
第一次个人作业报告
软工第一次个人作业博客(一)
作业要求:http://www.cnblogs.com/denghp83/p/8627840.html
思路分析
首先,这个作业就是做一个文件夹的迭代遍历,然后对每个文件进行处理,处理结果包括三个部分:总字数,总词数,总行数,单词出现频率前十名,词组出现频率前十名。这五项应该存在全局变量,对每个文件的处理放置在一个函数中,所以我决定先写文件的遍历,然后填充文件的处理过程。
PSP
| 进度规划 | 计划用时计划用时 | 实际用时 | 备注 |
|---|---|---|---|
| 实现文件迭代遍历 | 2hour | 2hour | 以前没有写过这种,搜索和学习相关的数据结构的用法花了较长时间, |
| 统计字符总数、总行数 | 30min | 大概也就20min | 这一步比较简单 |
| 统计单词总数目 | 0.5hour | 1.5hour | 晚上写的,熬夜效率不高,判断是否为单词的步骤花了时间较多,而且第一次还写的不太对,后来改了 |
| 统计各个单词的数量 | 0.5hour | 45min | 这里就是学习unordered_map怎么用占时间,这里没用几行代码 |
| 统计各个词组的数量 | 20min | 20min | 和统计各个单词数量差不多,很快完成 |
| 排序输出前十个单词和词组 | 120min | 45min | 选择一个好的算法很重要,刚开始想直接把所有的单词和词组排序,后来换成了用十一个缓冲区来选择 |
| 代码优化 | 220min | 200min | 已经远超过120min了。。。当然到目前为止优化效果很显著,没有明显的可优化的地方了 |
| Linux的问题 | 120min | 80min | 已经花了50min写了一个能在Linux上跑的程序,就是把遍历文件夹的函数从新写一个就好了,接口改一下,可见低耦合的好处! |
| 输入文件名以命令行参数传入。需要遍历整个文件夹时,则要输入文件夹的路径。 | 15min | 10min | |
| 根据命令行参数判断是否为目录 | 15min | 5min | |
| 收尾工作,测试细节 | 60min | 30min | 现在虽然已经优化了很长时间了,但是前三个的总数和词组的大小写一直和答案不一样,规则的细节还得细细品味 |
附:
博客要求
- 需求分析,估计各部分所需时间,给出PSP表格
- 记录实际完成各部分时间
- 对代码质量和性能进行分析
- 测试用例设计和分析过程
- 描述你在次项目中获得的经验
实现过程
文件遍历
我采用了文件的深度优先遍历,刚开始写是在Windows10下的visual studio2017下写的,查了一下发现Windows下的文件遍历可以用_finddata_t这个数据结构这个数据结构的详细内容如下:
1 struct _finddata_t
2 {
3 unsigned attrib; //文件属性
4 time_t time_create; //文件创建时间
5 time_t time_access; //文件上一次访问时间
6 time_t time_write; //文件上一次修改时间
7 _fsize_t size; //文件字节数
8 char name[_MAX_FNAME]; //文件名
9 };
网上也有很多深度遍历文件夹的代码,参考后修改一些,写出了文件夹的深度优先遍历函数,很简单,如下:
1 //深度优先递归遍历当前目录下文件夹和文件及子文件夹和文件
2 void DfsFolder(string path, int layer)
3 {
4 _finddata_t file_info;
5 string current_path = path + "/*.*"; //也可以用/*来匹配所有
6 intptr_t handle = _findfirst(current_path.c_str(), &file_info);
7 //返回值为-1则查找失败
8 if (-1 == handle)
9 {
10 cout << "cannot match the path" << endl;
11 return;
12 }
13
14 do
15 {
16 //判断是否子目录
17 if (file_info.attrib == _A_SUBDIR)
18 {
19 //递归遍历子目录
20
21 int layer_tmp = layer;
22 if (strcmp(file_info.name, "..") != 0 && strcmp(file_info.name, ".") != 0) //.是当前目录,..是上层目录,必须排除掉这两种情况
23 DfsFolder(path + '/' + file_info.name, layer_tmp + 1); //再windows下可以用\\转义分隔符,不推荐
24 }
25 else
26 {
27 //打印记号反映出深度层次
28 //for (int i = 0; i<layer; i++)
29 // cout << "--";
30 //cout << file_info.name << endl;
31 //这几行用来测试这个函数
32 string filename = file_info.name;
33 string suffixStr = filename.substr(filename.find_last_of('.') + 1);//获取文件后缀
34 NumOfCharsLinesInFile(path + '/' + file_info.name);
35 }
