

Elasticsearch 核心原理及高级特性
一、核心知识点
1. 搜索引擎原理
A. 查询分析:用自然语言处理技术做用户输入查询语句的拼写纠错或口语化处理,以正确理解用户需求;
B. 分词技术:利用自然语言处理技术将用户输入的查询语句进行分词,如中文分词常用IK分词器;
C. 关键词检索:将关键词在倒排索引库中进行匹配;
D. 搜索排序:对多个相关文档进行相关度计算、排序、返回给用户检索结果。
2. 倒排索引
倒排索引是 ES 的核心数据结构。与传统的正向索引(通过文档 ID 查找文档内容)不同,倒排索引是通过词条(Term)来查找包含该词条的文档。例如,对于一个包含多篇文档的文本集合,倒排索引会记录每个单词(词条)在哪些文档中出现。
3. 数据写入过程(write -> refresh -> flush -> merge)
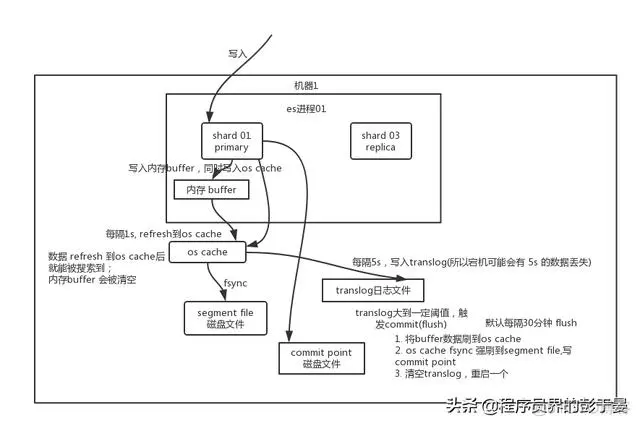
A. 客户端任选一个协调节点发送请求,数据经过hash后,找到主分片的node,然后对文档进行route,转发给对应node,主分片处理写请求后,同步给副本,保证一个副本返回成功,就响应结果给客户端;
B. 先把数据写到内存buffer上,当buffer快满或默认每隔1s后会刷到文件系统缓存区os cache上,在文件缓存区生成segment文件;(ES是近实时的原因就是只有在写入到文件系统的缓存区之后,数据才能被查到)
C. 为防止宕机丢失内存数据,在写入buffer时,还会写入到事务日志的buffer中,这个日志是个增量的追加日志,所以写入是比较快的,但是默认每隔5s才会同步到磁盘上translog文件;(如果机器宕机,可能会造成5s的数据丢失)
D. 等到磁盘上的日志文件达到一定程度或者时间满30分钟,触发一个commit操作,会把内存中的segment文件刷入到磁盘中,其实原理就是生成数据持久的镜像,然后再去只记录追加的数据。
4. 数据更新与删除过程
A. 数据更新:commit的时候会生成一个.del文件(磁盘),里面将某个doc标识为deleted状态,那么搜索的时候根据.del文件就知道这个doc被删除了;
B. 数据删除:将原来的doc标识为deleted状态,然后新写入一条数据。
5. 数据检索查询过程
A.
B.
C.
6. 相关性评分
A. 词频(TF):词频是指一个词条在文档中出现的频率。在计算相关性时,一个词条在文档中出现的次数越多,该文档与该词条的相关性可能越高。
B. 逆文档频率(IDF):逆文档频率用于衡量一个词条的稀有程度。如果一个词条在很多文档中都出现,那么它的 IDF 值较低,说明这个词条对于区分文档的作用较小。相反,如果一个词条只在少数文档中出现,它的 IDF 值较高,在相关性计算中有更大的权重;
C. 相关性计算公式:基本的公式是相关性得分 = TF * IDF;
二、高级特性
1. 跨集群复制:CCR 是一种用于在多个 Elasticsearch 集群之间复制数据的机制。它允许将一个集群(称为源集群)中的索引数据复制到另一个集群(称为目标集群)。这对于灾难恢复、数据备份以及在不同数据中心之间分发数据等场景非常有用。
2. 自动数据分层:自动数据分层是一种根据数据的访问频率和重要性等因素,将数据自动分配到不同存储层的特性。它有助于优化存储成本和查询性能,因为频繁访问的数据可以存储在高性能存储介质(如 SSD)上,而不常访问的数据可以存储在成本较低的存储介质(如 HDD)上;
3. 向量搜索:向量搜索是 ES 用于处理高维向量数据的一种搜索方式。在自然语言处理、图像识别等领域,数据通常以向量的形式表示(如词向量、图像特征向量等)。向量搜索可以根据向量之间的相似度(如余弦相似度)来查找最相似的文档或数据点;
三、分词器
分词器是用于将文本数据划分为一系列的单词的组件,分词器通常包含字符过滤器、分词器和词项过滤器三个部分。
1. 分类
A. 标准分词器(Standard Tokenizer)
B. 关键字分词器(Keyword Tokenizer)
C. IK分词器:ES默认的内置分词器对中文的分词效果不太好,而IK是一个开源的中文分词器插件,能够根据中文语言习惯进行精细的分词。
2. IK分词器
A. 安装部署:下载IK分词器源码某个版本的zip包,解压后放入/usr/share/elasticsearch/plugins/ik目录,重新启动ES服务即可。
B. IK对应文件描述:
IKAnalyzer.cfg.xml:IK分词配置文件;
main.dic:主词库;
C.IK自定义词库:
D. 热更新:基于远程词库和数据库
四、优化
1. 硬件选择:所有的索引和文档数据是存储在磁盘中,故磁盘能处理的吞吐量越大,节点就越稳定;
A. 使用SSD;
B. 使用RAID0,不丢失数据靠副本保障;
C. 使用多块硬盘;
D. 不要使用远程挂载的存储,如NFS;
2. 分片策略
A. 合理设置分片数:分片数一旦确定就无法修改,是在创建索引时就确定好了,但是副本可以动态修改,一般分片数不超过节点数的3倍,满足:节点数 <= 主分片数 * (副本数 + 1);
B. 推迟分片分配:对于节点瞬时中断的问题,过一会又加入,可以保持现有分片数据,可以减少ES自动再平衡带来的开销,参数为delayed_timeout;
3. 路由选择:shard=hash(routing) % number_of_primary_shards,routing默认值为文档ID
A. 不带routing查询:涉及请求分发每个分片,然后数据聚合排序;
B. 带routing查询:指定到对应分片,可以提升查询效率;
4. 写入速度优化
A. 批量数据提交:提交的数据量不要超过100M
B. 优化存储设备:密集使用磁盘,故磁盘性能提高就会提高写入效率;
C. 合理使用合并:合并次数越多,写入效率越低;
D. 减少Refresh的次数:需要增大Index Refresh的间隔
E. 加大Flush的设置:目的是降低Iops
F. 减少副本的数量:副本越多,写索引的效率就越低,如果有大批量写入操作,可以先禁止replica复制,设置index.number_of_replicas=0
5. 内存设置:默认1G,不要超过物理内存50%(另一半供Lucene操作系统缓存使用),最大值也不要超过32G,可jvm.options文件改。
6. 缓存
A. 页缓存:从磁盘读取数据后将数据放入可用内存中,以便下次读取时从内存读取,故ES内存不能超过系统总内存一半;
B. 分片级请求缓存:ES可以在每个分片上缓存本地结果集,便于下次搜索立即返回,设置index.requests.cache.enable=true+请求路径携带request_cache=true参数;
C. 查询缓存:
可参考:Elasticsearch详解


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