
何谓domReady
我的博客已经写过好几篇如何实现domReady的文章,最近做培训,面向新手们,需要彻彻底底向他们说明这个东西,于是就有了这篇文章。
我们经常看人们用
document.getElementById("xxx").style.left = "80px"
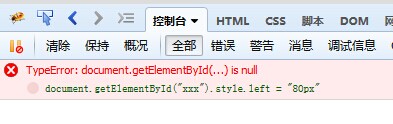
报错,说找不到元素.但明明页面上有包含xxx这个ID的元素的
这其实就是分不清HTML标签与DOM节点之故了。
HTML是一种标记语言, 告诉我们这页面有什么内容。 但行为交互是需要通过DOM操作实现, 不要以后那两个尖括号的内容就是一个DOM
HTML标签要通过浏览器解析才会变成DOM节点。
当我们向地址栏传入一个URL, 开始加载页面到我们看到内容,这期间就有一个DOM节点构建的过程。
节点们是以树的形式组织的, 当页面上所有HTML都转换为节点, 这就叫做DOM树建完, 简称之domReady。
HTML转换DOM是一个非常复杂的过程,想深入的同学可以看一下这个地址
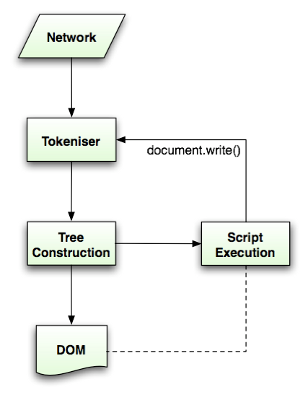
我们简单说一下, 浏览器是从上到下, 从左到右,一个个字符串读入, 大致可以认为两个同名的开标签与闭标签就是一个DOM(有的是没有闭签),这时就忽略掉它的两个标签间的内容。页面上有许多标签, 但标签会生成同样多的DOM,因为有的标签下只允许存在特定的子标签, 比如tr下面一定是td,th, select下面一定是opgroup,option,而option下面,就算你写了<span></span>,它都会忽略掉,option下面只存在文本,这就是我们需要自定义下拉框的缘故. 我们说过, 这顺序是从上到下, 有的元素很简单,会构建得很快,但标签存在src, href属性,它会引用外部资源,这就要区别对待了.比如说, script标签,它一定会等src指定的脚本文件加载下来,然后全部执行了里面的脚本,才会分析下一个标签.这种现象叫做堵塞.
堵塞是一种非常致命的现象,因为浏览器渲染引擎是单线程的,如果头部脚本过多过大会导致白屏,影响用户体验,因此雅虎的20军规就有一条提到 ,将所有script标签放到body之后.
此外, style标签与link标签,它们在加载样式文件时是不会堵塞,但它们一旦异步加载好,就立即开始渲染已经构建好的元素节点们, 这可能会引起reflow, 这也影响速度.
另一个影响DOM树构建的因此是iframe,它也会加载资源, 虽然不会堵塞DOM构建,但它由于是发出HTTP请求,而HTTP请求是有限,它会与父标签的其他需要加载外部资源的标签产生竞争。我们经常看到一些新闻网,上面会挂许多iframe广告, 这些页面一开始加载时就很卡,也是这缘故.
此外还有object元素, 用来加载flash
等等,这些东西都会影响到DOM树的构建过程.因此在这时候,当我们贸贸然,使用getElementById, getElementsByTagName获取元素,然后操作它们, 就会有很大机率碰到 元素为null的 异常. 这时, 目标元素还可以没有转换为DOM节点, 还只是一个普通的字符串呢!
我们又不能随意写一个
setTimeout(function(){
document.getElementById("xxx").style.left = "80px"
}, 3000)
这完全是靠蒙, 可能有效, 也可能失败. 因此获得 所有标签都转换为DOM节点的时机就非常重要.
很早期, 浏览器提供了一个window.onload方法,但这东西是等到所有标签变成DOM,并且外部资源,图片,背景音乐什么都加载好才触发, 时间上有点晚.
幸好,浏览器提供了一个document.readyState属性,当它变成complete时,说明这时机到了
但这是一个属性,不是一个事件,需要使用不太精确的setInterval轮询
在标签浏览器, W3C终于绅士地提供了一个DOMContentLoaded事件;在旧式IE下,也可以勉强使用onreadystatechange事件模拟, 直接某一天,有个外国大牛发掘出doScroll这个伟大的hack, 它让我们在IE下更接近DOMContentLoaded的效果
function IEContentLoaded (w, fn) {
var d = w.document, done = false,
// 只执行一次用户的回调函数init()
init = function () {
if (!done) {
done = true;
fn();
}
};
(function () {
try {
// DOM树未创建完之前调用doScroll会抛出错误
d.documentElement.doScroll('left');
} catch (e) {
//延迟再试一次~
setTimeout(arguments.callee, 50);
return;
}
// 没有错误就表示DOM树创建完毕,然后立马执行用户回调
init();
})();
//监听document的加载状态
d.onreadystatechange = function() {
// 如果用户是在domReady之后绑定的函数,就立马执行
if (d.readyState == 'complete') {
d.onreadystatechange = null;
init();
}
};
}
这里有一些主流框架对domReady的实现
其实都大同小异, 关键是 设置一个数组, 当domReady这个时刻没有到时,先将回调放到数组里; 然后是各种检测domReady的方法(如DOMContentLoaded, onreadystatechange, doScroll hack, document.readyState轮询 ), 一旦到了,就执行这个数组所有回调, 并且以后用户再进入这个方法, 就不放数组,直接执行.
上完这课,以后大家操作节点的逻辑,一定要写在domReady回调中啊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号