度 10 destWidth: that.data.width, // 输出图片宽度 11 destHeight: that.data.image_height, // 输出图片高度 12 canvasId: 'image-canvas', 13 success: function(res) { 14 that.filePath = res.tempFilePath; 15 // 清除画布上在该矩形区域内的内容。 16 that.canvas.clearRect(0, 0, that.data.width, that.data.height); 17 that.canvas.drawImage(that.filePath, that.data.image_x, that.data.image_y, that.data.width - 20, that.data.image_height); 18 that.canvas.draw(); 19 wx.hideLoading(); 20 // 开始请求识别接口 21 that.startDiscern(res.tempFilePath); 22 // 开始获取标记类型 23 that.getMarkType(); 24 }, 25 fail: function(e) { 26 // console.log("出错了:" + e); 27 wx.hideLoading() 28 wx.showToast({ 29 title: '请稍后...', 30 icon: 'loading' 31 }) 32 // 出错后继续执行一次。 33 that.canvasToTempFile(); 34 } 35 }); 36 }, 1000); 37 }
具体详细代码,请看文章结尾github地址。
四 、Tesseract 训练字库
首先Tesseract为了提高识别效果,可以允许我们自己训练自己的字库。即当Tesseract识别不正确时我们对它进行人工矫正。或者当他完全无法识别时,我们可以自己去标记要被识别的文字坐标和正确的结果值。
使用的工具是jTessBoxEditor,使用之前需要安装Java。
1、图片转换成tif格式
训练样板必须为TIFF格式,所以第一步就是需要转成TIFF格式文件,同时对于多张图片是可以合并成一个TIFF文件格式。这样就能在一个文件里保存多个图片。在jTessBoxEditor 里Tools->Merge即可进行,选择多张图片即可。但是保存为TIFF文件是格式一定要注意是
[lang].[fontname].exp[num].tif
lang为语言名称(即自己训练后的语言名称),
fontname为字体名称,
num为序号,可自定义。
2、生成BOX文件
下一步生成BOX文件,这一步其实就是使用Tesseract做一个基本的识别,识别后会生成一个box文件,这个文件保存着识别结果和结果对应的坐标信息。
这一步一定要在电脑上安装tesseract,不然无法执行。
生成BOX文件命令(注意要在刚生成tif文件目录中)
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
3、jTessBoxEditor矫正错误并训练
打开jTessBoxEditor,选择Box Editor->Open 打开刚刚生成的tif文件所在目录。该目录必须包含上一步已经生成的box文件。选择打开的是tif图像文件,而不是box文件。
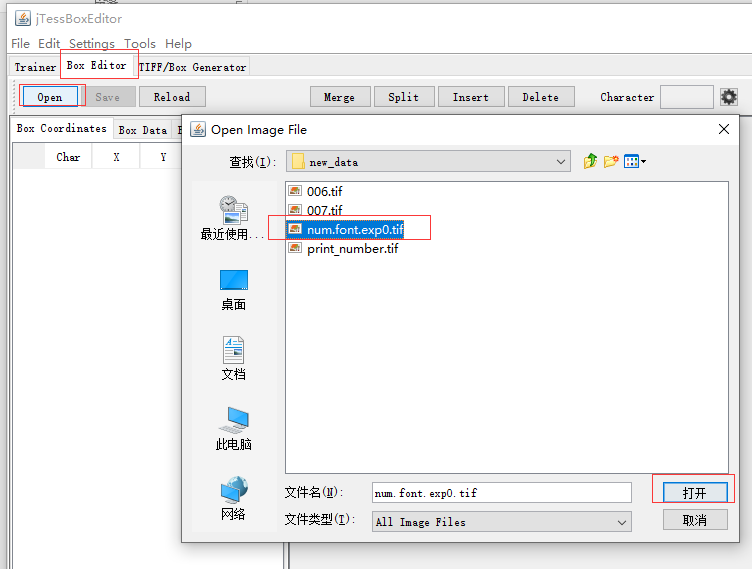
打开后会看到初步识别的结果,如果不对自行修改矫正。一个是修改坐标即蓝色框框对应的矩形位置,另个就是修改识别出来的字符。
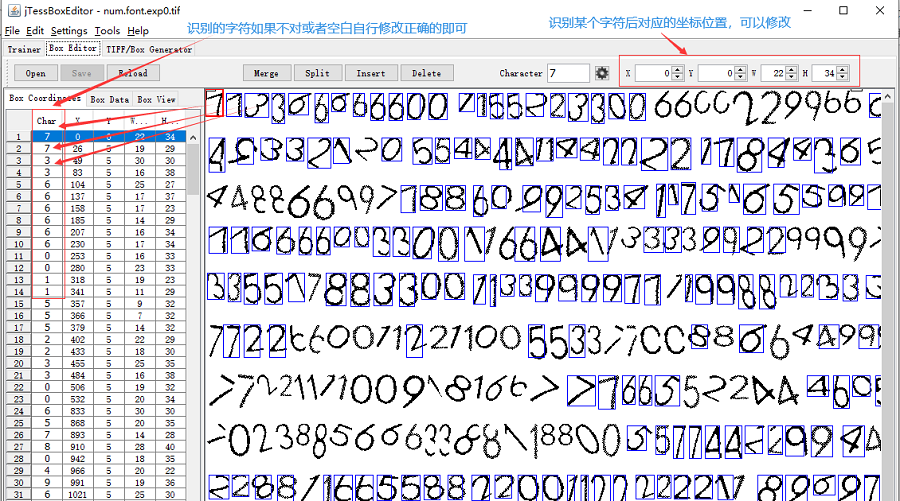
修改矫正完成后,按Ctrl+S 或者上面的Save按钮保存。
4、创建字体文件
创建一个文件名为font_properties的文件,放到同一个目录下,注意没有扩展名。
内容是:font 0 0 0 0 0
如下图

其中每个0对应的是各种字体。
分别为:
斜体,黑体,默认字体,衬线字体, 德文黑字体
0代表无1代表有
5、执行批处理
将下面代码复制到一个txt文件中放到相同目录下,修改扩展名为bat。
代码如下:
