

Kafka 基础与核心原理
一、基础知识
1. 核心概念
A. Broker:一个集群由多个broker组成,每个broker就是一个kafka的实例,其中管理者称为controller,controller选举遵循先到先得;
B. Topic:根据业务系统将不同的数据存放在不同的topic中,topic可以分布式存储在多个broker中;
C. Interceptor:分为生产者和消费者拦截器;
D. Partition:一个Topic有多个分区,单个分区内的消息是有序的,不保证多分区间的顺序,一个分区只属于个主题,同一主题下的不同分区包含的消息不同;
E. Offset:生产者每生产一条数据都会追加到指定分区的文件中,记录的有序就是通过offset的id来唯一标识;
F. Persistence:kafka会保存所有发布的记录,无论是否被消费,可以设置保留期限来释放磁盘空间;
G. Replication:每个分区可能会有多个副本,分leader(数据读写)和follower(数据备份);
H. Producer:向broker发消息的客户端,根据策略推送到指定的 partition中;
I. Consumer :向broker拉取消息的客户端,每个消费者都要维护自己读取数据的offset;
J. Consumer Group:一个消息可以被不同的消费者消费,但一个消息只能被同组内一个消费者消费,若消费者数量比分区多,多的就成了备用作用,分Leader(第一个加入)和Follower。
2. Contoller节点流程
A. Controller选举:注册Broker节点;监听/controller节点;注册/controller节点;选举成为controller,监听/brokers/ids节点,若已有controller就通知集群的变化;连接所有Broker,发送集群的相关数据;
B. Controller节点删除:通知节点的删除;注册/controller节点;增加/brokers/ids监听器;连接所有Broker,发送集群的相关数据。
3.spring-kafka中注解
A. @KafkaListener:用于定义一个监听器,监听Kafka中的消息,可以配置topics、containerFactory、topicPartitions;
B. @EnableKafka:用于启用Spring Kafka的自动配置功能。
4. 其他
A. 集群脑裂:controller_epoch(纪元)来解决;
B. 零拷贝技术:FileChannel.transforTo;
C. 顺写日志:性能高,选择机械硬盘即可;
D. 数据压缩:选择合适的压缩算法,确保性能最优。
5. 服务段配置参数
| 参数 | 说明 |
| num.io.threads | 用来处理请求的I/O线程数 |
| socket.send.buffer.bytes | SO_SNDBUFF 缓存大小,server进行socket 连接所用,默认100*1024 |
| socket.receive.buffer.bytes | SO_RCVBUFF缓存大小,server进行socket连接时所用。默认100 * 1024 |
二、生产者Producer
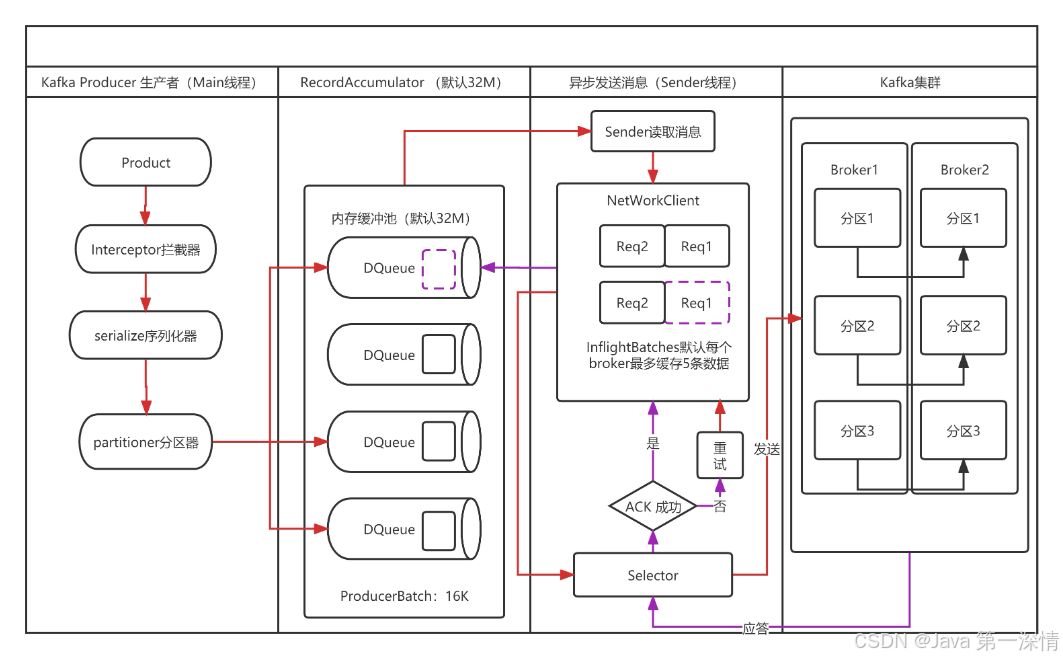
1. 生产者拦截器 :允许你在发送消息之前以及消息提交成功后植入你的拦截器逻辑,可用于日志记录、消息转换及消息验证等场景,需实现ProducerInterceptor;
2. 序列化:将消息对象转换成字节数组,才能通过网络传输,如下序列化String类型
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
3. 消息分区:
A. 自定义消息分区需实现Partitioner;
B. 消息发送方式:注意发送消息是main线程,但真正发送消息到kafka是sender线程;
