
Redis 入门知识及原理
简介:Redis是Remote Dictionary Server的简写,由ANSI C语言编写,它是一种key-value形式的NoSql内存数据库,并提供多种语言的API;单线程架构,数据存放内存,故读写速度性能非常好;当然也支持内存中数据以快照和日志形式持久化到硬盘,从而在发生异常情况下数据也不会丢失。keyDB是从redis fork出来的分支,redis是一个单线程kv内存存储系统,而keyDB在兼容redis情况下,将redis改造为多线程。
一、特征
1. Ehcache、Memcache和Redis的对比
A. Ehcache:直接在JVM中缓存,速度快且效率高,主要用于单体架构应用和对缓存访问要求很高的应用;
B. Memcache:高性能,只支持key-value键值对,多线程、集群分布式的内存缓存系统;
C. Redis:支持持久化、丰富的数据类型、单线程、集群分布式;
2. 特点
A. 性能高,速度快:读性能达到11w/s,写性能达到8.1w/s;
B. 丰富的数据结构:如字符串、哈希、列表、集合、有序集合5种基础数据结构,还有位图(Bitmaps)、布隆过滤器(BloomFilter)、Hyperloglog、Geo复杂的数据结构;
C. 丰富的特性:键过期实现定时缓存、发布订阅实现消息队列、事务功能、管道实现批量处理命令等;
D. 丰富的客户端:主流的开发语言都接入了redis;
E. 缺点会有缓存穿透、缓存雪崩、Redis和数据库双写一致性问题、Redis的并发竞争key问题等;
F. list、hash、set的集合最大成员数为2的32次方-1即4294967295约42多亿。
3. 应有场景
A. 缓存:能够提升网站访问速度,大大降低数据库的压力;
B. 排行榜:有序集合机构实现复杂排行;
C. 计数器:用incr命令实现,适用于商品浏览量及视频播放量等;
D. 分布式会话:集群模式下,用redis搭建session服务;
E. 分布式锁:用setnx实现,适合并发访问高(全局ID、秒杀)的情况,Lua脚本保证多个命令一起执行,并发不高可用数据库悲观锁和乐观锁控制;
F. 社交网络:用哈希或集合等数据结构实现,适合点赞等;
G. 最新列表:lpush + ltrim来实现
H. 消息系统:适合简单的消息队列,注意:不推荐使用,一致性等问题多
二、常用操作命令
1. 管理命令
A. 启动:redis-server [--port 6379] | redis-server [../redis.conf]
B. 连接:redis-cli -h 127.0.0.1 -p 6379 [-c]
C. 停止:redis-cli shutdown | kill redis-pid
D. 测试连通性:ping命令,返回PONG即连通
E. 内存统计:info memory,info命令可以显示redis服务器的服务器基本信息、CPU、内存、持久化、客户端连接信息等
used_memory:Redis分配器分配的内存总量(单位是字节),包括虚拟内存(swap);
used_memory_rss:Redis进程占据操作系统的内存(单位是字节),即包括分配器分配的内存、进程运行本身需要的内存、内存碎片等,不包括虚拟内存;
mem_fragmentation_ration:内存碎片比例,该值是used_memory_rss / used_memory的比值,一般大于1,值越大代表内存碎片比例越大,可以通过安全重启的方面来减小内存碎片,若小于1,代表redis开启了虚拟内存(磁盘),内存不足应增加内存或节点或优化应用等,对于jemalloc分配器来说,比例值为1.03左右是比较健康的状态;
mem_allocator:Redis使用的内存分配器,有libc、jemalloc、tcmalloc,默认采用jemallocl,因为在控制内存碎片方面做得比较好。
2. key命令(key都是字符串)
A. keys patten:*是通配符,代表任意字符
注意:keys是遍历算法,时间复杂度是O(n),加上Redis是单线程执行,即数据越多,时间越长,故上线后,不要使用keys *命令,避免服务器卡死;
若要访问线上大数据量,则使用scan命令,虽然复杂度相同,但是不会阻塞线程。
B. del key [key ...]:删除键,可以同时删除多个;
C. type key:查询键类型;
D. expire key seconds:设置过期时间,秒级别;注意:如果用DEL, SET, GETSET会将key对应存储的值替换成新的,命令也会清除掉超时时间,那么意味着set更新值,就必须重新设置expire,而对于list结构中添加一个数据或者改变hset数据的一个字段是不会清除超时时间的;
E. ttl key:查询key的生命周期,秒级别,-1代表永不过期;
F. exists key [key ...]:查询键是否存在;
G. persist key:设置键永不过期;
3. string命令(缓存、限流、计数器、分布式锁、分布式session等)
A. set key value:存放键值;