36 } while (!_findnext(handle, &file_info)); //返回0则遍历完
37 //关闭文件句柄
38 _findclose(handle);
39 }
当时说还要将文件的类型筛选一下,于是我当时先写了
string suffixStr = filename.substr(filename.find_last_of('.') + 1);//获取文件后缀
来得到文件的后缀,用来以后筛选指定类型的文件,可是现在的要求好像是说不用了。
其中 NumOfCharsLinesInFile 这个函数是处理文件的函数,当时想这个函数只用来统计文件的字数行数和词数,后来五项统计都写在了这个函数里,现在看来名字不太好,可以考虑后面改一下。
这几行当时是用来测试这个深度优先遍历文件夹的函数的。测试了好多文件,结果正确。
文件处理
文件处理的前三个(统计总字数、词数、行数)比较简单,我就先在函数里写了这三部分的功能,把后两个功能(统计出现次数最高的前十个单词、词组)再单独放在了一个函数EnterMap里。想要统计三个总数,开个全局变量比较方便:
1 long long TotalNum_chars = 0;
2 long long TotalNum_lines = 0;
3 long long TotalNum_words = 0;
然后开始写这个统计函数
首先要判断单词的方法:
1 for(int i = 0;i<len;i++)
2 {
3 current_char = buf[i];
4 if (current_char == '\n') {
5 NumberLines++;
6 }
7 if (current_char < 32 || current_char>126)
8 {
9 current_char = ' ';
10 TotalNum_chars--;
11 }
12 //判断是否为单词
13 if ((!isalpha(last_char)) && (!isdigit(last_char)) && (isalpha(current_char)))
14 {
15 wordbegin = true;
16 current_word = current_char;
17 }
18 else if (wordbegin)
19 {
20 if ((isalpha(current_char)) || (isdigit(current_char)))
21 {
22 //current_word.push_back(current_char);
23 current_word.push_back(current_char);
24 if (i == len-1) {
25 goto panduan;
26 }
27 }
28 else
29 {
30 panduan: wordbegin = false;
31 //Determines whether the current current word meets the word requirement: the first four characters are all letters
32 if (isalpha(current_word[1]) && isalpha(current_word[2]) && isalpha(current_word[3]))
33 {
34
35 //that current_word meets the requirements
36 NumberWords++;
37 EnterMap(last_word, current_word);
38 last_word = current_word; //NumberWords++,word,last_word=current_word
39 current_word.clear();
40
41 }
42 }
43 }
44 last_char = current_char;
45 }
我是用到了上一个字符和目前的字符,并且设置了一个 wordbegin 变量来表示是否在读单词,只要是间隔符和字母在一起,就读入,读入的单词再通过前四个 char 是不是都是字母来判断是不是单词。
除了单词数,其余比较简单,不再陈述。
整体的统计单独文件的函数如下
1 void NumOfCharsLinesInFile(string FileLocation)
2 {//Read the file, count the number of characters, lines, and words, and add it to the global variable. The word is processed and added to the map dictionary.
3 //int NumberChars = 0;
4 int NumberLines = 1;
5 int NumberWords = 0;
6 char last_char = ' ';
7 char current_char;
8 bool wordbegin = false;
9 string current_word;
10 string last_word;
11
12 size_t sz;
13 FILE * fp = fopen(FileLocation.c_str(), "rb");
14 fseek(fp, 0L, SEEK_END);
15 sz = ftell(fp); //
16
17 rewind(fp);
18 char*buf;
19 buf = (char*)malloc(sz * sizeof(char));
