

ClickHouse入门
简介:ClickHouse是俄罗斯Yandex公司使用C++语言编写开源的列式存储数据库,主要用于在线分析查询(OLAP),不支持事务,使用SQL查询实时生成分析数据报告。
一、基本知识
1. 特点
A. 列式存储:较MySQL行式存储有利于列的聚合、计数等操作,针对每列可选择最优的数据压缩算法来压缩数据;
B. 支持DBMS功能:具备标准SQL语法,如DDL和DML,支持函数、用户和权限管理,以及数据的备份与恢复;
C. 引擎多样化:支持表级存储引擎插件化,目前有合并树、日志、接口和其它的四类各多种引擎;
D. 高吞吐写入:采用LSM Tree结构,数据顺序写入缓存后,线程定期合并顺序写入磁盘,达到每秒50到200M的写入能力;
E. 数据分区与线程级并行:将数据划分为多个partition,充分利用CPU并行处理来降低查询延迟,但不适合高QPS查询业务。
2. 数据类型
A. 整型:固定长度的整型,包括有符号和无符号整型,有符号如:Int8、Int16等,无符号如:UInt8、UInt16等,布尔值可以用UInt8的0和1表示;
B. 浮点型:Float32和Float64;
C. Decimal型:有符号的浮点数,如Decimal32(s)、Decimal64(s)等,其中s代表小数位;
D. 枚举类型:Enum8和Enum16类型,Enum8用'String'=Int8对描述;
E. 时间类型(DateTime):毫秒存储用DateTime64(3)类型,不要将时间类型字段用字符串存储,虽然底层将DateTime存储为时间戳整型,但是时间类型存储可读性和执行效率高;
F. 可为空值(Nullable):如Nullable(Int8),存储应该使用字段默认值或者一个在业务中无意义的值表示空,因为存储Null列时需要创建一个额外的文件且该列也无法被索引,对性能有损耗;
G. 字符串(String)等。
3. 表引擎
A. 合并树系列:如MergeTree、AggregatingMergeTree、SummingMergeTree等;
B. 日志系列:如Log等;
C. 接口系列:如S3、RabbitMQ、Kafka、MySQL等;
D. 其它系列:如Memory、Distributed等。
Distributed(分布式引擎):本身不存储数据,但可以在多个服务器上进行分布式查询,读是自动并行的。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
cluster:服务为配置中的集群名;database:远程数据库名;table:远程数据库表名;
sharding_key:可选参数,分片key;policy_name:可选参数,规则名,它会被用作存储临时文件以便异步发送数据。
4. SQL CRUD操作
A. 查询数据:与标准SQL差不多,支持子查询、with查询、各种join(不轻易使用)、group by增加了rollup、cube、total增强统计功能;
B. 新增数据:与标准SQL一致,支持标准和表到表的插入;
C. 修改数据:重新建分区+旧分区采用逻辑标记失效,合并分区时再删除已有数据实现,适合批量修改,如:alter table table_name update name = '张三' where id =1;
D. 删除数据:同修改数据一样实现,适合批量删除,格式:ALTER TABLE [db.]table [ON CLUSTER cluster] DELETE WHERE filter_expr;
E. 创建视图:
普通视图:不存储任何数据,他们只是在每次访问时从另一个表中执行读取,格式为:CREATE [OR REPLACE] VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster_name] AS SELECT ...
物化视图:当向SELECT中指定的表插入数据时,插入数据的一部分被这个SELECT查询转换,结果插入到视图中,格式为:CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
物化视图后创建怎么同步已有表数据方式:insert into view SELECT * FROM table WHERE id < 100;
二、MergeTree引擎
简介:合并树引擎是CK中最强大的引擎,支持索引和分区,媲美与MySQL中InnoDB。
1. 建表
A. 基本语法:

CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster ( name1 [type1] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1] [compression_codec] [TTL expr1] [COMMENT 'comment for column'],
name2 [type2] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr2] [compression_codec] [TTL expr2] [COMMENT 'comment for column'], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2 ) ENGINE = MergeTree ORDER BY expr [PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...] [SETTINGS name=value, ...]
COMMENT 'comment for table';
B. 排序键:设置数据按照哪些字段进行有序的保存,是唯一个必填项;
C. 分区:分区主要是降低扫描的范围,优化查询速度;分区文件保存在不同的分区目录中;数据写入时先放到临时分区中,待一定时间后执行合并到已有分区中;
分区目录名构成:PartitionId_MinBlockNum_MaxBlockNum_Level,其中PartitionId表示数据分区ID生成规则,MinBlockNum表示最小分区块编号,Level代表合并的次数;
分区下文件构成:.bin代表数据文件、.mrk代表标记文件,后面的数字表示自适应索引间隔、primary.idx表示主键索引文件、minmax_create_time.idex表示分区键的最大最小值、checksums.txt表示校验文件;
D. 主键:它只是表示数据的一级索引,并不代表唯一约束,主要用于改善索引性能和数据压缩,index granularity表示稀疏索引中两个相邻索引的对应数间隔,默认值为8192,稀疏索引的优点是利用很少的索引数据,采用二分查找更多的数据,注意主键必须是order by字段的前缀字段;
E. 二级索引(跳数索引):指INDEX,能够加速非主键字段的查询;
F. TTL:可以管理数据表或者列的生命周期,列TTL字段不能设置主键,且类型必须是日期。
2. ReplacingMergeTree
A. 唯一特性:ReplacingMergeTree是继承MergeTree所有特性,还同时具有去重特征;
B. 去重字段:使用order by字段作为唯一键;
C. 去重时机:只有同一批次插入或合并分区时才会进行去重;
D. 注意事项:去重不能跨分区,重复的数据保留是根据版本字段(引擎参数)最大值,如果版本字段相同或者不填版本字段则按照插入顺序保留最后一条;
E. 适用场景:在后台清除重复的数据来节省空间;
3. SummingMergeTree
A. 唯一特性:SummingMergeTree是继承MergeTree所有特性,还同时具有汇总聚合特征;
B. 聚合字段:使用order by字段作为唯一键,根据指定的列(可多个)来汇总数据,如果不填,以所有非维度列且为数字列的字段来汇总数据;
C. 聚合时机:只有同一批次插入或合并分区时才会进行聚合;
D. 注意事项:聚合不能跨分区,数据保留时其他的列是按插入的顺序保留第一行。
三、集群
1. 副本
A. 作用:保障数据的高可用性,注意副本只能同步数据,不能同步表结构;
B. 原理图:
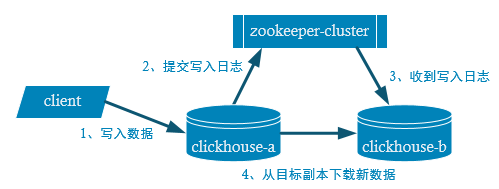
C. 其它:表引擎需要指定为Replicated系列,如engine=ReplicatedMergeTree。
2. 分片
A. 作用:弥补副本必须存储全量数据,无法横向扩容的问题,将数据进行切分,不同的分片分布到不同的节点上,通过Distributed表引擎把数据拼接一起,但是会引起操作复杂及查询性能降低问题,一般不采用分片;
B. Distributed:是一种中间件,类似于MySQL的MyCat,通过分布式逻辑表来写入、分发、路由操作多台不同节点分片的数据。
四、优化
1. Explain查看执行计划
A. 基本语法:explain [SYNTAX | PIPELINE] select ...;
B. SYNTAX :用来进行语法优化的;
C. PIPELINE:用来查看PIPELINE计划;
2.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-01-20 Java List的交集、并集、差集、补集