B. get key:获取键值;
C. mset key value [key1 value1 ..]:批量存放键值;
D. mget key [key1 ...]:批量获取键值。
4. set命令(抽奖、赞、踩、标签、好友关系等):集合是无序且不可重复的,通过hash表实现的
A. sadd key member1 [member2]:向集合添加一个或多个成员;
B. scard key:获取集合的成员数;
C. srem key member1 [member2]:移除集合中一个或多个成员;
D. smembers key:返回集合中所有成员。
5. zset命令(排行榜、在线用户数统计等):有序集合是压缩列表和跳跃表实现的,读取中间的元素较快,比列表占内存
A. zadd key score member:添加元素;
B. zrangebyscore key min max [WITHSCORES ] [LIMIT offset count]:根据分值区间(min和max之间,包含两边)获取元素,元素顺序是按照从小到大;
C. zcount key min max:根据分值统计个数;
6. list命令(微博关注人时间轴列表、简单队列等):列表是有序且可重复的,使用双向链表实现,两头快,中间慢
A. lpush key value1 [value2]:将一个或多个值插入到列表头部(左边);
B. rpop key:移除并获取列表的尾部(右边)的一个元素;
C. rpush key value1 [value2]:将一个或多个值插入到列表尾部(右边);
D. lpop key:移除并获取列表头部(左边)的一个元素;
E. llen key:获取列表长度。
7. hash命令(存储用户信息、用户主页访问量、组合查询等):适用于存储对象,是一个string类型的field和value的映射表
A. hset key field value:将hash表key中的字段field的值设为value;
B. hget key field:获取存储在hash表中指定字段的值;
C. hdel key field1 [field2]:删除一个或多个hash表字段;
D. hlen key:获取hash表中字段的数量。
8. Bitmap位图(签到统计、判断用户登录状态):通过一个bit位(0|1)来表示某个元素对应的值或者状态,其中key就是对应元素本身,下标叫偏移量;
A. setbit key offset vale:对key所存储的字符串值,设置或清除指定偏移量上的位,返回值是原来存储的位,若对字符串值进行延伸时,空白位置以0填充;
B. getbit key offset:对key所存储的字符串值,获取指定偏移量上的位;
C. bitcount key start:计算给定字符串中,被设置为1的比特位的数量;
D. bitop operation destkey key [key ...]:对一个或多个保存二进制的字符串key进行位元操作,并将结果保存到destkey上。
三、key过期策略
1. 作用:清理Redis中缓存的过期key,注意key到期后,redis并不是立即将过期的key删除;
2. 策略分类
A. 立即删除:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除,该策略可以立即清除过期的数据,对内存很友好,但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量;
B. 惰性删除:当你访问某个key的时候,Redis才会先检查是否过期,如果过期了就将对应的key删除,该策略可以最大化地节省CPU资源,却对内存非常不友好,极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存;
C. 定期删除:默认每1000ms随机获取设置了过期时间的部分key,如果已经过期就将对应的key删除,该策略是前两者的一个折中方案,通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果;
注意:Redis同时采用了定期删除+惰性删除两种策略。
四、内存淘汰机制
1. 作用:当Redis最大内存大小不足以容纳新写入数据时,就会执行内存淘汰机制;
2. 内存大小查看/修改
A. redis.conf配置文件: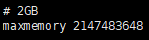
B. 命令行:config get maxmemory / config set maxmemory 2gb;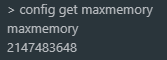
3. 淘汰策略分类
不淘汰:
A. noeviction(默认策略):对于写操作不再提供服务,直接返回错误(DEL请求和部分特殊请求除外);
对设置了过期时间的数据进行淘汰:
B. volatile-lru(建议使用):在设置了过期时间的键空间中,移除最近最少使用的key;
C. volatile-random:在设置了过期时间的键空间中,随机移除某个key;