20 int len = fread(buf, sizeof(char), sz, fp);//用来读文件,经过测试,fread是最快的读文件方式
21 //if (len) {
22 // NumberLines++;
23 //}
24
25 for(int i = 0;i<len;i++)
26 {
27 current_char = buf[i];
28 if (current_char == '\n') {
29 NumberLines++;
30 }
31 if (current_char < 32 || current_char>126)
32 {
33 current_char = ' ';
34 TotalNum_chars--;
35 }
36 //判断是否为单词
37 if ((!isalpha(last_char)) && (!isdigit(last_char)) && (isalpha(current_char)))
38 {
39 wordbegin = true;
40 current_word = current_char;
41 }
42 else if (wordbegin)
43 {
44 if ((isalpha(current_char)) || (isdigit(current_char)))
45 {
46 //current_word.push_back(current_char);
47 current_word.push_back(current_char);
48 if (i == len-1) {
49 goto panduan;
50 }
51 }
52 else
53 {
54 panduan: wordbegin = false;
55 //Determines whether the current current word meets the word requirement: the first four characters are all letters
56 if (isalpha(current_word[1]) && isalpha(current_word[2]) && isalpha(current_word[3]))
57 {
58
59 //that current_word meets the requirements
60 NumberWords++;
61 EnterMap(last_word, current_word);
62 last_word = current_word; //NumberWords++,word,last_word=current_word
63 current_word.clear();
64
65 }
66 }
67 }
68 last_char = current_char;
69 }
70
71 free(buf);
72
73
74 TotalNum_chars += sz;
75 TotalNum_lines += NumberLines;
76 TotalNum_words += NumberWords;
77 fclose(fp);
78 fp = NULL;
79 }
统计单词词组的频率
这里用到了 unordered_map 这个关联容器,用法很简单,详见C++primer 。
还有就是这两个 map 的定义:
1 struct my_word
2 {
3 string sort_word = "zzzzzzzzzzzzzzzzzz";
4 size_t appear_count = 0;
5 };
6 unordered_map<string, my_word>word_count;
7 unordered_map<string, size_t>phrase_count;
其中 my_word 的 sort_word 是用来存字典序排最前面的格式, appear_count 用来存单词出现的数量。
void EnterMap(string last_word, string current_word)
{
string simple_last_word;
string simple_current_word;
size_t len = last_word.length();
string temp_word = last_word;
transform(temp_word.begin(), temp_word.end(), temp_word.begin(), ::tolower);
bool is_start = false;
for (size_t i = len - 1; i >= 0; i--)
{
if (isalpha(temp_word[i]))
{
is_start = true;
simple_last_word = temp_word.substr(0, i + 1);
break;
}
}
len = current_word.length();
temp_word = current_word;
transform(temp_word.begin(), temp_word.end(), temp_word.begin(), ::tolower);
is_start = false;
for (size_t i = len - 1; i >= 0; i--)
{
if (isalpha(temp_word[i]))
{
is_start = true;
simple_current_word = temp_word.substr(0, i + 1);
break;
}
}
