pycaret学习之关联规则挖掘
关联规则学习是一种基于规则的机器学习方法,用于发现大型数据库中变量之间的有趣关系。它旨在使用一些有趣的度量来识别数据库中发现的强规则。例如,在超市销售数据中找到的规则{洋葱,土豆} --> {汉堡}将表明,如果客户一起购买洋葱和土豆,他们很可能也会购买汉堡。此类信息可用作营销活动决策的基础,例如促销定价或产品植入。
PyCaret 的关联规则模块是一个监督式机器学习模块,用于发现数据集中变量之间的有趣关系。此模块自动将任何事务数据库转换为先验算法可接受的形状。Apriori 是一种对关系数据库进行频繁项目集挖掘和关联规则学习的算法。
三个判断准则:支持度(support)、置信度(confident)、提升度(lift)。
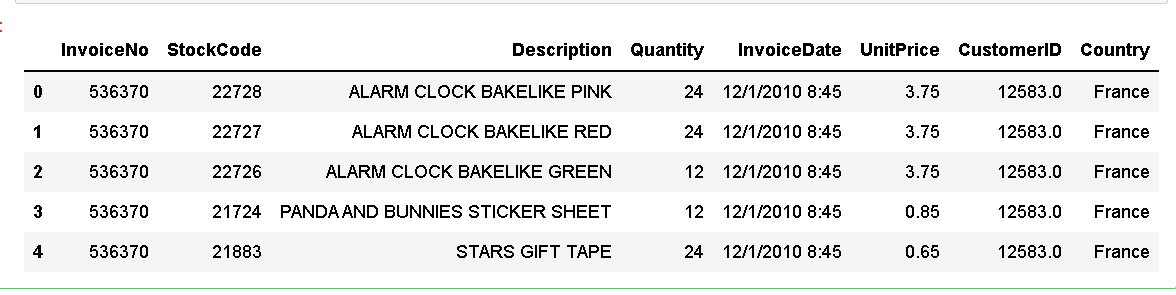
一、获取数据
from pandas import read_csv data = read_csv('C:\\Users\86152\pycaret\datasets\France.csv') data.head()
二、设置(set up())
setup()函数初始化 PyCaret 中的环境,并将事务数据集转换为 Apriori 算法可接受的形状。它需要三个必需参数:pandas dataframe,这是表示事务 ID 的列的名称,将用于透视矩阵;这是用于创建规则的列的名称。通常,这将是感兴趣的变量。您还可以传递可选参数以忽略某些值以创建规则.
