

Java 集合框架(List/Set/Map)
简介:多线程下有个并发修改异常:java.util.ConcurrentModificationException。
一、List
1. 实现类
A. ArrayList:基于数组实现的,支持随机访问;
B. Vector:与ArrayList类似,但线程安全的;
C. LinkedList
基于双向链表实现,只能顺序访问;
LinkedList查找,头尾查找速度极快,越往中间靠拢效率越低,但还是低于ArrayList;
LinkedList头部插入速度高于ArrayList;
如果是在最中间的位置插入的话,LinkedList速度比ArrayList的速度慢将近10倍;
可参考:LinkedList 源码解析

D. CopyOnWriteArrayList:与ArrayList类似,但线程安全的,取代Vector。
2. 举例
List<String> list = new ArrayList<>(); // 效率高,不支持并发
List<String> list = new Vector<>(); // 线程安全,但是效率低
List<String> list = Collections.synchronizedList(new ArrayList<>()); // 线程安全
List<String> list = new CopyOnWriteArrayList<>(); // 线程安全,JUC包下的类
3. 初始化List方式
A. 常规方式:new ArrayList<>(),调用add方法;
B. Arrays工具类:调用Arrays工具类里的asList方法;
C. 匿名内部类:new ArrayList<>(){{add()}} ;
D. JDK8:Stream.of().collect(toList());
4. ArrayList
A. 底层数据结构:采用数组实现的;
B. 继承关系

C. ArrayList的随机访问效率高于顺序访问,而LinkedList的顺序访问效率高于随机访问效率;
D. 扩容:初始容量为10,以后每次扩容都是原来容量的1.5倍,若频繁扩容将会导致添加新能急剧下降,所以需要避免自动扩容,根据实际情况初始化容量;
D. ArrayList查找无论什么位置,都是直接通过索引定位到元素,时间复杂度O(1),ArrayList头部的每一次插入都需要移动size-1个元素,故效率低于LinkedList,但是尾部插入速度很快;
E. 采用了快速失败的机制,通过记录modCount参数来实现,在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
可参考:ArrayList 源码解析
二、Set
1. 实现类
A. HashSet:基于数组和链表实现的,无序且不能重复;
B. TreeSet:基于红黑树实现的,可以进行值的排序;
C. LinkedHashSet:元素有序;
D. CopyOnWriteArraySet:线程安全。
2. 举例
Set<String> set = new HashSet<>(); // 效率高,但是线程不安全
Set<String> set = Collections.synchronizedSet(new HashSet<>()); // 线程安全
Set<String> set = new CopyOnWriteArraySet<>(); // 线程安全,JUC包下的类
三、Map
1. 特点
A. 元素是成对存在的,每个元素由键和值组成,通过键可以找到值;
B. 不包含重复的键,值可以重复。
2. 实现类
A. HashMap:基于哈希表实现,允许key和value都为null值,元素无序,线程不安全;
B. LinkedHashMap:基于hash表+链表实现,元素有序;
C. TreeMap:基于红黑树实现,key不允许为null值,可以进行键的排序;
D. Hashtable:基于hash表实现,value不可以存储null值,线程安全;
E. ConcurrentHashMap:与HashMap类似,但线程安全;
F. WeakHashMap:适合缓存场景。
3. 举例
Map<String, String> map = new HashMap<>(); // 效率高,多线程不安全
Map<String, String> map = new ConcurrentHashMap<>(); // 多线程安全,JUC包下的类
4. 举例
A. Object obj = new Object();// 写在50个循环内等于有50个引用指向50个对象,这50个对象在一定时间内都是会占用内存,直到内存不足GC主动回收;
B. obj = new Object();// 写在50个循环内等于只使用一个引用分别指向50个对象,当指向后一个对象时,前一个对象已经是“无引用状态”,会很快的被GC主动回收,可以更好的管理内存。
5. HashMap
A. 四种遍历方式

public static void main(String[] args) { // 循环遍历Map的方法 Map<String, Integer> map = new HashMap<>(); map.put("A", 1);
map.put("B", 2);
// 第一种:entrySet遍历,适合键和值都需要时使用(最常用) for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue()); }
// 第二种:通过keySet或values来实现遍历,性能略低于第一种方式 // map中的键遍历 for (String key : map.keySet()) { System.out.println("key = " + key); } // map中的值遍历 for (Integer value : map.values()) { System.out.println("value = " + value); }
// 第三种:使用Iterator遍历 Iterator<Map.Entry<Integer, Integer>> it = map.entrySet().iterator(); while (it.hasNext()) { Map.Entry<String, Integer> entry = it.next(); System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue()); } // 第四种:java8语法,性能低于第一种 map.forEach((key, value) -> { System.out.println(key + ":" + value); }); }
B. HashMap在并发情况下会导致死循环(JDK 1.7之前是扩容的死循环,JDK1.8是红黑树成环的死循环)问题,致使服务器CPU飙升到100%;
C. JDK1.8前的HashMap是由数组+单向链表组成,JDK1.8后是数组+单向链表+红黑树组成,当链表长度超过8时且数组长度大于64会自动转换成红黑树(目的是为了高效查询),当红黑树节点个数小于6时,又会转化成链表。
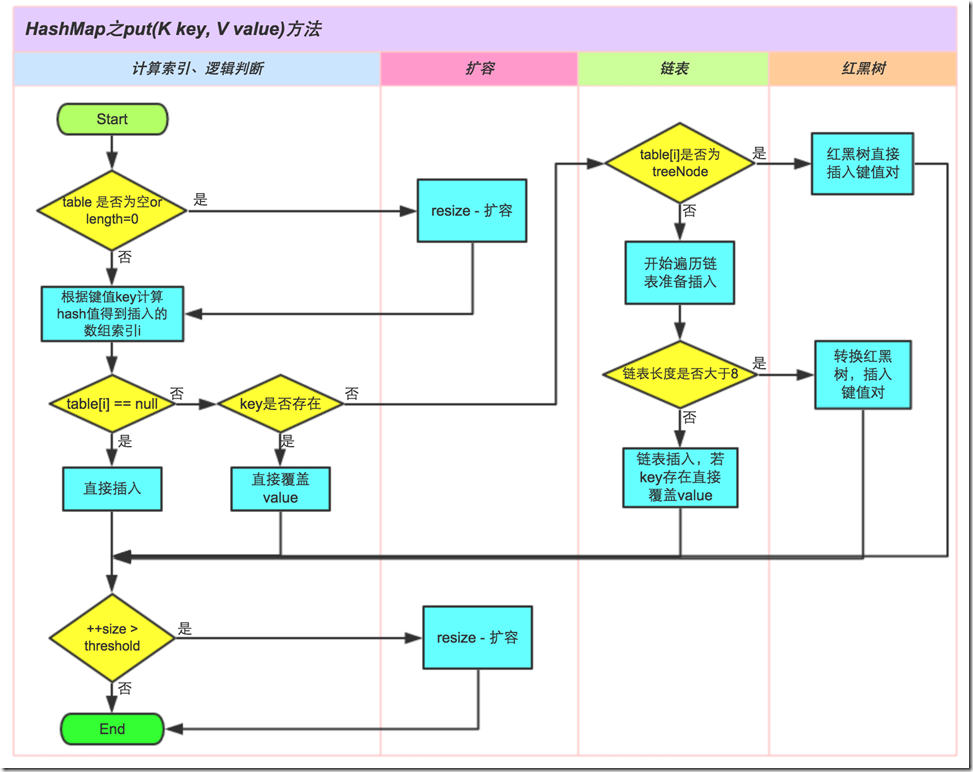
可参考:Map基本操作


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