acks=0:异步发送,生产者不会等待任何确认,消息可能丢失,即最多一次(at most once);
acks=1:生产者等待leader副本确认,但不等待所有副本确认,即最少一次(at least once);
acks=all或-1:生产者等待所有副本确认,确保消息不会丢失且不重复,即精准一次(exactly once),靠幂等+事务来保障。
4. 数据收集器:为了提升性能,将消息收集到ProducerBatch,一个批次大小16K,超过16K就关闭,注意若单条数据超过16K,也可以放进去,但是该批次不再接收了;
5. 数据重复及乱序问题
A. 原因:两个问题都因为网络不稳定导致重试引起的,重试是保证数据的可靠性;
B. 幂等性:幂等是生产者的特征,可以保证生产者发生的消息,在一个分区内不会重复且不乱序(ProducerState),通过生成者ID+数据的顺序号来唯一标识;
C. 事务:事务开启前必须开启幂等性,初始化事务(initTransactions)——>开启事务(beginTransaction)——>提交事务(commitTransaction)或终止事务(abortTransaction),底层整个事务流程还是比较复杂的。
6. 配置参数
| 参数 | 说明 |
| bootstrap.servers | Kafka 集群地址 |
| client.id | 设置 Kafka 对应的生产者ID,不设置就默认生成 |
| acks | 消息确认见上面 |
| max.request.size | 限制生产者客户端能发送的消息的最大值,默认 1M |
| retries | 重试次数 |
| linger.ms | 指定生产者发送 ProducerBatch 之前等待更多消息 (ProducerRecord) 加入 ProducerBatch 的时间,默认值 0 |
| batch.size | 累计多少条信息,则一次进行批量发送,默认16K |
| buffer.memory | 缓存提升性能参数,默认为32M |
| request.timeout.ms | 这个参数用来配置 Producer 等待请求响应的最长时间,默认值为 3000(ms) |
| enable.idempotence | 开启幂等性操作,要求在途请求缓冲区不能大于5(默认值) |
| transactional.id | 开启事务 |
三、消费者Consumer
1. 消费者拦截器:支持在消费消息前以及提交位偏移后编写特定逻辑;
2. 反序列化:将字节数组转换成消息对象,如下序列化String类型;
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3. 消费偏移量(自动保存可能存在消费重复问题)
A. 偏移量同步提交:通过显示调用commitSync()来提交偏移量,可以确保只有在成功处理消息后才更新消费者位置;
B. 偏移量异步提交:通过配置auto.commit.interval.ms来控制提交的频率;
4. 消费者内部主题:_consumer_offsets保存消费者偏移量(默认50个分区),不允许外部操作,也可以改为外部存储如数据库;
5. 消费者分配策略
A. RangeAssignor:每个消费者会被分配一组连续的分区,这种策略是基于消费者组中的消费者数量和topic分区的数量,将所有的分区均匀地分配给消费者,默认分区策略;
B. RoundRobinAssignor:轮询策略是基于消费者组中的消费者数量,将所有的分区轮流地分配给消费者;
C. StickyAssignor:当发生rebalance时候,该策略是优先保证分区分配均衡,然后尽可能保留现有的分配结果;
D. CooperativeStickyAssignor:在StickyAssignor基础上,优化rebalance过程。
