SQL Server表水平分区
随着项目的运行时间越来越久,数据库的数据会越来越多,某些表因为数据量的变大查询起来会很慢,而且拥有大量数据的表整张表的数据都存于一个mdf文件中,不利于数据文件的维护和管理,我们一般都会通过优化sql,添加合适的索引来初步的优化我们的查询效率
但今天这里介绍另一种单表数据量过大的性能优化方案:水平分表;
1、分区表介绍
1.1 分表
当一张表中的数据有几百万,几千万甚至上亿的时候,对于这种表想要快速查询指定的数据单单通过sql的优化和添加索引肯定是不够的,我们可以想到的优化方案就是把拥有大量数据大表按照一定的条件顺序拆分成为多个小表,通过这样使单表数据减少,从而可以使我们查询数据是只去查指定的表,来达到优化性能的效果,但是显而易见这样的拆分表的方式,是不易维护,假如我们把一张2010到2019数据组成的大表以数据的创建时间为条件,按年份拆分成了table2010,table2011.....table2018,table2019十张独立的表来分别管理,如果我们只会查询近期的数据(table2019)这种方式看似好像是可行的,但是一旦要增删改查历史数据的时候,可以想到这种粗暴的表拆分会使开发人员在编写多条件查询逻辑的时候会加大对sql的维护难度。
1.2 分区表
那么有什么方法可以从物理上将一个大表分成几个小表,但是从逻辑上来看,还是一个大表?
答案就是使用分区表,我们常规的表的数据是一存储在数据库的mdf文件中的,一般用来存储数据库的硬盘都是采用读写较快的固态硬盘,但是即使是固态硬盘,单张固态硬盘读写肯定还是有峰值的,但是分区表可以将原来的单个表mdf文件拆分成多个ndf文件保存到不同的独立硬盘当中,所以如果我们把拆分后的多个ndf文件配置到不同的独立硬盘中去,多个硬盘的读取性峰值能肯定是大于单个硬盘的,从而查询效率可以得到提升。
2、分区表具体操作
2.1 创建数据库文件组(窗体操作创建和代码直接创建两种方案)
我们可以通过视图操作的方式创建文件组,选择数据库右键=》文件组,添加完成确认保存
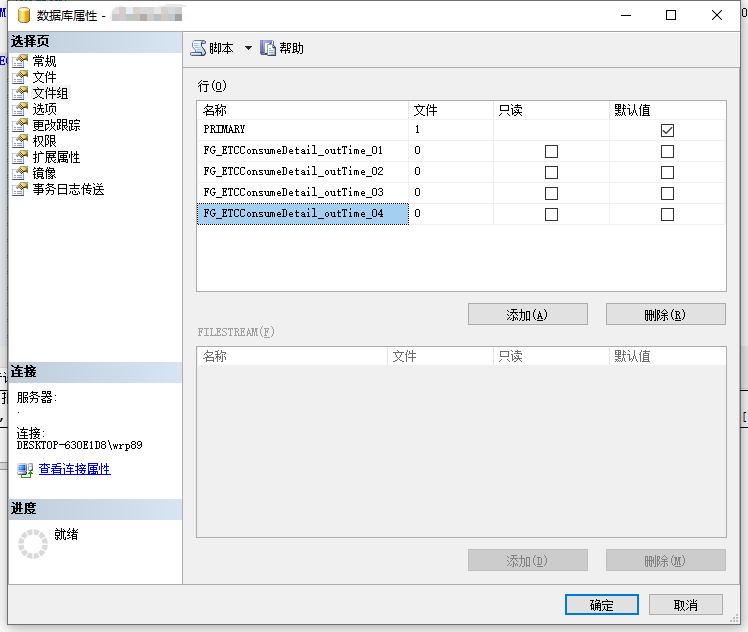
我们打开可以看到已经有一个PRIMARY文件组,文件数为1,一个文件组是可以对应多个数据库文件的,我们其实可以不用创建文件组直接使用PRIMARY,但是我们为了便于方便管理,以及便于此处的理解,此处重新创建了FG_ETCConsumeDetail_outTime_01,02,03,04四个文件组,此时我们可以看到每个文件组对应的文件数为0
当然我们也可以直接用代码实现创建文件组:
--1.创建文件组 ALTER DATABASE [YLTD2] --数据库名称 ADD FILEGROUP [FG_ETCConsumeDetail_outTime_01] --文件组名称 ALTER DATABASE [YLTD2] ADD FILEGROUP [FG_ETCConsumeDetail_outTime_02] ALTER DATABASE [YLTD2] ADD FILEGROUP [FG_ETCConsumeDetail_outTime_03] ALTER DATABASE [YLTD2] ADD FILEGROUP [FG_ETCConsumeDetail_outTime_04]