from pycaret.arules import * exp_arul101 = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description')
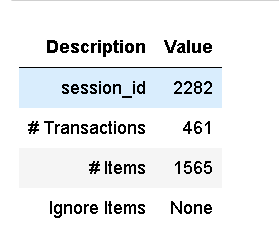
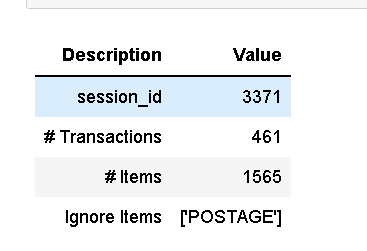
成功执行设置后,它将打印包含少量重要信息的信息网格:
- # Transactions:数据集中唯一的事务数。在这种情况下,唯一的.
InvoiceNo - # Items :数据集中的唯一项数。在这种情况下.
Description - Ignore Items :规则挖掘中要忽略的项目。很多时候,有些关系太明显了,你可能想忽略它们来进行这种分析。例如:许多事务数据集将包含运输成本,这是非常明显的关系,在使用参数时可以忽略。在本教程中,我们将运行两次,第一次不忽略任何项目,然后忽略项目。
三、创建模型
创建关联规则模型非常简单。 不需要强制参数。它有4个可选参数,如下所示:create_model()
- metric:用于评估规则是否感兴趣的指标。默认值设置为置信度。其他可用的指标包括“支持”、“提升”、“杠杆”、“信念”。
- threshold:评估指标的最小阈值,通过参数确定候选规则是否感兴趣。