1 echo Run Tesseract for Training.. 2 tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train 3 4 echo Compute the Character Set.. 5 unicharset_extractor.exe num.font.exp0.box 6 mftraining -F font_properties -U unicharset - 7 O num.unicharset num.font.exp0.tr 8 9 10 echo Clustering.. 11 cntraining.exe num.font.exp0.tr 12 13 echo Rename Files.. 14 rename normproto num.normproto 15 rename inttemp num.inttemp 16 rename pffmtable num.pffmtable 17 rename shapetable num.shapetable 18 19 echo Create Tessdata.. 20 combine_tessdata.exe num. 21 22 echo. & pause
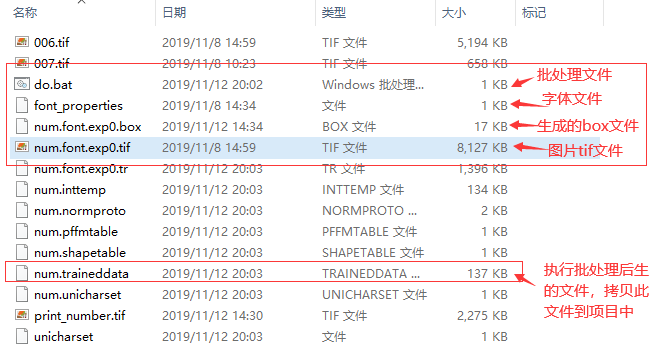
最后执行此批处理即可,执行后会生成很多文件,如下图,我们只需要拷贝目录下的num.traineddata文件到项目的tessdata目录中。
五、后端开发
后端这块主要使用.NET Core 写了一个webapi,小程序将拍照并截取后的图像转换成base64格式传入到后台,后台这边通过调用Tesserac进行识别。前面我提到能对识别的号码进行提交标记和获取标记等。所以后台这边目前使用的是MongoDB进行相关数据的存储和读取。
普通接口和MongoDB等操作很简单,这里不做介绍。主要说下Tesseract识别相关实现。
安装Tesseract依赖
Tesseract目前最新版本是4.1.0,
Nuget里面对应最新版是Genesis.Tesseract4。
所以下载时注意别下载错了。

Tesseract 提高识别率主要两个方面,第一个就是训练更多的相关字库,第二个就是图像的处理。图像这一块原图重要性最高,在我们这里就是用户拍摄图片,图片拍摄的清晰可见,文字后面没有其他干扰等最好。
在图像识别领域,图像处理最常用的就是灰度化、二值化、图像校正等。
灰度化
在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,说通俗点就是把图像处理成黑白图像。
C# 代码如下:
1 /// <summary> 2 /// 图像灰度化 3 /// </summary> 4 /// <param name="bmp"></param> 5 /// <returns></returns> 6 public static Bitmap ToGray(Bitmap bmp) 7 { 8 for (int i = 0; i < bmp.Width; i++) 9 { 10 for (int j = 0; j < bmp.Height; j++) 11 { 12 //获取该点的像素的RGB的颜色 13 Color color = bmp.GetPixel(i, j); 14 //利用公式计算灰度值 15 int gray = (int)(color.R * 0.3 + color.G * 0.59 + color.B * 0.11); 16 Color newColor = Color.FromArgb(gray, gray, gray); 17 bmp.SetPixel(i, j, newColor); 18 } 19 } 20 return bmp; 21 }
具体详细代码,请看文章结尾github地址。
二值化
二值化就是将大于某个值的像素点都修改为255,小于该值的修改为0
即0和1,其实是灰度图像的0~255的简版,0表示白色,1表示黑色
二值化里最重要的就是阈值的选取,一般分为固定阈值和自适应阈值。 比较常用的二值化方法则有:双峰法、P参数法、迭代法和OTSU法等。
c# 代码如下:
1 /// <summary> 2 /// 图像二值化(迭代法) 3 /// </summary> 4 /// <param name="bmp"></param> 5 /// <returns></returns> 6 public static Bitmap ToBinaryImage(Bitmap bmp) 7 { 8 int[] histogram = new int[256]; 9 int minGrayValue = 255, maxGrayValue = 0; 10 //求取直方图 11 for (int i = 0; i < bmp.Width; i++) 12 { 13 for (int j = 0; j < bmp.Height; j++) 14 { 15 Color pixelColor = bmp.GetPixel(i, j); 16 histogram[pixelColor.R]++; 17 if (pixelColor.R > maxGrayValue) maxGrayValue = pixelColor.R; 18 if (pixelColor.R < minGrayValue) minGrayValue = pixelColor.R; 19 } 20 } 21 //迭代计算阀值 22 int threshold = -1; 23 int newThreshold = (minGrayValue + maxGrayValue) / 2; 24 for (int iterationTimes = 0; threshold != newThreshold &&iterationTimes< 100; iterationTime 25 { 26 threshold = newThreshold; 27 int lP1 = 0; 28 int lP2 = 0; 29 int lS1 = 0; 30 int lS2 = 0; 31 //求两个区域的灰度的平均值 32 for (int i = minGrayValue; i < threshold; i++) 33 { 34 lP1 += histogram[i] * i; 35 lS1 += histogram[i]; 36 } 37 int mean1GrayValue = (lP1 / lS1); 38 for (int i = threshold + 1; i < maxGrayValue; i++) 39 { 40 lP2 += histogram[i] * i; 41 lS2 += histogram[i]; 42 } 43 int mean2GrayValue = (lP2 / lS2); 44 newThreshold = (mean1GrayValue + mean2GrayValue) / 2; 45 } 46 47 //计算二值化 48 for (int i = 0; i < bmp.Width; i++) 49 { 50 for (int j = 0; j < bmp.Height; j++) 51 { 52 Color pixelColor = bmp.GetPixel(i, j); 53 if (pixelColor.R > threshold) bmp.SetPixel(i, j, Color.FromArgb(255, 255, 255)); 54 else bmp.SetPixel(i, j, Color.FromArgb(0, 0, 0)); 55 } 56 } 57 return bmp; 58 }
具体详细代码,请看文章结尾github地址。
下图是我在这期间为了测试图像处理效果及对比写的一个工具。
灰度化

二值化

完整图像处理代码https://github.com/cfan1236/ImageManipulation
无论灰度和二值化,都是为了强化和突出要被识别的区域,比如文字。弱化背景和其他干扰项,在最后的测试实验中,发现并不是所有原图经过一系列的图像处理后都能得到更好的结果,有些图片不做任何处理反而结果会更好。
所以我在实际处理中,使用三个线程同时处理识别3种情况,第一个使用原图识别、第二个使用灰度化后识别、第三个使用二值化后识别。最后取识别结果最多的一个。
代码如下:
1 /// <summary> 2 /// 数字识别 3 /// </summary> 4 /// <param name="base64_image"></param> 5 /// <param name="image_url"></param> 6 /// <returns></returns> 7 public PhoneDiscernResult DiscernNumber(string base64_image, string image_url) 8 { 9 PhoneDiscernResult result = new PhoneDiscernResult(); 10 string imageFile = GetImageFileName(); 11 if (!string.IsNullOrEmpty(image_url)) 12 { 13 Utils.DownLoadWebImage(image_url, imageFile); 14 } 15 else 16 { 17 Utils.SaveBase64Image(base64_image, imageFile); 18 } 19 if (File.Exists(imageFile)) 20 { 21 string[] taskResult = new string[3]; 22 // 三个线程同时去处理执行 23 // 每个线程处理的图片都不一样 取结果最好的一个 24 Task[] tk = new Task[] { 