2.2 为文件组添加文件(视图操作和代码直接实现两种方式)
然后我们为每个文件组添加一个文件,添加的文件即为我们存储分区表数据的文件路径,此时如果我们有多个独立的磁盘,我们可以将分区表文件分别配置到不同的磁盘,此处只是举例学习,就都配置在了同一个文件夹下面,配置完成后我们查看硬盘配置目录,可以看到我们创建的四个ndf文件。
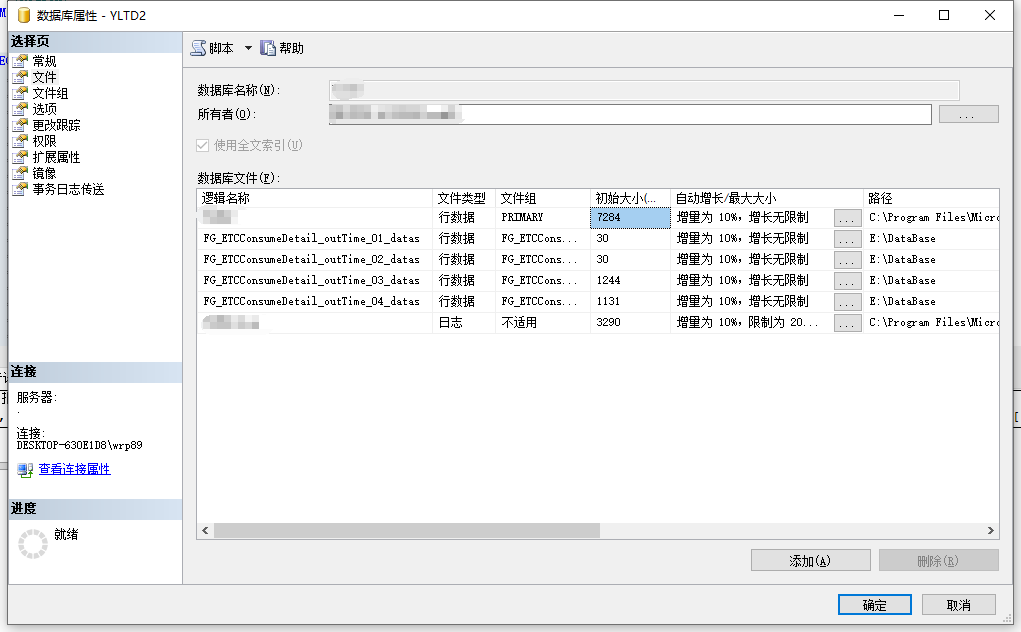
用代码实现如下:
--2.创建文件 ALTER DATABASE [YLTD2] --数据库名称 ADD FILE (NAME = N'FG_ETCConsumeDetail_outTime_01_datas',FILENAME = N'E:\DataBase\FG_ETCConsumeDetail_outTime_01_data.ndf',SIZE = 30MB, FILEGROWTH = 10% ) --(分区段名称,路径,文件初始大小,分区文件增量) TO FILEGROUP [FG_ETCConsumeDetail_outTime_01]; --文件组名称 ALTER DATABASE [YLTD2] ADD FILE (NAME = N'FG_ETCConsumeDetail_outTime_02_datas',FILENAME = N'E:\DataBase\FG_ETCConsumeDetail_outTime_02_data.ndf',SIZE = 30MB, FILEGROWTH = 10% ) TO FILEGROUP [FG_ETCConsumeDetail_outTime_02]; ALTER DATABASE [YLTD2] ADD FILE (NAME = N'FG_ETCConsumeDetail_outTime_03_datas',FILENAME = N'E:\DataBase\FG_ETCConsumeDetail_outTime_03_data.ndf',SIZE = 30MB, FILEGROWTH = 10% ) TO FILEGROUP [FG_ETCConsumeDetail_outTime_03]; ALTER DATABASE [YLTD2] ADD FILE (NAME = N'FG_ETCConsumeDetail_outTime_04_datas',FILENAME = N'E:\DataBase\FG_ETCConsumeDetail_outTime_04_data.ndf',SIZE = 30MB, FILEGROWTH = 10% ) TO FILEGROUP [FG_ETCConsumeDetail_outTime_04];
2.3 创建分区函数
分区函数作用是确定大表的数据按照那个字段、以怎样的条件区分到各个小表,我们可以按照数据创建时间,ID,等等条件区分,如下:
下面代码我们以字段outTime按照年份区分数据
