
Redis 数据结构/内存模型
一、Redis为什么这么快
1. IO多路复用
A. IO指网络IO,多路指的是多个TCP连接(Socket或Channel),复用指复用一个或多个线程;
B. select:一个线程处理多个客户端连接,又减少了系统调用的开销,即多个文件描述符只有一次select的系统调用 +n 次就绪状态的文件描述符的read系统调用
C. poll:
D. epoll:
二、数据结构
1. 分类
A. 简单动态字符串(sds):获取字符串长度的时间复杂度为O(1)、杜绝了缓冲区溢出、减少内存重分配次数;
B. 链表(linkedlist);
C. 字典(hashtable):用于保存键值对的抽象数据结构;
D. 跳跃表(skiplist):存储有序集合对象,查找上先从高Level查起,时间复杂度和红黑树相当,实现容易,无锁、并发性好;
E. 整数数组(intset):用于保存整数值的集合抽象数据结构,不会出现重复元素,底层实现为数组;
F. 压缩列表(ziplist):类似数组,通过一片连续的内存空间来存储数据,但它允许存储的数据大小不同,它的好处是更能节省内存空间。
2. 应用
A. 字符串类型(string):int整数、embstr编码的简单动态字符串、raw简单动态字符串;
B. 列表类型(list):ziplist(数据集比较少时使用,条件为列表中保存的单个数据小于64个字节,列表中数据个数小于512个)、linkedlist(数据量比较大时使用);
C. 哈希类型(hash):ziplist(数据量比较小时使用,条件为列表中保存的键和值的大小都小于64个字节,列表中键值对个数少于512个)、hashtable(数据量比较大时使用,对于hash冲突采用链表法解决);
D. 集合类型(set):intset(条件为存储的数据都是整数,存储的数据元素个数不超过512个)、hashtable(不满足intset时候使用);
E. 有序集合类型(zset):ziplist(数据量比较小时使用,条件为保存的数据小于64个字节,元素个数小于128个)、skiplist(不满足ziplist时候使用))。
三、内存模型
1. 当我们执行set hello world命令时,会有以下数据模型
A. sds:SDS(Simple Dynamic String)是Redis中一种数据结构,叫简单动态字符串,键hello是以SDS存储的,注意:Redis中字符串大多以SDS来存储;
B. redisObject:值world存储在redisObject中,实际上,redis的5中类型都是存在redisObject中,而redisObject中type字段指明了value对象的类型,ptr字段则指明了对象所在的地址,该对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持;
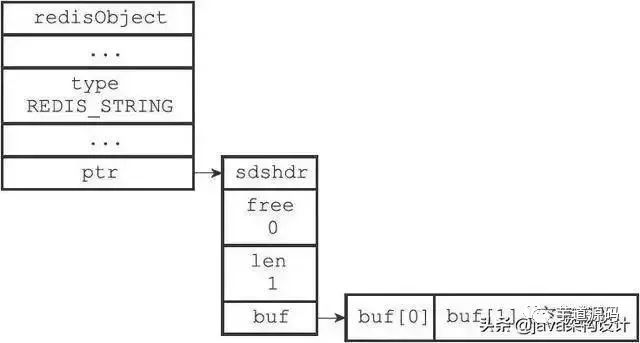
C. dictEntry:Redis给每个key-value键值对分配一个dictEntry,里面有着key和val的指针,next指向下一个dictEntry形成链表,这个指针可以将多个哈希值相同的键值对链接在一起;
D. 无论是dictEntry,还是redisobject、sds对象,都需要内存分配器(如jemalloc分配)内存进行存储,jemalloc在64位操作系统中,将内存空间划分为小、中、巨大三个范围,每个范围又划分了许多小的内存块单元,当Redis存储数据时,会选择大小最合适的内存块进行存储;
E. Redis支持的5种对象类型,每种结构都至少有两种编码。
2. 优化内存占用
A. 尽量使用整形替代字符串;
B. 尽可能使用共享对象;
C. 关注内存碎片比例;
可参考:IO多路复用


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!