

MySQL 面试题集绵
问题1:MySQL关键字不区分大小写么?
答:A. windows环境上不区分,linux环境上区分,现在都可以设置成区分或不区分;
B. 语句规范:关键字与函数名称全部大写,数据库、表、字段名称全部小写。
问题2:数据库的三大范式是什么?
答:A. 第一范式(1NF):数据表中的每一列必须是不可拆分的最小单元,也就是确保每一列的原子性;
B. 第二范式(2NF):基于第一范式,要求表中的所有列,都必须依赖于主键,而不能有任何一列与主键没有关系;
C. 第三范式(3NF):基于第二范式,要求表中的每一列只与主键直接相关而不是间接相关。
注:第二范式和第三范式在于有没有分出两张表,第二范式是说一张表中包含了多种不同的实体属性,那么要必须分成多张表, 第三范式是要求已经分成了多张表,那么一张表中只能有另一张表中的id,而不能有其他的任何信息(其他的信息一律用主键在另一表查询)。
问题3:delete、truncate和drop的区别?
答:A. delete:DML语言,只删除数据不删除表结构,会走事务;
B. truncate:DDL语言,清空表数据并且重置auto_increment的值,执行后立即生效,无法找回;
C. drop:DDL语言,不仅删除数据还删除表结构,执行后立即生效,无法找回。
注:执行速度:drop > truncate > delete。
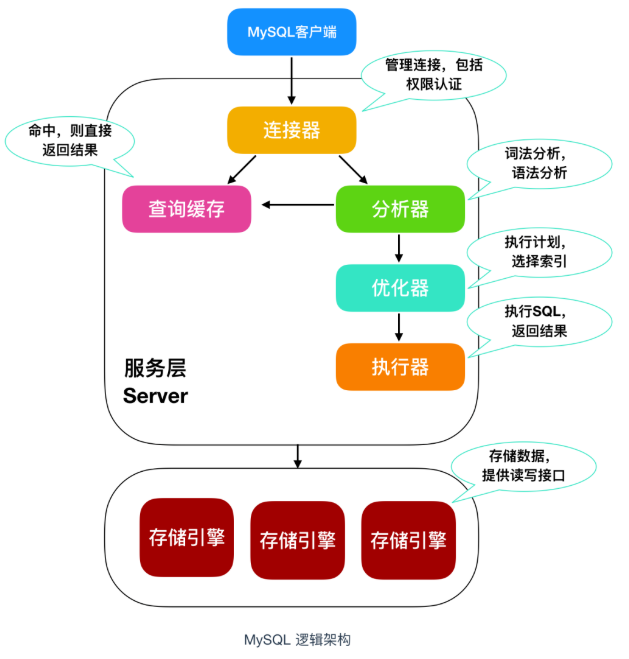
问题4:MySQL基础架构组成?
答:连接器 —— 使用账号密码登录,连接用户和MySQL数据库;
查询缓存 —— 若sql查询命中缓存,就返回,若没命中,就执行后面的操作,并将结果放入缓存中;
注:查询缓存不建议使用,因为数据表中存在任何一张表有更新操作,查询缓存就失效。
分析器 —— sql词法和语法分析;
优化器 —— 根据索引和连接,自动优化sql,确定效率更高方式;
执行器 —— 调用存储引擎提供的接口存取数据;
存储引擎 —— 存储数据,提供读写接口。
查询执行流程:客户端发送一条查询sql给服务器 —> 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果,否则进入下一阶段 —> 服务器端进行sql解析、预处理,再由优化器生成对应的执行计划 —> MySQL根据执行计划,调用存储引擎的API来执行查询 —> 将查询结果返回给客户端(结果缓存)。
问题5:MySQL存储引擎有哪些及区别?
答:MySQL常见存储引擎有InnoDB、MyISAM和Memory;
1. InnoDB特点
A. 是事务型存储引擎,支持事务ACID特性,MySQL5.1版本后,它就变成了默认存储引擎;
B. 实现了四个隔离级别,默认级别是可重复读,在该级别下,通过多版本并发控制(MVCC)+间隙锁可防止幻读;
C. 主索引是聚簇索引,在索引中保存了数据,从而避免直接读磁盘,提高了查询性能;
D. 实现了缓冲管理,不仅能缓冲索引也能缓冲数据,并且会自动创建散列索引以加快数据的获取;
E. 灾难恢复性好(日志文件)、支持在线热备份、外键约束和行级锁(会发生死锁);
F. 表数据文件为.ibd和.frm,其中 .frm文件存储表结构定义,InnoDB的表数据与索引数据是存储在一起的,都位于B+树的叶子节点上,即在.ibd文件上。
2. MyISAM特点
A. 不支持事务,MySQL5.1版本前,它是默认存储引擎;
B. 只支持表级锁,故并发性差,还支持压缩表和空间数据索引等;
C. 灾难恢复性差,不支持外键和行级锁;
D. 在磁盘上存储三个文件,文件名和表名相同,扩展名分别是 .frm(存储表定义)、.MYD(MYData,存储数据)、MYI(MyIndex,存储索引),索引和数据是分开存储的;
E. SELECT性能较高,适用于查询较多的情况。
3. Memory特点
A. 支持表级锁,虽然内存访问快,但如果频繁的读写,表级锁会成为瓶颈;
B. 只支持固定大小的行,不支持TEXT、BLOB字段;
C. 服务器重启后数据会丢失。
问题6:为啥不能用uuid作MySQL的主键?
答:A. 插入数据效率排名:自增ID > 雪花算法生成的ID > uuid;
B. uuid对应的新行值不能像自增ID那样排在原有的最大数据行下一行,这样导致为寻求合适的位置而分配新的空间,该过程会导致页分裂和碎片问题;
C. 自增ID的缺点就是对于高并发的负载,主键在进行插入的时候会造成间隙锁的抢夺,有一定的性能缺失。
问题7:为什么索引结构默认使用B-Tree,而不是Hash或二叉树或红黑树呢?
答:A. Hash:虽然可以快速定位,但是没有顺序,IO复杂度高;
B. 二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关,取决于树的高度,并且IO代价高;
C. 红黑树:树的高度随着数据量增加而增加,IO代价高;
D. B+树:与Hash比较好的支持范围查询,与二叉树和红黑树比降低了树的深度大问题。
问题8:为什么官方建议使用自增长主键作为索引?
答:A. 自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分;
B. 还能减少数据的移动,每次插入都是插入到最后。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