--3.创建分区函数 CREATE PARTITION FUNCTION --创建一个分区函数。 Fun_ETCConsumeDetail_outTime(datetime) AS --分区函数名(分区字段数据类型) AS RANGE RIGHT --设置分区范围的方式为Right,右置 FOR VALUES('2017-01-01','2018-01-01','2019-01-01') --此处按年限分区
将大表如此分区后的数据结果是:
- 分区表一:2017-01-01以前的所有数据(不包括2017-01-01)
- 分区表一:2017-01-01到2018-01-01的所有数据(包括2017-01-01,不包括2018-01-01)
- 分区表一:2018-01-01到2019-01-01的所有数据(包括2018-01-01,不包括2019-01-01)
- 分区表一:2019-01-01以后是所有数据 (包括2019-01-01)
需要注意的两个问题
(1)现有的所有数据按照如上分区,如果以后有数据插入也会按照如上分区自动录入到对应的分区,修改数据数据库也会自动调整数据的分区位置;
(2)上面括号中的包括和不包括就是设置分区范围为右置所造成的效果,如果设置成LEFT效果反之
2.4 创建分区方案
分区方案的作用是将分区函数生成的分区映射到文件组中去,让分区数据与我们之前建立的文件组建立关系
--4.创建分区方案 CREATE PARTITION SCHEME --创建一个分区方案。 Sch_ETCConsumeDetail_outTime AS --分区方案名 AS PARTITION Fun_ETCConsumeDetail_outTime --PARTITION 关联分区函数名 TO([FG_ETCConsumeDetail_outTime_01],[FG_ETCConsumeDetail_outTime_02],[FG_ETCConsumeDetail_outTime_03],[FG_ETCConsumeDetail_outTime_04]) --文件组
按上述步骤创建完成后,我们可以到存储中看到我们创建好的分区函数和分区方案
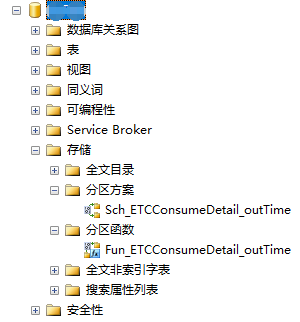
2.5 创建分区表
前面的所有操作其实都是创建分区表的准备工作,最后我们再来创建分区表
CREATE TABLE ETCConsumeDetail( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [varchar](16) NOT NULL, [outTime][datetime] NOT NULL ) ON Sch_ETCConsumeDetail_outTime([outTime]) --ON 分区方案名称(分区条件字段)
完成后我们右键我们创建的分区表=》储存,查看已为分区表为True说明分区表创建成功
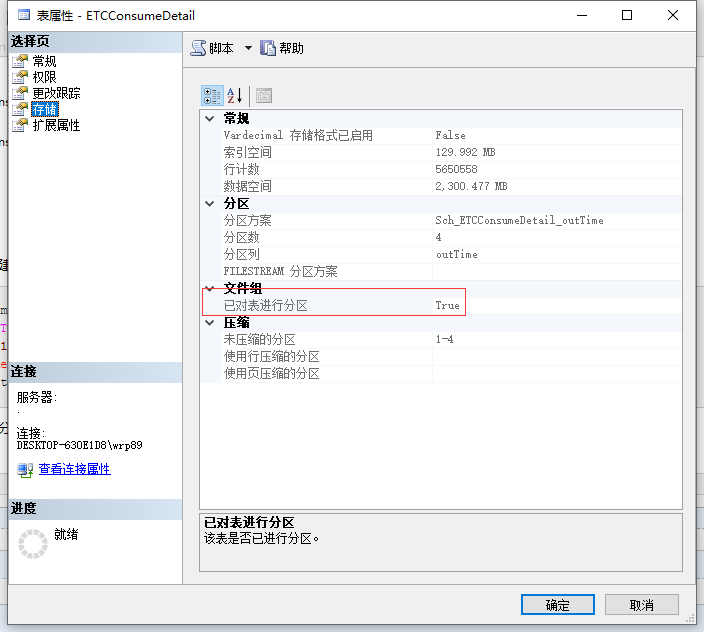
2.6 将现有表转换成分区表
很多情况下我们的表都是已经使用了一段时间,而且数据量比较大了才考虑到分表的,那么我们如何将普通的表转换为分区表呢?