25 Task.Factory.StartNew(()=> 26 { 27 // 原图识别 28 taskResult[0]=Discern(imageFile); 29 }), 30 Task.Factory.StartNew(()=> 31 { 32 // 灰度处理后识别 33 taskResult[1]=GrayDiscern(imageFile); 34 }), 35 Task.Factory.StartNew(()=> 36 { 37 // 二值化处理后识别 38 taskResult[2]=BinaryzationDiscern(imageFile); 39 }), 40 }; 41 // 超时1分钟 42 int timeout = (1000 * 60) * 1; 43 Task.WaitAll(tk, timeout); 44 var number_str = taskResult[0]; 45 if (taskResult[1].Length > number_str.Length) 46 { 47 number_str = taskResult[1]; 48 } 49 if (taskResult[2].Length > number_str.Length) 50 { 51 number_str = taskResult[2]; 52 } 53 result.text = number_str; 54 if (number_str.Length == 11) 55 { 56 result.message = "识别成功"; 57 } 58 else 59 { 60 result.message = "当前识别的电话可能有误,请注意辨别"; 61 } 62 63 } 64 return result; 65 } 66 67 68 /// <summary> 69 /// 直接识别 70 /// </summary> 71 /// <param name="filePath"></param> 72 /// <returns></returns> 73 private string Discern(string imageFile) 74 { 75 string number_str = ""; 76 // 这里可以选择不同的语言包 可以是自己训练的 可以是Tesseract 训练好的语言包 77 TesseractEngine te_ocr = new TesseractEngine(@"tessdata", "chi_sim", EngineMode.TesseractAndLstm); 78 var img = Pix.LoadFromFile(imageFile); 79 var page = te_ocr.Process(img, PageSegMode.Auto); 80 string text = page.GetText().Trim().Replace("\r", "").Replace("\n", ""); 81 _logger.Info("识别的原始数据:"+text); 82 page.Dispose(); 83 // 只提取数字 84 number_str = System.Text.RegularExpressions.Regex.Replace(text, @"[^0-9]+", ""); 85 _logger.Info("只提取数字结果:" + number_str); 86 return number_str; 87 } 88 89 /// <summary> 90 /// 灰度识别 91 /// </summary> 92 /// <param name="imageFile"></param> 93 /// <returns></returns> 94 private string GrayDiscern(string imageFile) 95 { 96 string number_str = ""; 97 using (Bitmap bmp = new Bitmap(imageFile)) 98 { 99 // 灰度处理 100 var bmps = Utils.ToGray(bmp); 101 var tempFile = GetImageFileName(1); 102 bmps.Save(tempFile); 103 number_str = Discern(tempFile); 104 File.Delete(tempFile); 105 } 106 return number_str; 107 } 108 /// <summary> 109 /// 二值化识别 110 /// </summary> 111 /// <param name="imageFile"></param> 