- min_support:介于 0 和 1 之间的浮点数,表示对返回的项集的最小支持。支撑计算为分数。
- round:分数网格中的小数位数指标将四舍五入。
让我们创建一个包含所有默认值的关联规则模型。
model1 = create_model() print(model1.shape) model1.head()
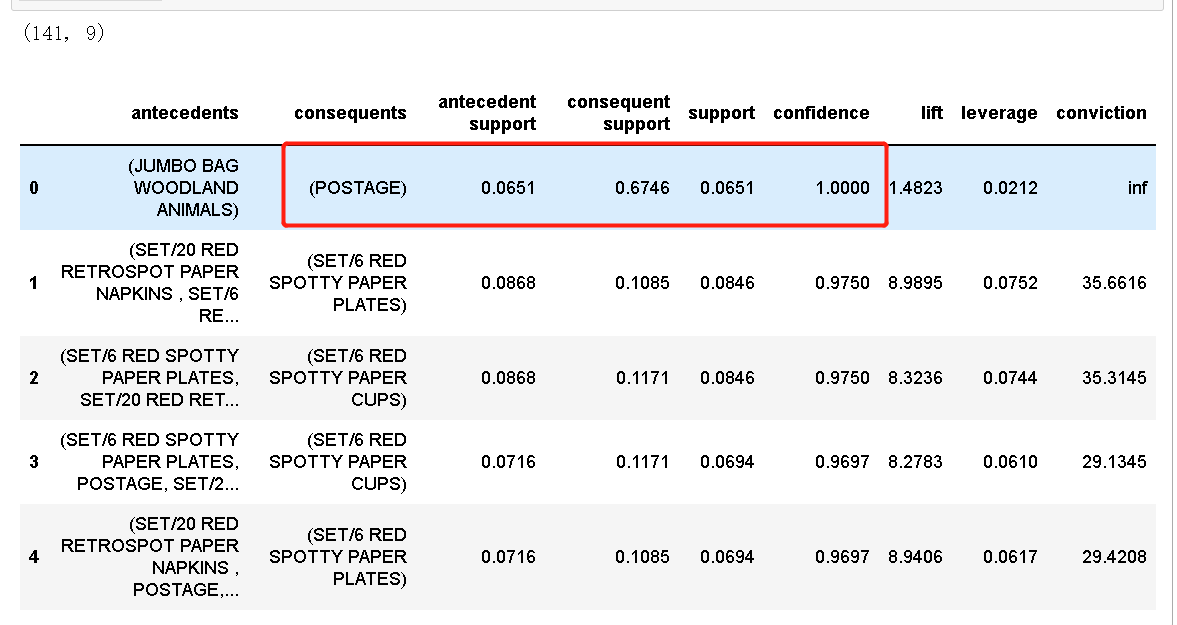
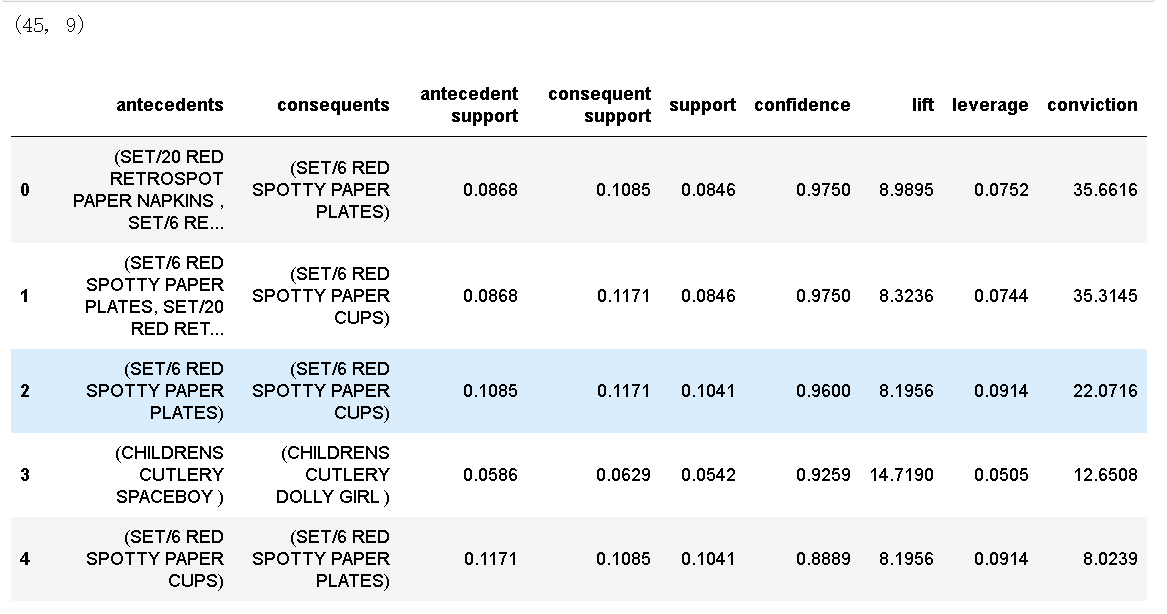
在上面创建的中,POSTAGE规则非常明显。在下面的示例中,我们将使用种的参数忽略数据集并重新创建关联规则模型。
exp_arul101 = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description', ignore_items = ['POSTAGE'])
model2 = create_model() print(model2.shape) model2.head()
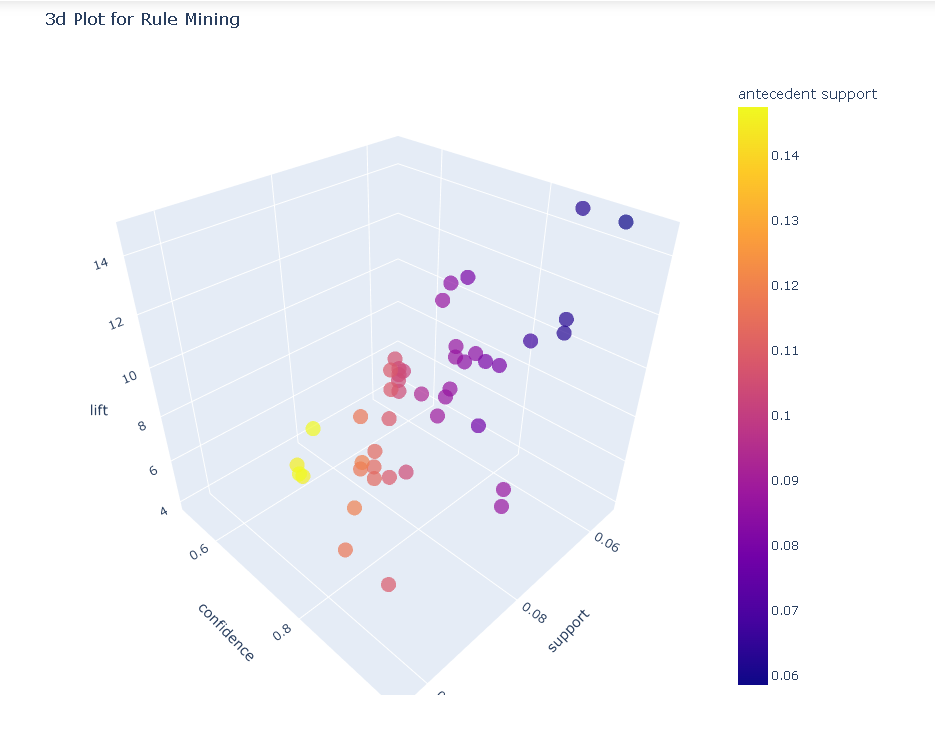
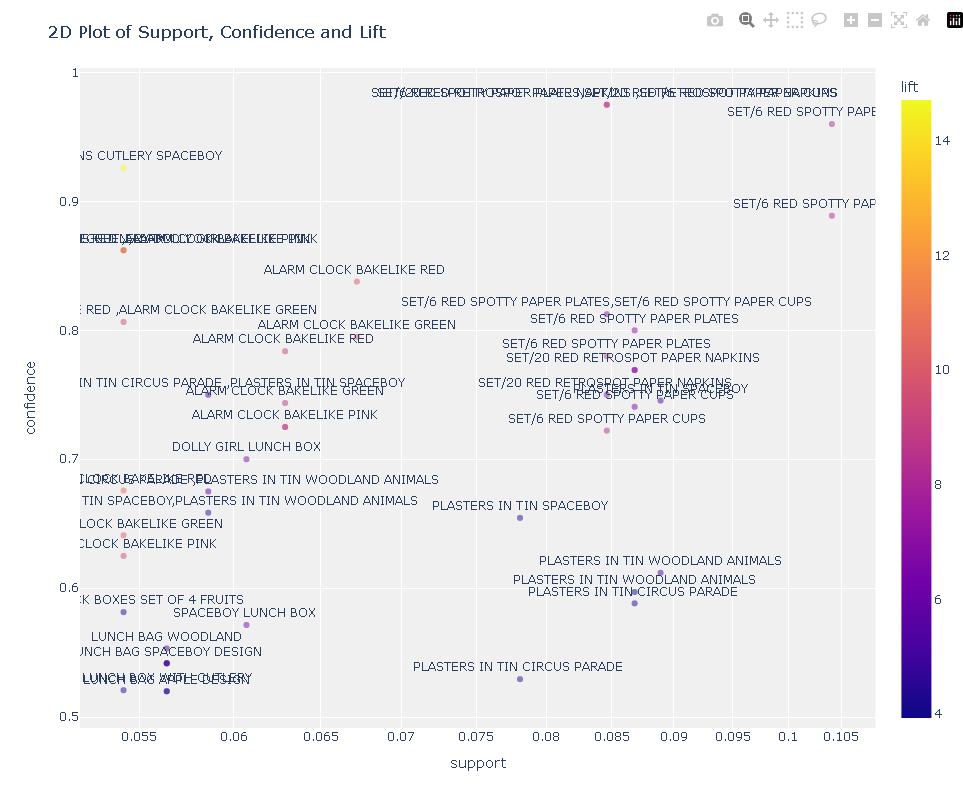
四、绘制模型
plot_model(model2)
plot_model(model2, plot = '3d')