unordered_map<string, my_word> ::iterator got = word_count.find(simple_current_word);
if (got == word_count.end())
{
word_count.insert({ simple_current_word,{current_word,1} });
}
else
{
got->second.appear_count++;
if (current_word<got->second.sort_word)
{
got->second.sort_word = current_word;
}
}
string simple_phrase = simple_last_word + '_' + simple_current_word;
phrase_count[simple_phrase]++;
}
最后关键的就是怎么排出前十个
排单词和排词组几乎是一样的,之说怎么排单词
开一个11个元素的 my_word 数组作为全局变量
my_word ten_word[11];
然后遍历 word_count ,每个都放入数组的第十一个,然后对这个数组进行一遍冒泡,使得第11个事最小的,然后最后就能筛选出出现次数最多的十个 my_word 。下面事代码。
1 void Getten_word() {
2
3 my_word temporary_word;
4 for (const auto &w : word_count)
5 {
6 ten_word[10] = w.second;
7 for (int i = 0; i <= 9; i++)
8 {
9 if (ten_word[i].appear_count < ten_word[i + 1].appear_count)
10 {
11 temporary_word = ten_word[i];
12 ten_word[i] = ten_word[i + 1];
13 ten_word[i + 1] = temporary_word;
14 }
15 }
16 }
17 sort(ten_word, ten_word + 10, compare);
18 }
19
20 void Getten_phrase()
21 {
22 my_phrase temporary_phrase;
23 for (const auto &w : phrase_count)
24 {
25 ten_phrase[10].appear_count = w.second;
26 ten_phrase[10].sort_phrase = w.first;
27 for (int i = 0; i <= 9; i++)
28 {
29 if (ten_phrase[i].appear_count < ten_phrase[i + 1].appear_count)
30 {
31 temporary_phrase = ten_phrase[i];
32 ten_phrase[i] = ten_phrase[i + 1];
33 ten_phrase[i + 1] = temporary_phrase;
34 }
35 }
36 }
37 sort(ten_phrase, ten_phrase + 10, phrase_compare);
38 }
39
40 bool compare(my_word a, my_word b)
41 {
42 return a.appear_count>b.appear_count; //升序排列
43 }
44
45 bool phrase_compare(my_phrase a, my_phrase b)
46 {
47 return a.appear_count>b.appear_count; //升序排列
48 }
现在就可以输出了
写 main 函数:
1 int main(int argc, char *argv[])
2 {
3 clock_t tStart = clock();
4 int state = DfsFolder("C:/newsample", 0);
5 if (state)
6 {
7 return 0;
8 }
9 cout << "char_number :" << TotalNum_chars << endl;
10 cout << "line_number :" << TotalNum_lines << endl;
11 cout << "word_number :" << TotalNum_words << endl;
12 Getten_word();
13 cout <<endl<< "the top ten frequency of word : " << endl;
14 for (int i = 0; i < 10; i++)
15 {
16 cout << ten_word[i].sort_word << " " << ten_word[i].appear_count << endl;
17
18 }
19 Getten_phrase();
20 cout <<"\n\n"<< "the top ten frequency of phrase :" << endl;
21 for (int i = 0; i < 10; i++)
22 {
23 string phrase_now = ten_phrase[i].sort_phrase;
24 string temp1, temp2;
25 int x = phrase_now.length();
26 int k = phrase_now.find("_");
