
分布式 高可用(Keepalived/HAProxy)
简介:高可用(High Avalilability)指两台或两台以上业务系统启动着相同的服务,如果其中一台有故障,另外一台自动接管工作,实现故障转移。
一、Keepalived
简介:Keepalived是服务器一种高性能且轻量级的高可用或热备解决方案,通过VRRP协议(虚拟路由冗余协议)来防止服务器静态路由单点故障的发生,结合Nginx可以实现WEB前端服务的高可用。
1. 基础
A. 用途
故障转移:实现负载均衡中MASTER主机BACKUP主机之间的故障转移和自动切换;
心跳检测:负载均衡定期检查RS服务器的可用性决定是否给其分发请求;
B. VRRP(Vritrual Router Redundancy Protocol)协议:是一种容错协议,为了解决静态路由的单点故障;是通过一种竞选协议机制来将路由任务交给某台VRRP路由器,通过优先级来确定MASTER和BACKUP;保证当主机的下一条路由器出现故障时,由另一台路由器来替代出现故障的路由器进行工作,从而保证网络通信的连续性和可靠性,而且自身使用了加密协议;
C. 故障切换转移原理:在Keepalived正常工作时,MASTER节点会不断的向BACKUP节点发送心跳消息,用来告诉BACKUP节点自己还活着,当MASTER节点发生故障时,BACKUP节点就无法继续检测到MASTER节点的心跳,进而调用自身的接管程序,接管MASTER节点的IP资源和服务,当MASTER节点恢复故障时,BACKUP节点会释放MASTER节点故障时自身接管的IP资源和服务,恢复到原来的自身的备用角色;
D. 工作方式分类
抢占式(默认模式):MASTER以组播方式不断的向虚拟路由器组内发送自己的心跳报文,一旦BACKUP在设定时间内没有收到心跳信息的次数超过了限定次数,则会将MASTER的所有权转移到优先级最高的BACKUP;
非抢占模式:指只有在主节点完全故障时才能将BACKUP变为MASTER。
2. Keepalived搭建
A. 安装keepalived:yum install keepalived -y;
B. 修改/etc/keepalived/keepalived.conf配置文件,注意主备文件的区别在于router_id信息不一致、state状态描述信息不一致、priority优先级不一致;
C. 启动keepalived:systemctl start keepalived;
D. 查看日志:默认日志文件是var/log/messages;
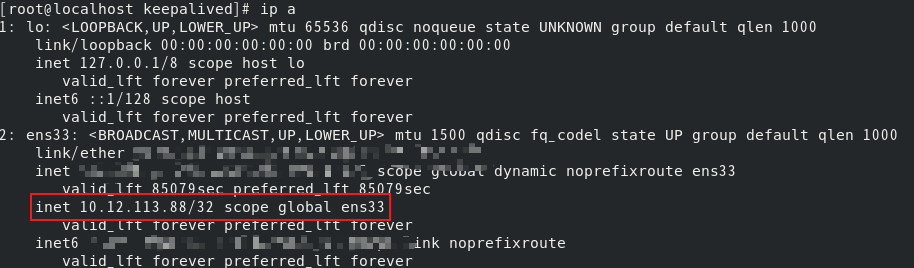
E. 查看虚拟IP状态:ip a;
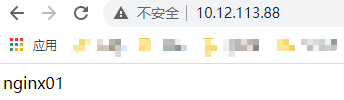
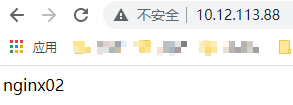
F. 测试nginx高可用
nginx01和nginx02主机都正常开启,nginx01主机上keepalived为主,nginx02主机上keepalived为备,keepalived也都正常开启,访问http://10.12.113.88,正常返回nginx01主机上的内容;
nginx01和nginx02主机都正常开启,nginx01主机上keepalived为主,但keepalived服务关闭,nginx02主机上keepalived为备且服务正常开启,访问http://10.12.113.88,正常返回nginx02主机上的内容;
3. keepalived.conf 配置文件
! Configuration File for keepalived
global_defs {
# 本节点的标识信息,即hostname
router_id dcy01
}
# 定时执行脚本并对脚本执行的结果进行分析,动态调整vrrp_instance的优先级
vrrp_script nginx_check {
# 检测Nginx状态的脚本路径
script "/etc/keepalived/nginx_check.sh"
# 检测时间间隔
interval 5
}
# 定义虚拟路由,VI_1为虚拟路由的自定义标示符
vrrp_instance VI_1 {
# 主节点为MASTER, 对应的备份节点为BACKUP
state MASTER
# 绑定虚拟IP的网络接口,与本机IP地址所在的网络接口相同
interface ens33
# 虚拟路由的ID号,两个节点设置必须一样,可选IP最后一段使用,相同的VRID为一个组,是决定多播的MAC地址
virtual_router_id 1