D. volatile-ttl:在设置了过期时间的键空间中,越早过期的key越优先被淘汰;
E. volatile-lfu(Redis 4.0):在设置了过期时间的键空间中,使用LFU算法淘汰key;
对所有数据淘汰:
F. allkeys-lru:在所有键空间中,移除最近最少使用的key;
G. allkeys-random:在所有键空间中,随机移除某个key;
H. allkeys-lfu(Redis 4.0):在所有键空间中,使用LFU算法淘汰数据;
4. 淘汰策略查看/修改
A. redis.conf配置文件:![]()
B. 命令行:config get maxmemory-policy / config set maxmemory-policy volatile-lru;
5. LRU算法
A. 定义:LRU(Least Recently Used),指如果一个数据在最近一段时间没有被用到,那么将来被使用到的可能性也很小,所以就可以被淘汰掉;
B. Redis中LRU:Redis使用的是近似LRU算法,是通过随机采样法淘汰数据,每次随机取出默认值5个key,从里面淘汰掉最近最少使用的key,可以设置采集数:maxmemory-samples 10;
C. 另外Redis 3.0对近似LRU算法做了优化;
6. LFU算法
A. 定义:LFU(Least Frequently Used),指根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来;
B. 优点:LFU算法能更好的表示一个key被访问的热度,因为基于访问频率衡量的,对于LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了。
五、持久化
1. 方式
A. RDB内存快照:RDB全称是Redis Database Backup,指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储;
B. AOF日志文件(默认关闭):AOF全称是Append Only File,指以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
2. RDB
A. 触发方式
分手动触发:通过bgsave命令生成RDB文件;
自动触发:save <seconds> <changes>,当满足一定时间值和一定数量写操作的情况下,Redis会将数据存储到硬盘;
B. 配置项

C. 优点
当实例宕机恢复时,加载RDB文件的速度很快,能够在很短时间内迅速恢复文件中的数据;
RDB文件数据是被压缩写入的,因此RDB文件的体积要比整个实例内存要小;
D. 缺点
由于是某一时刻的数据快照,故可能会发生数据丢失;
生成RDB文件的代价是比较大的,它会消耗大量的CPU和内存资源;
E. 应用场景
主从全量同步数据;
数据库备份;
对于丢失数据不敏感的业务场景,实例宕机后快速恢复数据;
3. AOF
A. 配置项

B. AOF重写:可以设置在AOF文件很大时,自动触发AOF重写,Redis会扫描整个实例的数据,重新生成一个AOF文件达成瘦身的效果;
C. 优点
数据文件更新比较及时,保存数据完整性强,降低丢失数据的风险;
注意:如果同时存在RDB文件和AOF文件,Redis在服务器启动时会优先使用AOF文件进行数据恢复,因为数据完整。
D. 缺点
随着时间增长,AOF文件会越来越大;
AOF文件刷盘会增加磁盘IO的负担,可能影响Redis的性能(开启每秒刷盘时);
E. 应用场景:涉及金钱交易的业务。
可参考:Redis持久化
六、事务
1. 定义:事务执行过程将一系列多个命令按照顺序一次性执行,并且在执行期间,事务不会被中断,也不会去执行客户端的其他请求,直到所有命令执行完毕;
2. 命令
A. MULTI
B. EXEC
C. WATCH
3. 工作原理
A. 服务端收到客户端请求,事务以MULTI开始;
B. 如果客户端正处于事务状态,则会把事务放入队列同时返回给客户端QUEUED,反之则直接执行这个命令;
C. 当收到客户端EXEC命令时,WATCH命令监视整个事务中的key是否有被修改,如果有则返回空回复到客户端表示失败,否则redis会遍历整个事务队列,执行队列中保存的所有命令,最后返回结果给客户端,WATCH的机制本身是一个CAS的机制,被监视的key会被保存到一个链表中,如果某个key被修改,那么REDIS_DIRTY_CAS标志将会被打开,这时服务器会拒绝执行事务。
七、分区
1. 定义:分区是分割数据到多个redis实例的处理过程,因此每个实例只保存key的一个子集;
2. 分区意义:处理高并发和占用内存大问题,Redis集群就是分区的一种体现;
3. 分类
A. 范围分区:分配一定范围的对象到特定的Redis实例;
B. 哈希分区:利用hash函数将key转化为数字,哈希分区规则又包括节点区域分区、一致性哈希分区、虚拟槽分区;
可参考:Redis中方官网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号