27
28 //temp1 = phrase_now.substr(0, k);
29 //temp2 = phrase_now.substr(k + 1, x - k - 1);
30 string xx = phrase_now.substr(0, k);
31 cout << word_count[phrase_now.substr(0, k)].sort_word << ' ' << word_count[phrase_now.substr(k + 1, x - k - 1)].sort_word <<" "<< ten_phrase[i].appear_count << endl;
32 }
33 printf("Time taken: %.2fs\n", (double)(clock() - tStart) / CLOCKS_PER_SEC);
34 return 0;
35 }
于是就任务基本完成了。
总的代码
#include <iostream>
#include <string>
#include <fstream>
#include <io.h>
#include<ctype.h>
#include <algorithm>
#include <unordered_map>
#include <time.h>
using namespace std;
long long TotalNum_chars = 0;
long long TotalNum_lines = 0;
long long TotalNum_words = 0;
struct my_word
{
string sort_word = "zzzzzzzzzzzzzzzzzz";
size_t appear_count = 0;
};
my_word ten_word[11];
struct my_phrase
{
string sort_phrase = "zzzzzzzzzzzzzzzzzz";
size_t appear_count = 0;
};
my_phrase ten_phrase[11];
unordered_map<string, my_word>word_count;
unordered_map<string, my_phrase>phrase_count;
string transform_word(string raw_word)
{
size_t len = raw_word.length();
string simple_word;
string temp_word = raw_word;
transform(temp_word.begin(), temp_word.end(), temp_word.begin(), ::tolower);
bool is_start = false;
for (int i = len - 1; i >= 0; i--)
{
if (isalpha(temp_word[i]))
{
is_start = true;
simple_word = temp_word.substr(0, i + 1);
break;
}
}
return simple_word;
}
void EnterMap(string last_word, string current_word)
{
string simple_last_word;
string simple_current_word;
size_t len = last_word.length();
string temp_word = last_word;
transform(temp_word.begin(), temp_word.end(), temp_word.begin(), ::tolower);
bool is_start = false;
for (size_t i = len - 1; i >= 0; i--)
{
if (isalpha(temp_word[i]))
{
is_start = true;
simple_last_word = temp_word.substr(0, i + 1);
break;
}
}
len = current_word.length();
temp_word = current_word;
transform(temp_word.begin(), temp_word.end(), temp_word.begin(), ::tolower);
is_start = false;
for (size_t i = len - 1; i >= 0; i--)
{
if (isalpha(temp_word[i]))
{
is_start = true;
simple_current_word = temp_word.substr(0, i + 1);
break;
}
}
unordered_map<string, my_word> ::iterator got = word_count.find(simple_current_word);
if (got == word_count.end())
{
word_count.insert({ simple_current_word,{current_word,1} });
}
else
{
got->second.appear_count++;
if (current_word<got->second.sort_word)
{
got->second.sort_word = current_word;
}
}