# 节点优先级,值范围 0-254,优先级高的就是主节点
priority 100
# 当转换为MASTER状态时,延迟多少秒发送第二组的免费ARP。默认为5s,0表示不发送第二组免的免费ARP
vrrp_garp_master_delay 10
# 当转换为MASTER状态时,在一组中一次发送的免费ARP数量。默认是5
vrrp_garp_master_repeat 10
# 组播信息发送间隔,两个节点设置必须一样,默认1s
advert_int 1
# 设置验证信息,两个节点必须一致
authentication {
# 认证方式
auth_type PASS
# 密码
auth_pass 123456
}
# 虚拟IP池,两个节点设置必须一样
virtual_ipaddress {
# 虚拟ip,可以定义多个,默认32位 mask
192.168.1.1
}
track_script {
# 执行Nginx监控
nginx_check
}
# 当当前节点成为master时,通知脚本执行任务
notify_master "/rhxy/keepalived/script/slave-to-master.sh"
# 当当前节点成为backup时,通知脚本执行任务
notify_backup "/rhxy/keepalived/script/master-to-slave.sh"
# 当当前节点出现故障,执行的任务
notify_fault "/rhxy/keepalived/script/master-to-slave.sh"
# 设置keepalived的状态,传入这个脚本的参数为($1为GROUP或INSTANCE、$2为组名或实例名、$3为"MASTER"|"BACKUP"|"FAULT")
notify "/rhxy/keepalived/script/notify-state.sh"
}
4. keepalived脑裂现象
A. 现象:脑裂指由于某些原因(如网络差、防火墙开启等),导致多台keepalived的服务器在指定时间内无法检测到对方存活心跳信息(事实上服务器还是存活状态),从而导致相互抢占对方的资源和服务所有权的现象;
B. keepalived监控nginx:Nginx宕机会导致用户请求失败,但是keepalived不会进行切换,故需要编写检测nginx是否存活的脚本,shell脚本如下;
#!/bin/sh
# 判断nginx是否关闭 if [ `ps -C nginx --no-header | wc -l` -eq 0 ];then #systemctl stop keepalived pkill keepalived fi
5. 主备切换时间原理
A. 将自身设置为MASTER节点后,立刻发送GARP广播包,默认发送两次,每次发送5个GARP数据包,每次间隔5s,GARP数据包中包含自身的优先级和工作状况数据,BACKUP服务器通过接收到的VRRP报文的情况判断MASTER路由器是否正常工作;
B. MASTER路由器主动放弃MASTER地位时,会先发送优先级为0的VRRP报文,使BACKUP路由器快速切换变为MASTER路由器,切换时间Skew_Time=(256 - BACUP路由器的优先级) / 256 秒;
C. MSTER路由器因故障不能发送VRRP报文时,BACKUP路由器并不能立即知道其工作状况,当BACKUP路由器等待一段时间后,如果还没接收到VRRP报文,那么会认为MASTER路由器无法正常工作,而把自己升级为MASTER路由器,周期性发送报文,如果此时多个BACKUP路由器竞争MASTER路由器的位置,将通过优先级来选举MASTER路由器,BACKUP路由器默认等待时间称为Master_Down_Interval=(3 * advert_int)+ Skew_Time;
D. 在性能不够稳定的网络中,Backup路由器可能因为网络堵塞而在Master_Down_Interval期间没有收到Master路由器的报文而主动抢占为Master位置,如果此时原Master路由器的报文又到达了,就会出现虚拟路由器的成员频繁的进行Master抢占现象,为了缓解这种现象的发生,特制定了延迟等待定时器(preempt_delay:设置抢占延迟。单位是秒,范围是0---1000,默认是0.发现低优先级的MASTER后多少秒开始抢占),它可以使得Backup路由器在等待了Master_Down_Interval后,再等待延迟等待时间,如在此期间仍然没有收到VRRP报文,此时Backup路由器才会切换为Master路由器,对外发送VRRP报文.