112 /// <returns></returns> 113 private string BinaryzationDiscern(string imageFile) 114 { 115 string number_str = ""; 116 using (Bitmap bmp = new Bitmap(imageFile)) 117 { 118 // 灰度处理 119 var bmps = Utils.ToGray(bmp); 120 // 处理自动校正 121 gmseDeskew sk = new gmseDeskew(bmps); 122 double skewangle = sk.GetSkewAngle(); 123 Bitmap bmpOut = Utils.RotateImage(bmps, -skewangle); 124 var tempFile = GetImageFileName(1); 125 // 将二值化后的图像保存下 126 Utils.ToBinaryImage(bmpOut).Save(tempFile); 127 number_str = Discern(tempFile); 128 File.Delete(tempFile); 129 } 130 return number_str; 131 }
具体详细代码,请看文章结尾github地址。
六、Linux上运行Tesseract
由于使用的是.NET Core开发的,所以最理想的运行环境自然是Linux了。但是当把项目直接发布到Linux上,是会报错的。所以在Linux上还是需要做一些安装和配置的。
第一步我们需要在Linux上安装Tesseract
首先Tesseract在github上有Linux平台的安装简介https://github.com/tesseract-ocr/tesseract/wiki
我是Centos安装命令如下:
yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/ScientificLinux_7/
// 更新
yum update
// 安装tesseract
yum install tesseract
yum install tesseract-langpack-deu
// 如果提示Public key for leptonica-1.76.0-2.2.x86_64.rpm is not installed证明未通过gpg密钥检查所以在安装时加上—nogpgcheck
yum install tesseract-langpack-deu –nogpgcheck
//安装完成 查看版本
tesseract --version
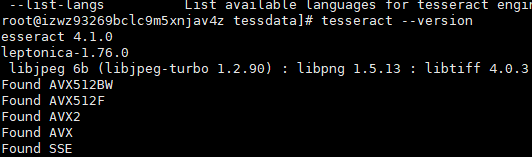
这是最新版4.1.0。这个版本最好和自己项目中的版本匹配。
切换到项目发布的目录再进入x64 (64位系统选择此目录)目录然后做映射。
映射哪些文件主要是看我们发布后X64里面的dll文件叫什么,比如我们发现是libtesseract400.dll 和libtesseract400.dll 。不同版本可能后面的数字不一样。
然后我们找到刚刚安装Tesseract的目录然后搜索libtesseract和libtesseract开头的so文件即可。最后我们会找到libtesseract.so.4.0.1.so、liblept.so.5.0.3.so文件。然后将这两个文件做映射,映射到我们项目目录中的名称需要和本身项目中dll文件一致,只是后缀为so,不再是dll了。
映射命令如下
ln -s /usr/lib64/libtesseract.so.4.0.1 libtesseract400.so
ln -s /usr/lib64/liblept.so.5.0.3 liblept1760.so
注意这些dll或者so后面的版本号即数字不同版本不同时期可能都不一样,以自己安装的为准。
映射完毕后查看项目目录x64目录如下

也可以通过ftp来查看目录结构。下面箭头状的就是映射的,文件本身不在此目录。有点类似如桌面快捷方式一样。
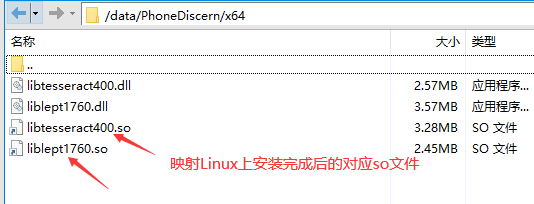
完成以上配置即可在Linux上完成Tesseract识别了。当然如果运行在Windows上,是不要安装Tesseract即可识别的。
小程序也早已上线,感兴趣的可以体验和提相关建议。名称叫做:手机号码识别
小程序二维码

完整项目代码
前端代码:
https://github.com/cfan1236/PhoneDiscern_wxapp
后端代码
https://github.com/cfan1236/PhoneDiscern

