


pycaret学习之无监督学习-聚类
聚类分析是将一组对象分组的任务,使同一组(称为聚类)中的对象彼此之间比其他组中的对象更相似。它是一种探索性数据挖掘活动,也是用于许多领域的统计数据分析的常用技术,包括机器学习、模式识别、图像分析、信息检索、生物信息学、数据压缩和计算机图形学。集群的一些常见现实用例是:
- 根据购买历史或兴趣进行客户细分,以设计有针对性的营销组合。
- 根据标签、主题和文档内容将文档聚类为多个类别。
- 分析社会/生命科学实验的结果,以找到数据中的自然分组和模式。
PyCaret 的聚类模块是一个无监督的机器学习模块,它执行对一组对象进行分组的任务,使得同一组(称为集群)中的对象彼此之间比其他组中的对象更相似。
一、获取数据
from pandas import read_csv dataset = read_csv('C:\\Users\86152\pycaret\datasets\mice.csv') dataset.head()
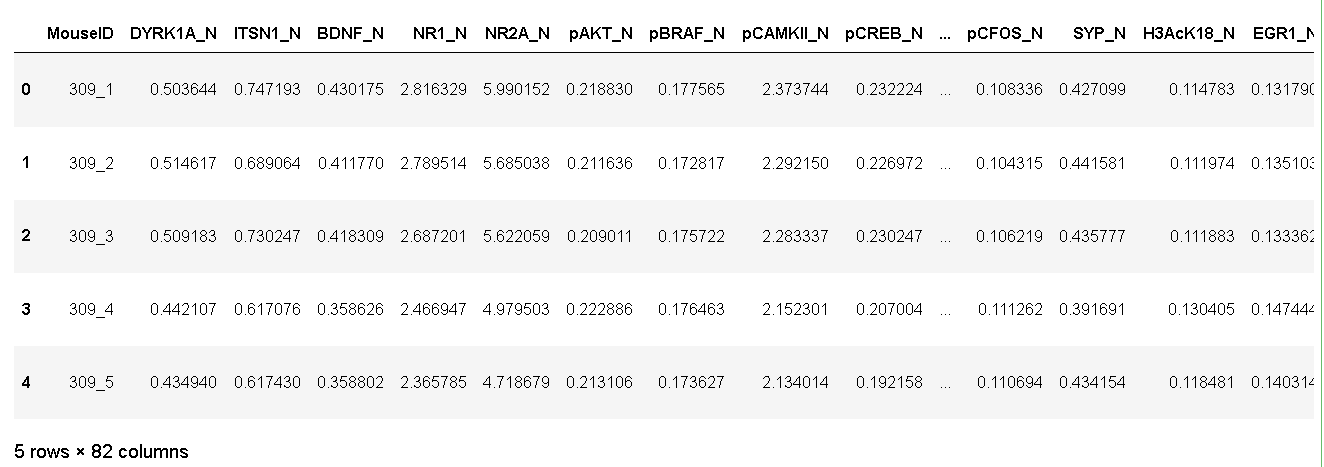
为了在看不见的数据上演示该功能,从原始数据集中保留了 5%(54 条记录)的样本,以便在实验结束时用于预测。这不应与训练/测试拆分混淆,因为执行此特定拆分是为了模拟现实生活中的场景。另一种思考方式是,在进行此实验时,这54个样本不可用。
data = dataset.sample(frac=0.95, random_state=786) data_unseen = dataset.drop(data.index) data.reset_index(drop=True, inplace=True) data_unseen.reset_index(drop=True, inplace=True) print('Data for Modeling: ' + str(data.shape)) print('Unseen Data For Predictions: ' + str(data_unseen.shape))

二、设置(set up())
from pycaret.clustering import * #对数据进行标准化,忽略特征'MouseID'
exp_clu101 = setup(data, normalize = True, ignore_features = ['MouseID'], session_id = 123)

三、创建模型(create_model())
kmeans = create_model('kmeans')
print(kmeans)

KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=4, n_init=10, n_jobs=-1, precompute_distances='deprecated',
random_state=123, tol=0.0001, verbose=0)
我们使用 创建了一个 kmeans 模型。请注意,当您不向参数传递值时,参数设置为默认值。在下面的示例中,我们将创建一个包含 6 个聚类的模型。
kmodes = create_model('kmodes', num_clusters = 6)
print(kmodes)