string simple_phrase = simple_last_word + '_' + simple_current_word;
string raw_phrase = last_word + '_' + current_word;
unordered_map<string, my_phrase> ::iterator got_phrase = phrase_count.find(simple_phrase);
if (got_phrase == phrase_count.end())
{
phrase_count.insert({ simple_phrase,{raw_phrase,1} });
}
else
{
got_phrase->second.appear_count++;
if (raw_phrase < got_phrase->second.sort_phrase)
{
got_phrase->second.sort_phrase = raw_phrase;
}
}
}
void NumOfCharsLinesInFile(string FileLocation)
{//读入文件,统计字符数、行数、单词数,并加入到全局变量中。并对单词进行处理,加入map字典中。
//int NumberChars = 0;
int NumberLines = 1;
int NumberWords = 0;
char last_char = ' ';
char current_char;
bool wordbegin = false;
string current_word;
string last_word;
size_t sz;
FILE * fp = fopen(FileLocation.c_str(), "rb");
fseek(fp, 0L, SEEK_END);
sz = ftell(fp);
rewind(fp);
char*buf;
buf = (char*)malloc(sz * sizeof(char));
int len = fread(buf, sizeof(char), sz, fp);
//if (len) {
// NumberLines++;
//}
for(int i = 0;i<len;i++)
{
current_char = buf[i];
if (current_char == '\n') {
NumberLines++;
}
if (current_char < 32 || current_char>126)
{
current_char = ' ';
TotalNum_chars--;
}
//判断是否为单词
if ((!isalpha(last_char)) && (!isdigit(last_char)) && (isalpha(current_char)))
{
wordbegin = true;
current_word = current_char;
}
else if (wordbegin)
{
if ((isalpha(current_char)) || (isdigit(current_char)))
{
//current_word.push_back(current_char);
current_word.push_back(current_char);
if (i == len-1) {
goto panduan;
}
}
else
{
panduan: wordbegin = false;
//判断现在的current_word是否满足word的要求:前四个字符都是字母
if (isalpha(current_word[1]) && isalpha(current_word[2]) && isalpha(current_word[3]))
{
//说明current_word满足要求
NumberWords++;
EnterMap(last_word, current_word);
last_word = current_word; //如果满足word要求,则将NumberWords++,并处理该word,并last_word=current_word
current_word.clear(); //将current_word清空
}
}
}
//判断是否为单词结束
last_char = current_char;
}
free(buf);
TotalNum_chars += sz;
TotalNum_lines += NumberLines;
TotalNum_words += NumberWords;
fclose(fp);
fp = NULL;
//
}
//深度优先递归遍历当前目录下文件夹和文件及子文件夹和文件
void DfsFolder(string path, int layer)
{
_finddata_t file_info;
string current_path = path + "/*.*"; //也可以用/*来匹配所有
intptr_t handle = _findfirst(current_path.c_str(), &file_info);
//返回值为-1则查找失败
if (-1 == handle)
{
cout << "cannot match the path" << endl;
return;
}
do
{
//判断是否子目录
if (file_info.attrib == _A_SUBDIR)
{
//递归遍历子目录
int layer_tmp = layer;
if (strcmp(file_info.name, "..") != 0 && strcmp(file_info.name, ".") != 0) //.是当前目录,..是上层目录,必须排除掉这两种情况