6. 分区再平衡:
当消费者组中的消费者发生变化(如增加或减少消费者),Kafka 会触发分区再平衡。此时,Kafka 会重新分配分区给消费者,可能会影响消费者的偏移量。在此过程中,Kafka 确保每个分区仅由一个消费者进行消费,维护消息的有序性。
7. 配置参数:
| 参数 | 说明 |
| bootstrap.servers | Kafka 集群地址 |
| enable.auto.commit | 设置自动提交偏移量,默认true |
| auto.commit.interval.ms | 自动提交偏移量间隔,默认5s |
| isolation.level | 隔离级别(read_uncommitted:允许读取尚未被提交的消息,read_committed:仅允许读取已被提交的消息) |
| auto.offset.reset | 开始消费的位置(earliest:partition的起始位置开始消费,latest:新加入partition的消息才会被消费) |
| group.id | 标识一组消费者,这些消费者共同消费同一个主题的消息,每个消费者组都会维护自己的偏移量 |
| partition.assignment.strategy | 设置分区分配策略,见上面 |
| group.instance.id | 配置唯一标识符 |
| max.poll.records | 控制消费者每次调用poll()方法时,从Kafka服务器拉取的最大记录数 |
| fetch.min.bytes | 每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回 |
| fetch.max.bytes | 配置Consumer在一次拉取中获取的最大数据量 |
| heartbeat.interval.ms | 消费者间隔多久发送心跳给群组协调器证明自己活跃者,单位为毫秒,不能设置过小 |
| request.timeout.ms | 发送请求时等待响应的最长时间 |
| session.timeout.ms | 消费者与集群之间的会话超时时间,一般要超过心跳的2倍 |
四、数据存储
1. 数据以主题+分区为单位存储的,文件有.log(数据日志文件,文件名是代表起始偏移量,分批次头+数据体组成),.index(偏移量稀疏索引文件),.timeindex(时间索引文件);
2. 数据同步一致性:Follower主动向Leader拉取数据同步,靠HW控制
ISR:同步副本列表,涉及列表变化与传播
水位线(watermark):亦称HW,消费者能消费数据的最大位置,随着副本的数据同步而上涨
LEO:日志最后偏移量
3. 日志清理策略:日志保存时间为7天,一旦超过了这个时间,将执行清理操作
A. delete:将过期数据删除,有基于时间的(默认),也有基于大小的;
B. compact:日期压缩,将相同key的数据只保留一份,这种会丢失数据。
4. 配置参数
| 参数 | 说明 |
| log.flush.interval.mesages | 用于控制日志 (Log) 文件的刷新频率 |
| log.flush.interval.ms | 用于控制日志 (Log) 文件的刷写时间 |
| log.segment.bytes | 数据切分为段的大小 |
| log.retention.hours | 小时默认7天 |
| log.retention.check.interval.ms | 负责设置检查周期,默认5分钟 |
| log.cleanup.policy | 日志清理策略 |
| log.retention.bytes | 默认-1 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗
2019-08-29 Elasticsearch 索引Index API(7.5.0)