

SpringBoot 整合Druid数据源
1. pom.xml Maven依赖
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.20</version>
</dependency>
2. application.yml 文件配置

spring: datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/user?autoReconnect=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai username: root password: rzx@1218 druid: # 初始化时建立物理连接的个数 initial-size: 1 # 最小连接池数量 min-idle: 1 # 最大连接池数量 max-active: 8 # 获取连接时最大等待时间,单位毫秒 max-wait: 3000 # 间隔多久检测需要关闭的空闲连接 time-between-eviction-runs-millis: 10000 # 连接保持空闲而不被驱逐的最小时间 min-evictable-idle-time-millis: 5000 # 用来检测连接是否有效的sql validation-query: select 1 # 检测连接是否有效的超时时间 validation-query-timeout: 3000 test-while-idle: true test-on-borrow: false test-on-return: false
3. 旧版本的Druid监控配置
# 监控配置 启用相应的内置Filter,多个以逗号分隔 spring.datasource.druid.filters=stat, wall # 配置StatFilter spring.datasource.druid.filter.stat.db-type=mysql spring.datasource.druid.filter.stat.log-slow-sql=true spring.datasource.druid.filter.stat.slow-sql-millis=1000 # 配置WallFilter spring.datasource.druid.filter.wall.enabled=true
4. DruidConfig配置类,新版本可以采用配置文件替代
package com.ruhuanxingyun.config; import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.support.http.StatViewServlet; import com.alibaba.druid.support.http.WebStatFilter; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.boot.web.servlet.ServletRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import javax.sql.DataSource; import java.util.Arrays; import java.util.HashMap; import java.util.Map; /** * @description: 阿里数据源配置 * @author: ruphie * @date: Create in 2020/1/11 14:31 * @company: ruhuanxingyun */ @Configuration public class DruidConfig { @ConfigurationProperties(prefix = "spring.datasource") @Bean public DataSource dataSource() { return new DruidDataSource(); } @Bean public ServletRegistrationBean servletRegistrationBean() { ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*"); Map<String, String> map = new HashMap<>(); map.put("loginUsername", "admin"); map.put("loginPassword", "123456"); servletRegistrationBean.setInitParameters(map); return servletRegistrationBean; } @Bean public FilterRegistrationBean filterRegistrationBean() { FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter()); Map<String, String> map = new HashMap<>(); map.put("exclusions", "*.js,*.css,/druid/*"); filterRegistrationBean.setInitParameters(map); filterRegistrationBean.setUrlPatterns(Arrays.asList("/*")); return filterRegistrationBean; } }
5. 监控
A. Druid监控访问地址:http://服务ip:服务端口/druid/index.html;

6. 连接池测试
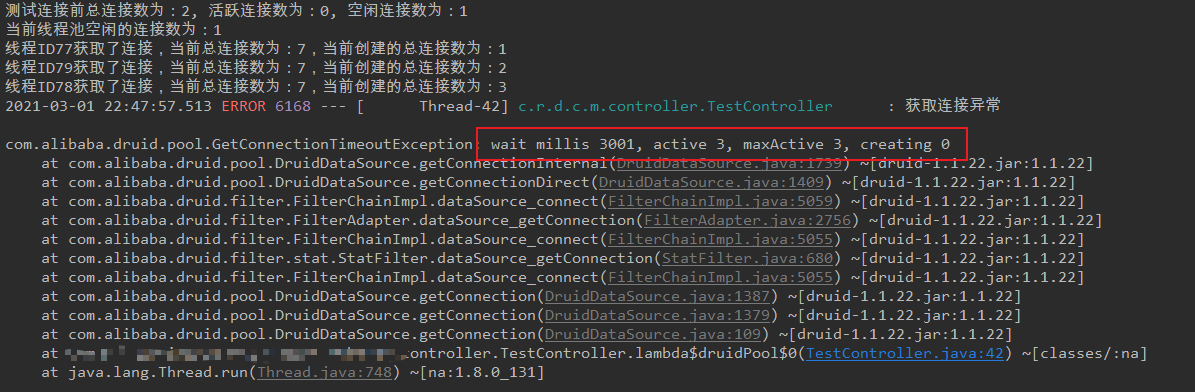
package com.ruhuanxingyun.dcy.common.mybatis.controller; import com.alibaba.druid.pool.DruidDataSource; import com.ruhuanxingyun.dcy.common.tool.model.Result; import com.ruhuanxingyun.dcy.common.tool.model.ResultBuilder; import io.swagger.annotations.Api; import io.swagger.annotations.ApiOperation; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.sql.DataSource; import java.sql.Connection; /** * @description: 测试 控制层 * @author: ruphie * @date: Create in 2021/3/1 21:55 * @company: ruhuanxingyun */ @RestController @RequestMapping("/api/1.0/test") @Slf4j @Api(tags = "Druid连接池") public class TestController { @Autowired private DataSource dataSource; @GetMapping("/druidPool") @ApiOperation("Druid连接池测试") public Result<Void> druidPool() { DruidDataSource druidDataSource = (DruidDataSource) dataSource; System.out.println(String.format("测试连接前总连接数为:%d, 活跃连接数为:%d, 空闲连接数为:%d", druidDataSource.getConnectCount(), druidDataSource.getActiveCount(), druidDataSource.getPoolingCount())); for (int i = 1; i <= 5; i++) { new Thread(() -> { long id = Thread.currentThread().getId(); try { Connection connection = dataSource.getConnection(); System.out.println(String.format("线程ID%d获取了连接,当前总连接数为:%d,当前创建的总连接数为:%d", id, druidDataSource.getConnectCount(), druidDataSource.getCreateCount())); Thread.sleep(5000); connection.close(); System.out.println(String.format("线程ID%d释放了连接,当前总连接数为:%d,当前关闭的总连接数为:%d", id, druidDataSource.getConnectCount(), druidDataSource.getCloseCount())); } catch (Exception e) { log.error("获取连接异常", e); System.out.println(String.format("线程ID%d获取连接异常,当前错误的总连接数为:%d", id, druidDataSource.getConnectErrorCount())); } }).start(); } boolean status = true; while (status) { try { System.out.println(String.format("当前线程池空闲的连接数为:%d", druidDataSource.getPoolingCount())); if (druidDataSource.getMinIdle() == druidDataSource.getPoolingCount()) { status = false; } Thread.sleep(5000); } catch (InterruptedException e) { log.error("线程休眠异常", e); } } return ResultBuilder.build(); } }
可参考:Druid官网地址
配置详解:https://blog.csdn.net/hj7jay/article/details/51686418
连接池比较:https://blog.csdn.net/fysuccess/article/details/66972554
分类:
SpringBoot


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