DfsFolder(path + '/' + file_info.name, layer_tmp + 1); //再windows下可以用\\转义分隔符,不推荐
}
else
{
//打印记号反映出深度层次
//for (int i = 0; i<layer; i++)
// cout << "--";
//cout << file_info.name << endl;
string filename = file_info.name;
string suffixStr = filename.substr(filename.find_last_of('.') + 1);//获取文件后缀
NumOfCharsLinesInFile(path + '/' + file_info.name);
}
} while (!_findnext(handle, &file_info)); //返回0则遍历完
//关闭文件句柄
_findclose(handle);
}
bool compare(my_word a, my_word b)
{
return a.appear_count>b.appear_count; //升序排列
}
bool phrase_compare(my_phrase a, my_phrase b)
{
return a.appear_count>b.appear_count; //升序排列
}
void Getten_word() {
my_word temporary_word;
for (const auto &w : word_count)
{
ten_word[10] = w.second;
for (int i = 0; i <= 9; i++)
{
if (ten_word[i].appear_count < ten_word[i + 1].appear_count)
{
temporary_word = ten_word[i];
ten_word[i] = ten_word[i + 1];
ten_word[i + 1] = temporary_word;
}
}
}
sort(ten_word, ten_word + 10, compare);
}
void Getten_phrase()
{
my_phrase temporary_phrase;
for (const auto &w : phrase_count)
{
ten_phrase[10] = w.second;
for (int i = 0; i <= 9; i++)
{
if (ten_phrase[i].appear_count < ten_phrase[i + 1].appear_count)
{
temporary_phrase = ten_phrase[i];
ten_phrase[i] = ten_phrase[i + 1];
ten_phrase[i + 1] = temporary_phrase;
}
}
}
sort(ten_phrase, ten_phrase + 10, phrase_compare);
}
int main(int argc, char *argv[])
//int main()
{
clock_t tStart = clock();
//递归遍历文件夹
DfsFolder("D:/newsample", 0);
//递归遍历文件夹结束
cout << "characters: " << TotalNum_chars << endl;
cout << "words: " << TotalNum_words << endl;
cout << "lines: " << TotalNum_lines << endl;
Getten_word();
cout << "=====================word=====================" << endl;
for (int i = 0; i < 10; i++)
{
cout << ten_word[i].sort_word << " " << ten_word[i].appear_count << endl;
}
Getten_phrase();
cout << "====================phrase===================" << endl;
for (int i = 0; i < 10; i++)
{
cout << ten_phrase[i].sort_phrase << " " << ten_phrase[i].appear_count << endl;
}
printf("Time taken: %.2fs\n", (double)(clock() - tStart) / CLOCKS_PER_SEC);
return 0;
}
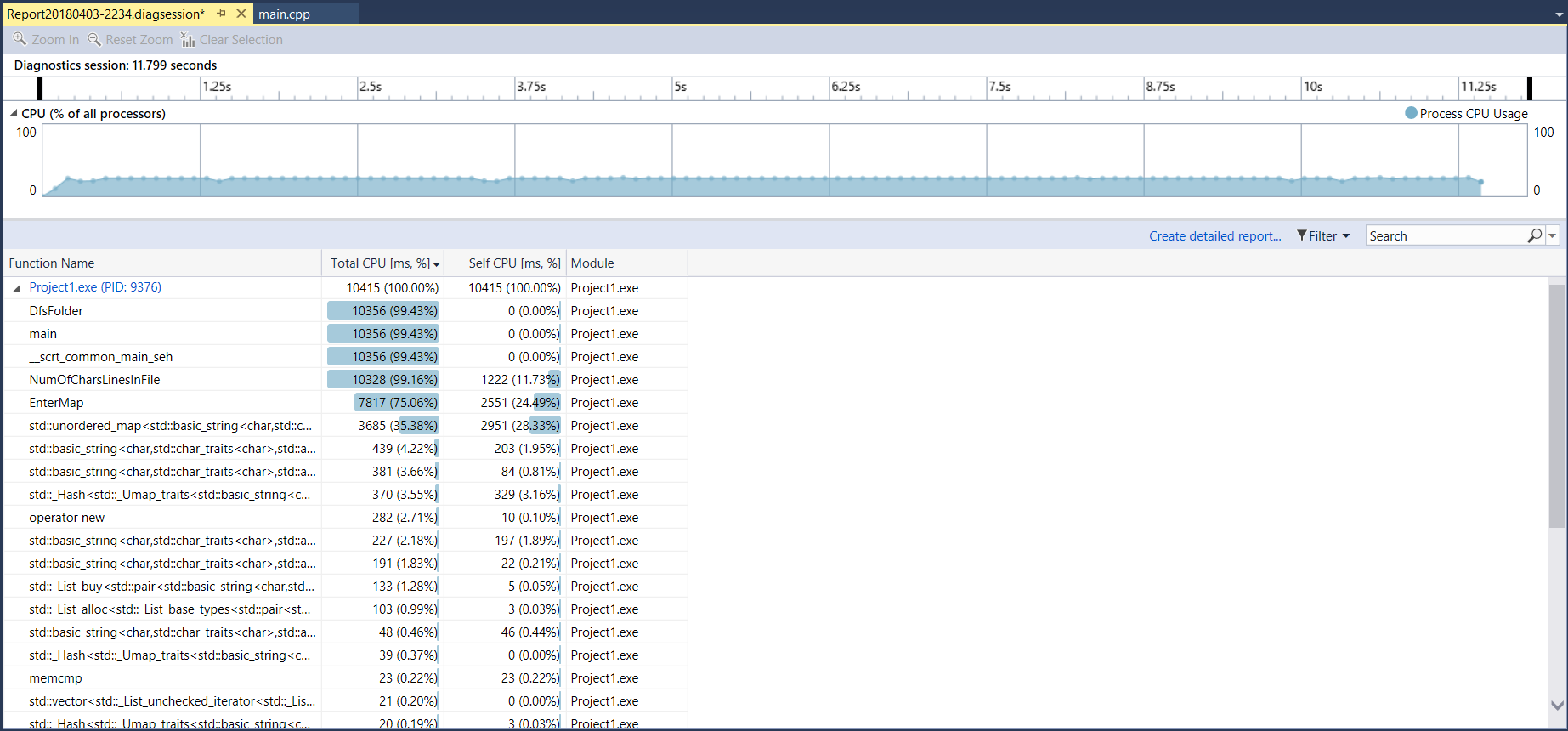
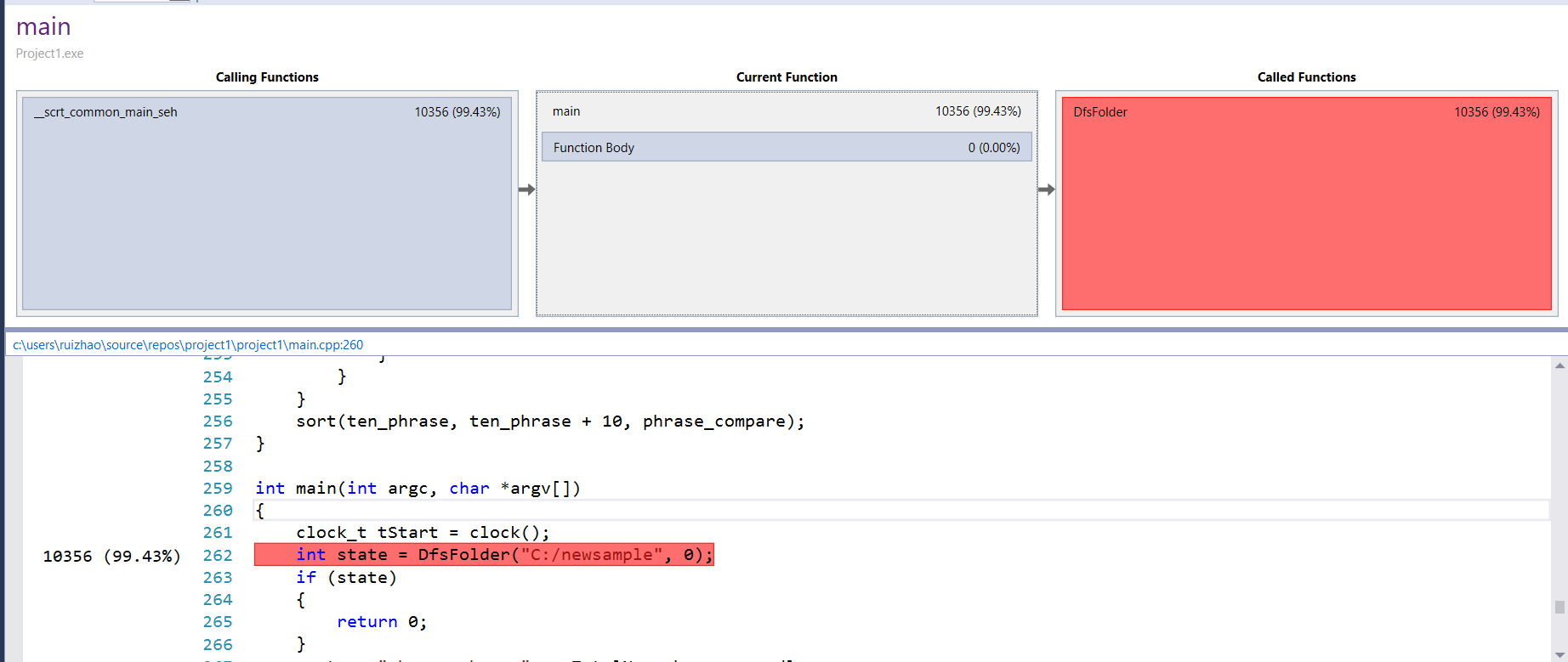
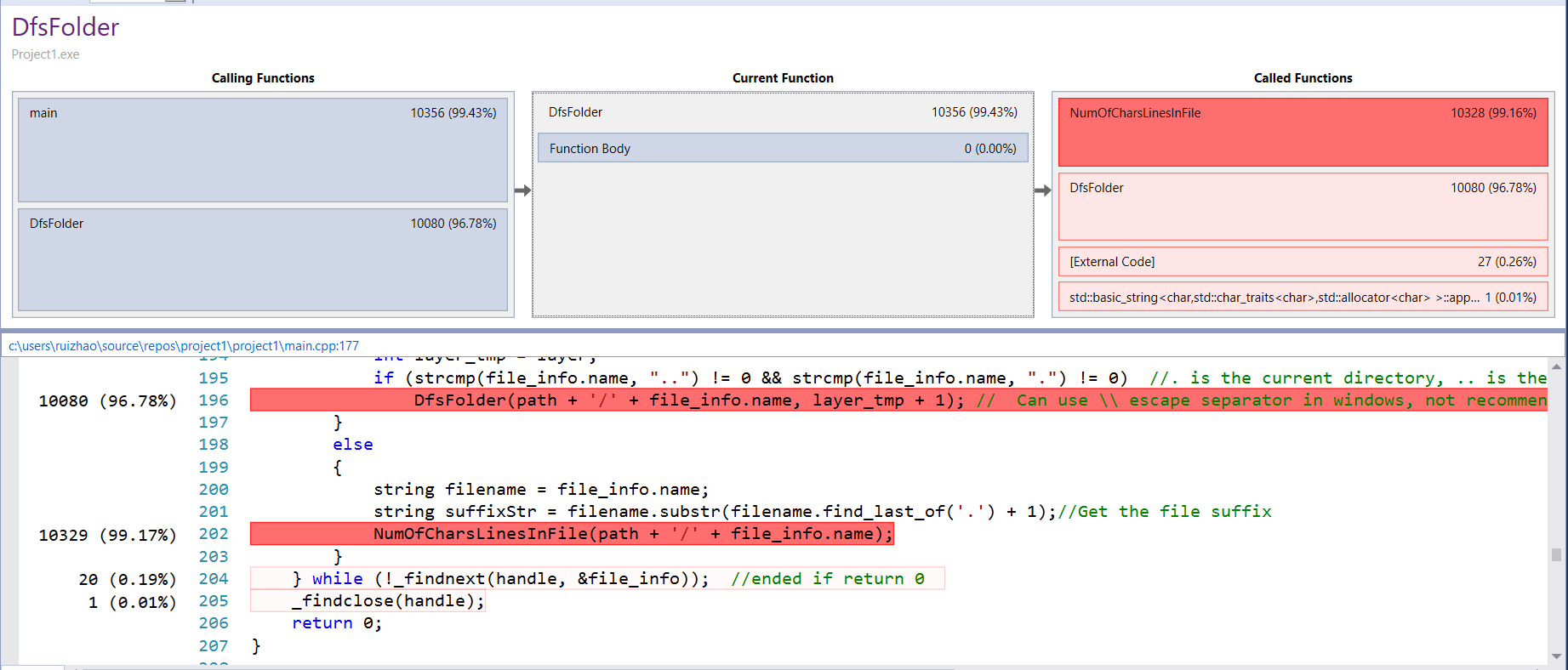
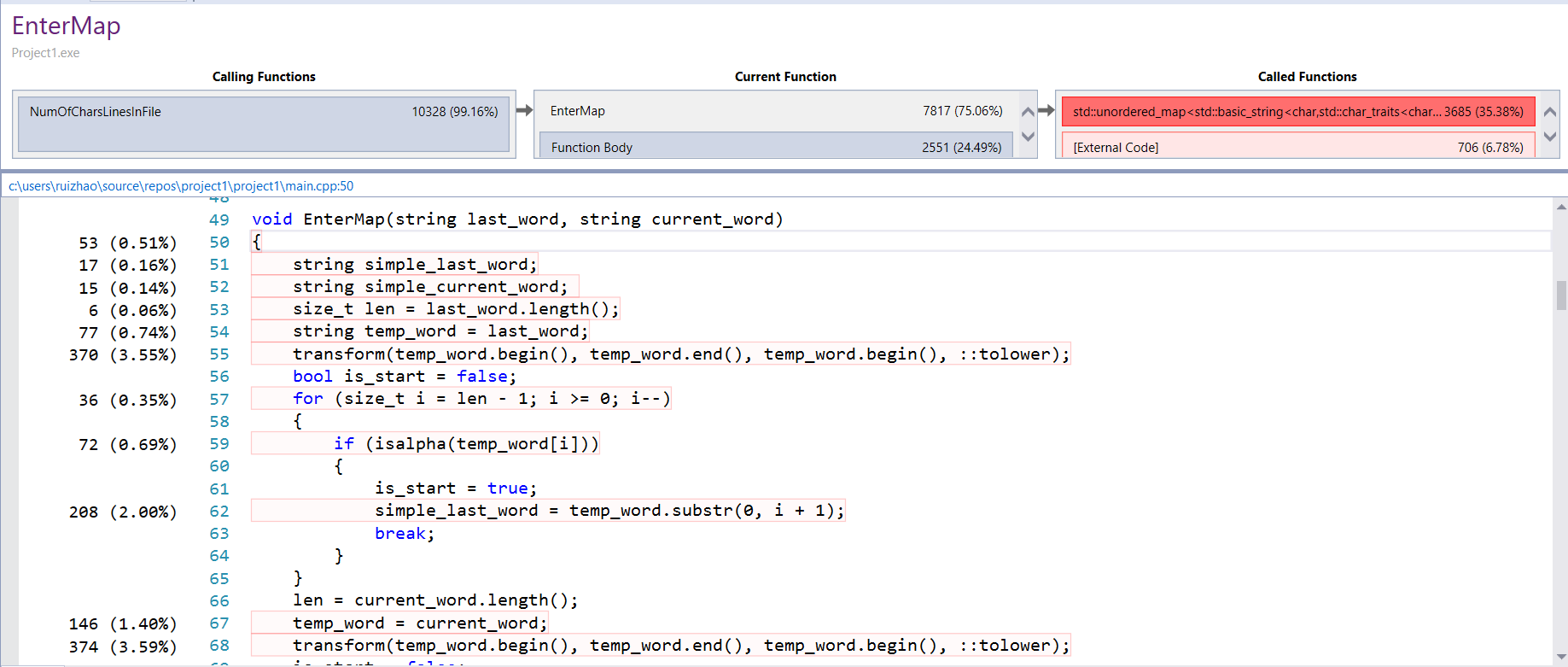
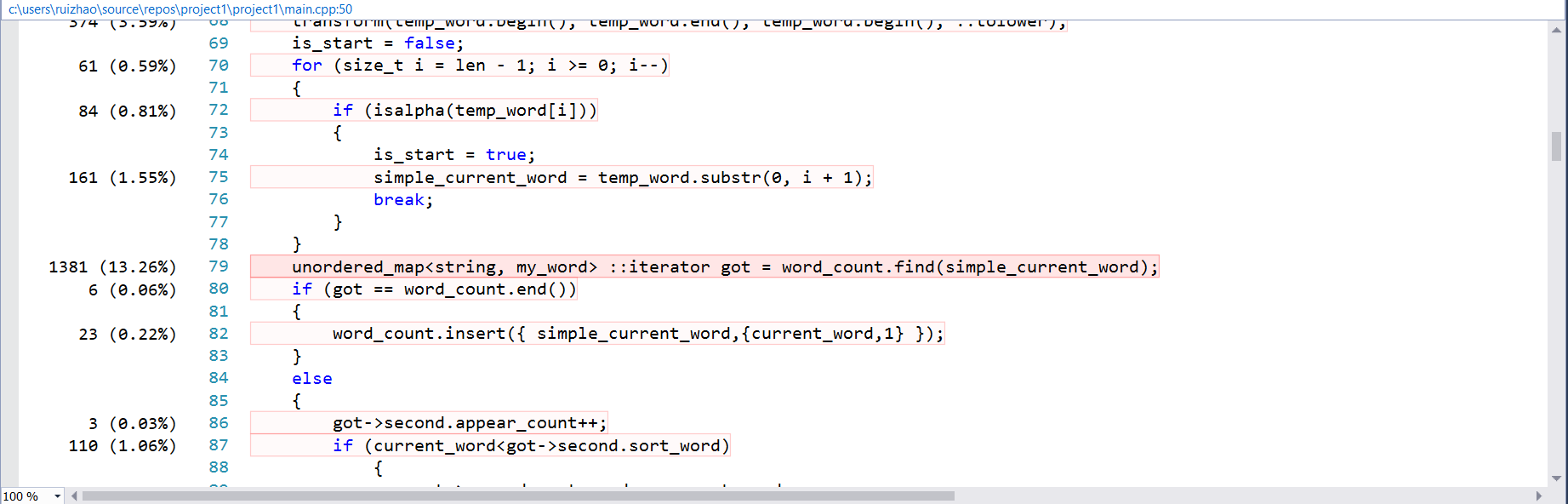
Performance analyses on Windows



Performance analyses on Linux
command lines :