首先我们还是需要做上面的四个步骤:创建文件组,文件组添加文件,创建分区函数,创建分区方案
然后一切完成后,我们通常使用的表通常主键字段也为聚集索引,我们需要删除主键,重新创建为不为聚集索引
--删掉主键 ALTER TABLE ETCConsumeDetail DROP constraint PK_ETCConsumeDetail --创建主键,但不设为聚集索引 ALTER TABLE ETCConsumeDetail ADD CONSTRAINT PK_ETCConsumeDetail PRIMARY KEY NONCLUSTERED ( [ID] ASC ) ON [PRIMARY]
创建一个新的聚集索引,并在该聚集索引中使用分区方案,这样普通表就成功转换成为了分区表
CREATE CLUSTERED INDEX CT_ETCConsumeDetail_ ON ETCConsumeDetail(outTime) -- 表名(索引字段) ON Sch_ETCConsumeDetail_outTime(outTime) --分区方案(索引字段)
3、编写一个分区表脚本
如果分区表过多觉得上面前四部操作起来很麻烦容易出错
我们把上面分区表的前四个步骤编写成脚本,这个脚本可以直接根据配置生成脚本:
--生成分区脚本 DECLARE @DataBaseName NVARCHAR(50)--数据库名称 DECLARE @TableName NVARCHAR(50)--表名称 DECLARE @ColumnName NVARCHAR(50)--字段名称 DECLARE @PartNumber INT--需要分多少个区 DECLARE @Location NVARCHAR(50)--保存分区文件的路径 DECLARE @Size NVARCHAR(50)--分区初始化大小 DECLARE @FileGrowth NVARCHAR(50)--分区文件增量 DECLARE @FunValue INT--分区分段值 DECLARE @i INT DECLARE @PartNumberStr NVARCHAR(50) DECLARE @sql NVARCHAR(max) --设置下面变量 SET @DataBaseName = 'MyDataBase' SET @TableName = 'ETCConsumeDetail' SET @ColumnName = 'Id' SET @PartNumber = 4 SET @Location = 'E:\DataBase\' SET @Size = '30MB' SET @FileGrowth = '10%' SET @FunValue = 10000000 --1.创建文件组 SET @i = 1 PRINT '--1.创建文件组' WHILE @i <= @PartNumber BEGIN SET @PartNumberStr = RIGHT('0' + CONVERT(NVARCHAR,@i),2) SET @sql = 'ALTER DATABASE ['+@DataBaseName +'] ADD FILEGROUP [FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+']' PRINT @sql + CHAR(13) SET @i=@i+1 END --2.创建文件 SET @i = 1 PRINT CHAR(13)+'--2.创建文件' WHILE @i <= @PartNumber BEGIN SET @PartNumberStr = RIGHT('0' + CONVERT(NVARCHAR,@i),2) SET @sql = 'ALTER DATABASE ['+@DataBaseName +'] ADD FILE (NAME = N''FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'_data'',FILENAME = N'''+@Location+'FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'_data.ndf'',SIZE = '+@Size+', FILEGROWTH = '+@FileGrowth+' ) TO FILEGROUP [FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'];' PRINT @sql + CHAR(13) SET @i=@i+1 END --3.创建分区函数 PRINT CHAR(13)+'--3.