


pycaret学习之异常检测
异常检测是识别与大多数数据明显不同的稀有物品、事件或观察结果的任务。通常,异常项目会转化为某种问题,例如银行欺诈、结构缺陷、医疗问题或文本中的错误。存在三大类异常检测技术:
- 无监督异常检测:无监督异常检测技术通过查找似乎最不适合数据集其余部分的实例来检测未标记测试数据集中的异常,前提是数据集中的大多数实例都是正常的。
- 监督异常检测:此技术需要一个标记为“正常”和“异常”的数据集,并涉及训练分类器。
- 半监督异常检测:该技术从给定的正常训练数据集构建一个表示正常行为的模型,然后测试学习模型生成测试实例的可能性。、
PyCaret 的异常检测模块是一个无监督的机器学习模块,它执行识别稀有物品、事件或观察的任务,这些物品、事件或观察结果与大多数数据有很大不同,会引起怀疑。
一、获取数据
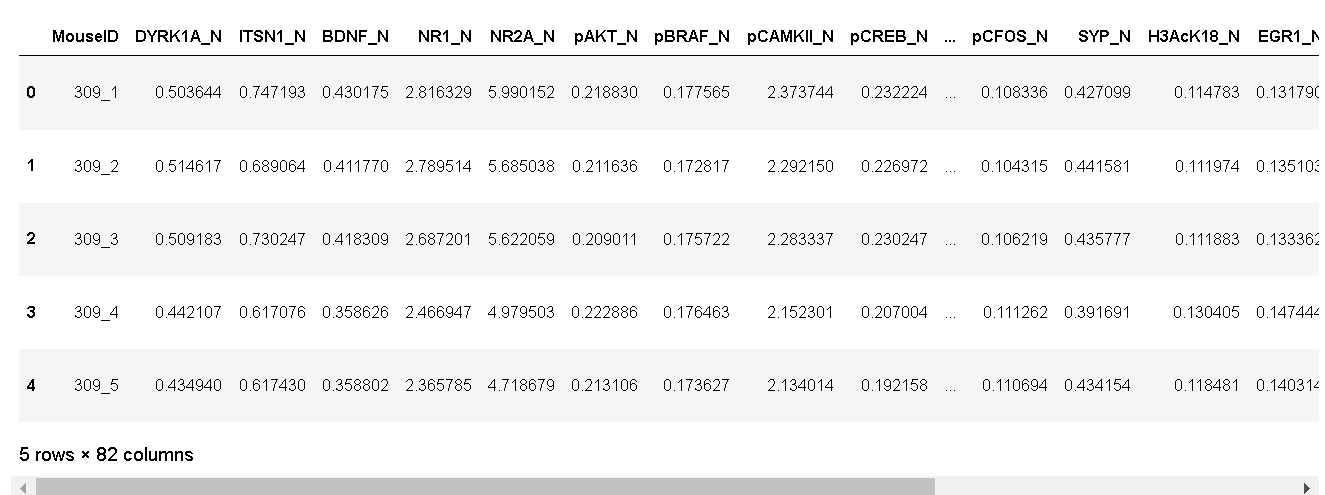
from pandas import read_csv data = read_csv('C:\\Users\86152\pycaret\datasets\mice.csv') data.head()
二、设置(set up())
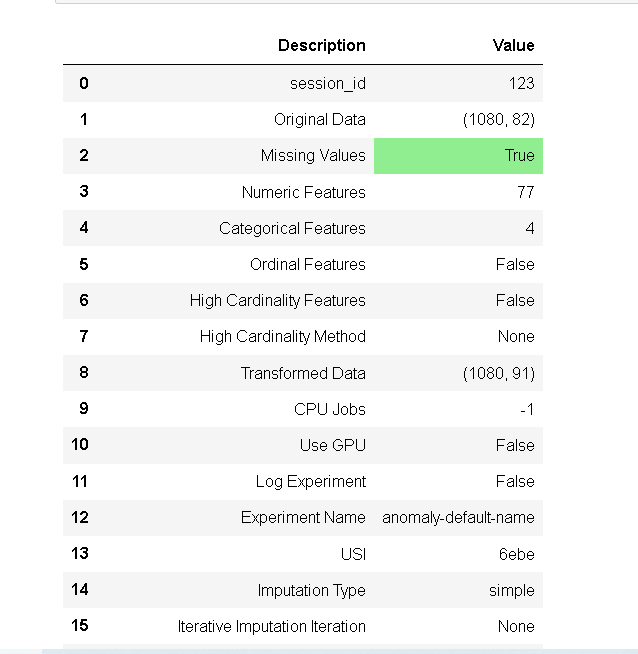
from pycaret.anomaly import * exp_ano101 = setup(data, normalize = True, ignore_features = ['MouseID'], session_id = 123)
三、创建模型