g++ -std=c++11 -Wall -pg test_gprof.cpp -o test_gprof ./test_gprof gprof test_gprof gmon.out >analysis.txt
得到的分析结果,存在了analysis.txt文件中
经观察,可以看到有用的信息:
Call graph (explanation follows)
granularity: each sample hit covers 2 byte(s) for 0.06% of 16.82 seconds
index % time self children called name
<spontaneous>
[1] 99.0 0.00 16.66 main [1]
0.00 16.42 1/1 listDir(char*) [3]
0.14 0.06 1/1 Getten_phrase() [40]
0.00 0.04 1/1 Getten_word() [85]
0.00 0.00 20/20 std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, my_word, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, my_word> > >::operator[](std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&&) [166]
-----------------------------------------------
1.76 14.66 1323/1323 listDir(char*) [3]
[2] 97.6 1.76 14.66 1323 NumOfCharsLinesInFile(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
0.34 14.32 16641077/16641077 EnterMap(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [4]
-----------------------------------------------
125 listDir(char*) [3]
0.00 16.42 1/1 main [1]
[3] 97.6 0.00 16.42 1+125 listDir(char*) [3]
1.76 14.66 1323/1323 NumOfCharsLinesInFile(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
125 listDir(char*) [3]
-----------------------------------------------
0.34 14.32 16641077/16641077 NumOfCharsLinesInFile(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
[4] 87.2 0.34 14.32 16641077 EnterMap(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [4]
这两条表明了 NumOfCharsLinesInFile() 、 EnterMap 函数占据了主要时间,所以因该主要优化这两个函数,可是 Entermap 这个函数里面主要是用的 unordered_map 这个自带的关联容器,所以在单独语句上优化空间不大,但是在用map查词时候要尽量少,刚开始我用了好多次重复的map查询,后来改成了查询一次后把指向value的迭代器存下来,这一步优化在性能上有很大的进步。再就是在 NumOfCharsLinesInFile 这个函数里面优化。
GitHub管理代码
Windows下的project链接:https://github.com/ruizhao13/Project1/tree/%E8%B7%B3%E8%BF%87%E5%AD%97%E7%AC%A6%E5%A4%84%E7%90%86%E9%97%AE%E9%A2%98
共commit了49次。还记录了自己从第一次跑出来结果到最后优化到10s的经过。
Linux下的project链接:https://github.com/ruizhao13/homework1/tree/master/PB16120853
由于Ubuntu下的代码就是由Windows稍作修改得到的,所以没有commit几次
描述你在次项目中获得的经验:
这次在把warnning清除掉的时候,发现了很多需要注意的代码风格问题,感受到了消除warning的重要性,warning甚至告诉我这里代码可以优化。真是神奇了。
技多不压身,stl库真的很重要。
这次真的学了很多东西啊!由于只学过c语言和python,第一天(周六下午)写的时候差不多是一直在StackOverflow里面遨游啊有没有,旁边还一直要翻c++primer。
至于优化嘛,真的感受到了对于这种程序的热行优化的重要性,尤其刚开始的前几次优化,每次都效果显著。在visual studio的release模式下从一分钟到10s。
还有,这是第一次真的在实际项目中运用GitHub,感觉很好用,但是经常有忘记commit或者commit过于频繁的情况。
不足,最初单元测试的时候没有留下来记录,优化的截图也没有留下,当时认为自己肯定要花很久时间来搞,以为后面还会有很多单元测试和优化的过程,没有想到自己的进展会那么快。