6. 其他
A. Keepalived防火墙策略:防火墙规则主从机器都要配置,双向打开vrrp服务,firewall-cmd --permanent --add-protocol=vrrp;firewall-cmd --reload;
B. 常见问题
问题一:WARNING - script '/etc/keepalived/nginx_check.sh' is not executable for uid:gid 0:0 - disabling;
原因:keepalived上监控脚本没有执行权限;
解决方案:chomd +x /etc/keepalived/nginx_check.sh。
C. 服务莫名不能启动:比如找不到配置文件,子进程无法启动等,可以执行:sed -i 's/^SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config && reboot;
二、HAProxy
简介:HAProxy提供高可用、负载均衡以及反向代理服务,支持虚拟主机,是免费、快速并且可靠的一种解决方案。
1. 基础
A. 特性
基于TCP(第四层)和HTTP(第七层)应用的代理,特别适合负载大的WEB站点,保护WEB服务器不会暴露在公网上;
是一种单进程、事件驱动模型,支持非常大的并发连接数;
拥有服务器健康检查功能和系统状态监控页面,当代理服务出现故障会自动剔除,可以减少程序增加健康检测功能,如果恢复又重新加入进来;
B. 负载均衡客户端与服务器识别方式
用户IP识别;
cookie识别;
session识别;
C. 负载均衡算法
roundrobin(默认算法):轮询算法,根据权重进行服务器轮流使用,适合短连接场景;
leastconn:最近最少算法,使用最近最少使用的服务器,适合长连接场景;
source:哈希算法,对请求源IP地址进行哈希。
D. http协议健康检查方式
option httpchk:通过监听端口进行健康检查,注意haproxy只会去检查后端server的端口,并不能保证服务的真正可用;
option httpchk GET /index.html:通过URI获取进行健康检测,这是用发送GET请求到后端的WEB界面,基本上可以代表后端服务的可用性;
option httpchk HEAD /index.jsp HTTP/1.1\r\nHost:\ www.xxx.com:通过request获取的头部信息进行匹配进行健康检测,这种检测方式,则是基于高级,精细的一些监测需求,通过对后端服务访问的头部信息进行匹配检测;
2. HAProxy搭建
A. 安装haproxy:yum install haproxy -y;
B. 修改/etc/haproxy/haproxy.cfg配置文件;
C. 启动haproxy:systemctl start haproxy;
D. 访问haproxy监控平台:http://127.0.0.1:1080。
3. haproxy.cfg 配置文件
# 全局参数
global
# 日志配置,指定使用127.0.0.1上的syslog服务中的local0日志设备,记录日志等级为info的日志
log 127.0.0.1 local0 info
# 设置运行haproxy的用户,可以使用uid替代
user haproxy
# 设置运行haproxy的组,可使用gid替代
group haproxy
# 以守护进程的方式运行
daemon
# 启动时的进程数,设置多个有助提高处理效率,但是过多的进程数也可能会导致进程的崩溃
nbproc 16
# 每个进程的最大连接数 ,由于每个连接包括一个客户端和一个服务器端,所以单个进程的TCP会话最大数目将是该值的两倍
maxconn 4096
# 设置最大打开的文件描述符数,在1.4的官方文档中提示,该值会自动计算,所以不建议进行设置
#ulimit -n 65536
# 将所有进程写入pid文件
pidfile /var/run/haproxy.pid
# 默认参数
defaults
# 运行模式有http、tcp(默认值)、health
mode http
# 使用127.0.0.1上的syslog服务的local3设备记录错误信息
log 127.0.0.1 local3 err
# 定义连接后端服务器的失败重连次数,判断服务不可用
retries 3
# 启用HTTP请求日志记录,默认haproxy日志格式很简单
option httplog
# 如果后端有服务器宕机,强制切换到正常服务器
option redispatch
# 丢弃由于客户端等待时间过长而关闭连接但还在harpoxy等待队列中的请求
option abortonclose
# 不记录健康检查的日志信息
option dontlognull
# 每次请求完毕后主动关闭http通道
option http-server-close
# 连接超时
contimeout 5000
# 客户端超时
clitimeout 3000