在 PyCaret 中创建异常检测模型非常简单,类似于在 PyCaret 的监督模块中创建模型的方式。异常检测模型是使用函数创建的,该函数将一个必需参数(即模型名称)作为字符串。
iforest = create_model('iforest')
我们使用 创建了iforest模型。请注意,设置的参数是未在 中传递参数时的默认值。 参数确定数据集中异常值的比例。在下面的示例中,我们将创建包含分数的模型。
svm = create_model('svm', fraction = 0.025)
print(svm)

四、分配模型
现在我们已经创建了一个模型,我们希望将异常标签分配给我们的数据集(1080 个样本)以分析结果。我们将通过使用函数来实现这一点。
iforest_results = assign_model(iforest)
iforest_results.head()
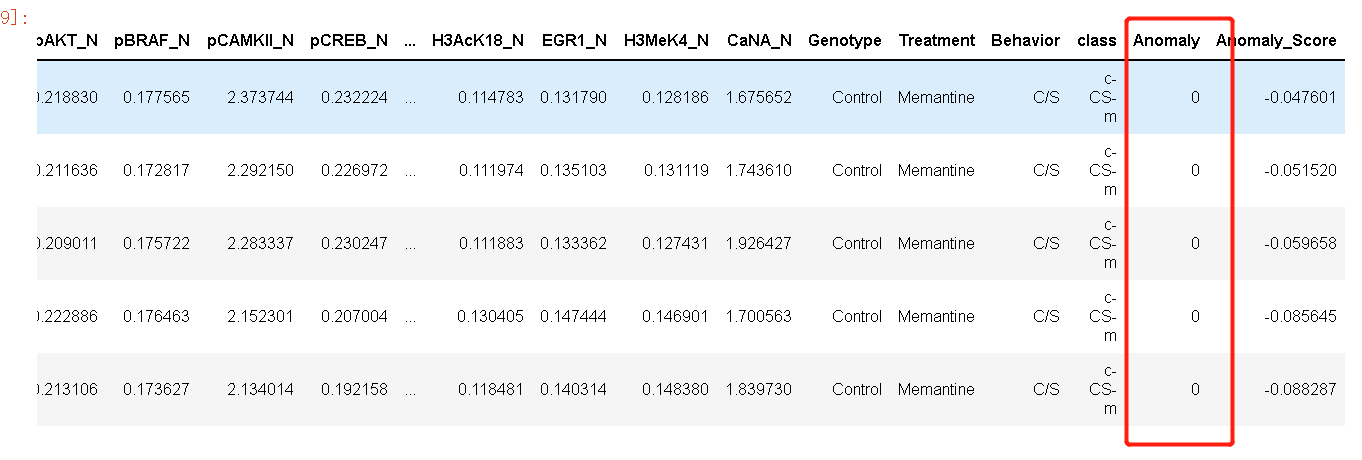
在末尾添加了两列和。0 代表内值,1 代表异常值/异常值。分数是算法计算的值。为异常值分配了较大的异常分数。请注意,这还包括我们在 期间删除的功能。它未用于模型,仅在使用 时追加到数据集。
五、绘制模型
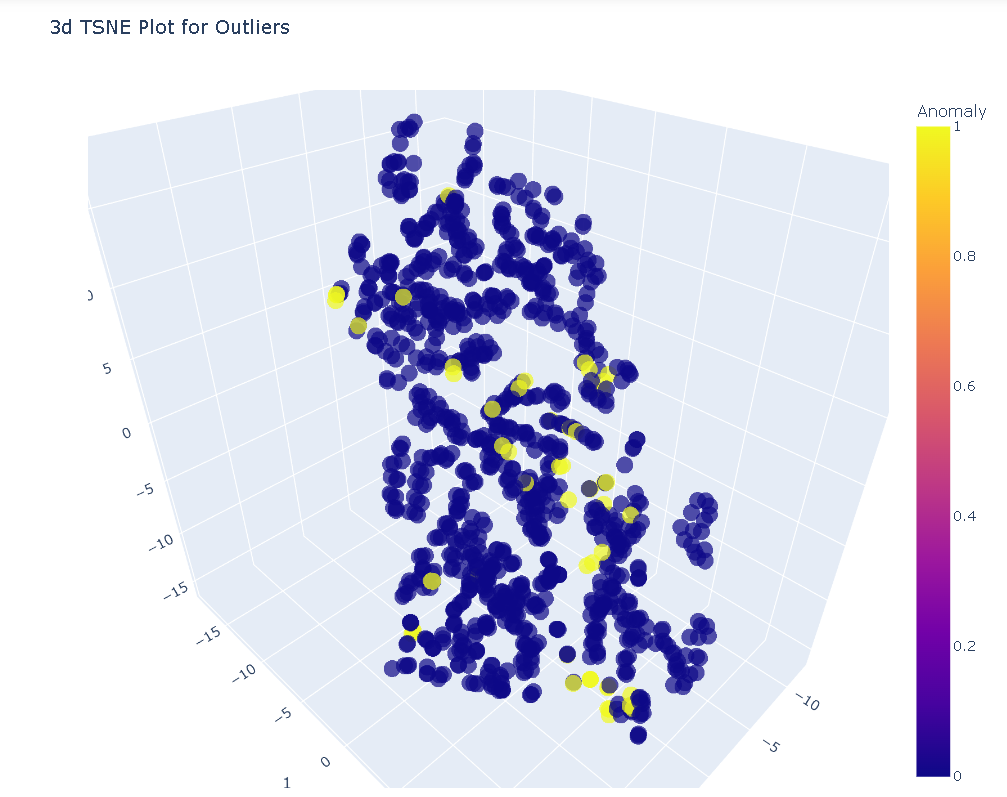
1、T分布随机邻域嵌入(t-SNE)
plot_model(iforest)
2、均匀流形近似与投影
plot_model(iforest, plot = 'umap')
后面保存模型(save_model())以及加载保存模型(load_model())与之前步骤一致。