创建分区函数' DECLARE @FunValueStr NVARCHAR(MAX) SET @i = 1 SET @FunValueStr = '' WHILE @i < @PartNumber BEGIN SET @FunValueStr = @FunValueStr + convert(NVARCHAR(50),(@i*@FunValue)) + ',' SET @i=@i+1 END SET @FunValueStr = substring(@FunValueStr,1,len(@FunValueStr)-1) SET @sql = 'CREATE PARTITION FUNCTION Fun_'+@TableName+'_'+@ColumnName+'(INT) AS RANGE RIGHT FOR VALUES('+@FunValueStr+')' PRINT @sql + CHAR(13) --4.创建分区方案 PRINT CHAR(13)+'--4.创建分区方案' DECLARE @FileGroupStr NVARCHAR(MAX) SET @i = 1 SET @FileGroupStr = '' WHILE @i <= @PartNumber BEGIN SET @PartNumberStr = RIGHT('0' + CONVERT(NVARCHAR,@i),2) SET @FileGroupStr = @FileGroupStr + '[FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'],' SET @i=@i+1 END SET @FileGroupStr = substring(@FileGroupStr,1,len(@FileGroupStr)-1) SET @sql = 'CREATE PARTITION SCHEME Sch_'+@TableName+'_'+@ColumnName+' AS PARTITION Fun_'+@TableName+'_'+@ColumnName+' TO('+@FileGroupStr+')' PRINT @sql + CHAR(13) --5.分区函数的记录数 PRINT CHAR(13)+'--5.分区函数的记录数' SET @sql = 'SELECT $PARTITION.Fun_'+@TableName+'_'+@ColumnName+'('+@ColumnName+') AS Partition_num, MIN('+@ColumnName+') AS Min_value,MAX('+@ColumnName+') AS Max_value,COUNT(1) AS Record_num FROM dbo.'+@TableName+' GROUP BY $PARTITION.Fun_'+@TableName+'_'+@ColumnName+'('+@ColumnName+') ORDER BY $PARTITION.Fun_'+@TableName+'_'+@ColumnName+'('+@ColumnName+');' PRINT @sql + CHAR(13)
跑出来的文本如下,然后复制这个文本执行
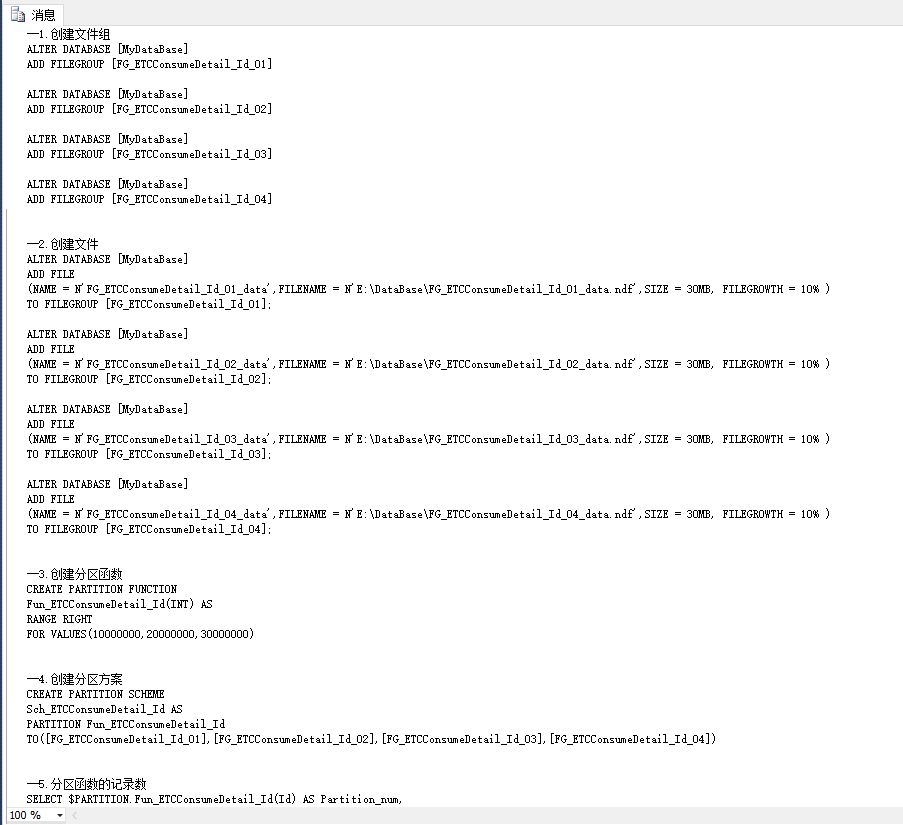
执行成功后即完成了分区表的前四步,后面就可以创建分区表或者将普通表转换成分区表
4、总结
(1)为什么要用表分区?当然最重要的是为了提升查询性能,但是分区表比较适合数据量大(至少一百万以上)且有部分历史不常用数据的表,如果你所用到的表数据量和业务场景都很小,使用分区表也许会让你得不偿失;
(2)如果把所有分区文件放在同一硬盘上面,这样实现的分区表查询性能有没有提升?如果查询条件没有以分区表指定的分区列(如上面例子的outTime列)做筛选,系统会从所有对分区进行筛选,查询效率应该是不会有什么提升的,但是如果使用了分区列作为筛选条件,数据库就会只查询指定分区中去筛选数据,查询性能也是会有提升的;
(3)最后简单说一下我个人对软件提升性能的看法:想要提升程序性能,需要有良好好的软件设计模式与架构,但是更重要的还是需要硬件的支持,以SQL查询优化为例:很多软件提升性能的方案如SQL优化,加索引只是尽可能的做到资源不被浪费,或者以时间换空间,但是假如你老板想要你在一台500G机械硬盘的家用电脑上完成秒级的千万条数据查询,你SQL写得在完美,索引创建的在合理也是基本无法实现的,一切不以硬件为基础的性能优化不亚于耍流氓。
参考资料:
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms190787(v=sql.105)
https://www.cnblogs.com/gaizai/archive/2011/01/14/1935579.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号