# 服务器超时
srvtimeout 3000
# frontend和backend的组合体,定义一个名为status的部分
listen status
# 定义监听的套接字
bind 0.0.0.0:1080
# 定义为HTTP模式
mode http
# 继承global中log的定义
log global
# stats是haproxy的一个统计页面的套接字,该参数设置统计页面的刷新间隔为30s
stats refresh 30s
# 统计页面URL路径
stats uri /admin-stats
# 设置统计页面认证时的提示内容
stats realm Private lands
# 设置统计页面认证的用户和密码,如果要设置多个,另起一行写入即可
stats auth admin:123456
# 隐藏统计页面上的haproxy版本信息
stats hide-version
# 接收请求的前端虚拟节点
frontend web
# 监听80端口
bind 0.0.0.0:80
# 定义为HTTP模式
mode http
# 启用X-Forwarded-For,在requests头部插入客户端IP发送给后端的server,使后端server获取到客户端的真实IP
option forwardfor
# 定义一个名叫static_down的acl,当backend static_sever中存活机器数小于1时会被匹配到
acl static_down nbsrv(static_server) lt 1
# 定义一个名叫php_web的acl,当请求的url末尾是以.php结尾的,将会被匹配到,上面两种写法任选其一
acl php_web url_reg /*.php$
# 定义一个名叫static_web的acl,当请求的url末尾是以.css、.jpg、.png、.jpeg、.js、.gif结尾的,将会被匹配到,上面两种写法任选其一
acl static_web url_reg /*.(css|jpg|png|jpeg|js|gif)$
# 如果满足策略static_down时,就将请求交予backend web_server
use_backend web_server if static_down
# 如果满足策略php_web时,就将请求交予backend web_server
use_backend web_server if php_web
# 如果满足策略static_web时,就将请求交予backend static_server
use_backend static_server if static_web
# 配置后端服务集群
backend web_server
# 设置为http模式
mode http
# 设置haproxy的调度算法为源地址hash
balance source
# 允许向cookie插入SERVERID,每台服务器的SERVERID可在下面使用cookie关键字定义
cookie SERVERID
# 开启对后端服务器的健康检测,通过GET /test/index.php来判断后端服务器的健康情况
option httpchk GET /test/index.php
server php_server_1 10.12.25.68:80 cookie 1 check inter 2000 rise 3 fall 3 weight 2
server php_server_2 10.12.25.72:80 cookie 2 check inter 2000 rise 3 fall 3 weight 1
# server语法:server <name> <address>[:port] [param*] # 使用server关键字来设置后端服务器;为后端服务器所设置的内部名称[php_server_1],该名称将会呈现在日志或警报中、后端服务器的IP地址,支持端口映射[10.12.25.68:80]、指定该服务器的SERVERID为1[cookie 1]、接受健康监测[check]、监测的间隔时长,单位毫秒[inter 2000]、监测正常多少次后被认为后端服务器是可用的[rise 3]、监测失败多少次后被认为后端服务器是不可用的[fall 3]、分发的权重[weight 2]、最后为备份用的后端服务器,当正常的服务器全部都宕机后,才会启用备份服务器[backup]
server php_server_bak 10.12.25.79:80 cookie 3 check inter 1500 rise 3 fall 3 backup
backend static_server
mode http
option httpchk GET /test/index.html
server static_server_1 10.12.25.83:80 cookie 3 check inter 2000 rise 3 fall

 浙公网安备 33010602011771号
浙公网安备 33010602011771号