KModes(cat_dissim=<function matching_dissim at 0x000001857A38AEA0>, init='Cao',
max_iter=100, n_clusters=6, n_init=1, n_jobs=-1, random_state=123,
verbose=0)
另外我们可以使用models()查看聚类模型
model()
| ID | Name | Reference |
|---|---|---|
| kmeans | K-Means Clustering(K-平均法) | sklearn.cluster._kmeans.KMeans |
| ap | Affinity Propagation(近邻传播聚类) | sklearn.cluster._affinity_propagation.Affinity... |
| meanshift | Mean Shift Clustering(均值漂移聚类) | sklearn.cluster._mean_shift.MeanShift |
| sc | Spectral Clustering(谱聚类) | sklearn.cluster._spectral.SpectralClustering |
| hclust | Agglomerative Clustering(层次聚类) | sklearn.cluster._agglomerative.AgglomerativeCl... |
| dbscan | Density-Based Spatial Clustering | sklearn.cluster._dbscan.DBSCAN |
| optics | OPTICS Clustering | sklearn.cluster._optics.OPTICS |
| birch | Birch Clustering(综合层次聚类) | sklearn.cluster._birch.Birch |
| kmodes | K-Modes Clustering | kmodes.kmodes.KModes |
四、分配模型
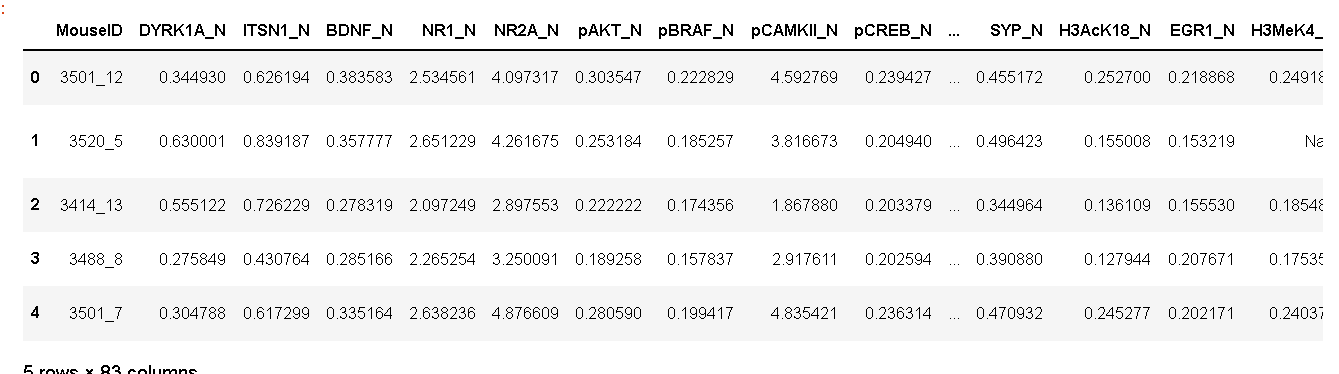
现在我们已经创建了一个模型,我们希望将聚类标签分配给我们的数据集(1080 个样本)来分析结果。我们将通过使用该功能来实现这一点。
kmean_results = assign_model(kmeans)
kmean_results.head()
![]()
五、绘制模型
该函数可用于分析聚类分析模型的不同方面。此函数采用经过训练的模型对象并返回一个绘图。
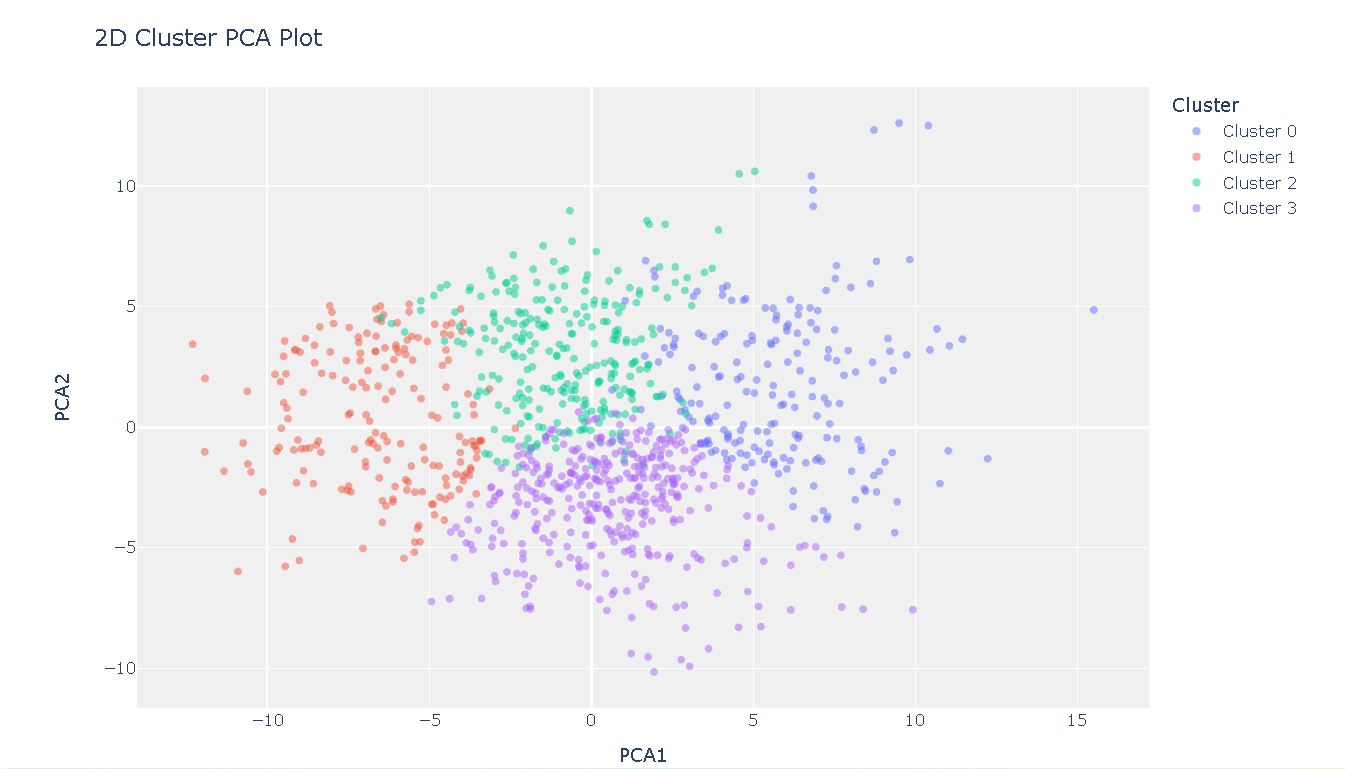
1、聚类PCA图
plot_model(kmeans)
2、肘部图
plot_model(kmeans, plot = 'elbow')
肘部法是一种启发式方法,用于解释和验证聚类分析中的一致性,旨在帮助在数据集中找到适当数量的聚类。在此示例中,上面的弯头图表明这是最佳聚类数:5
3、剪影图
plot_model(kmeans, plot = 'silhouette')
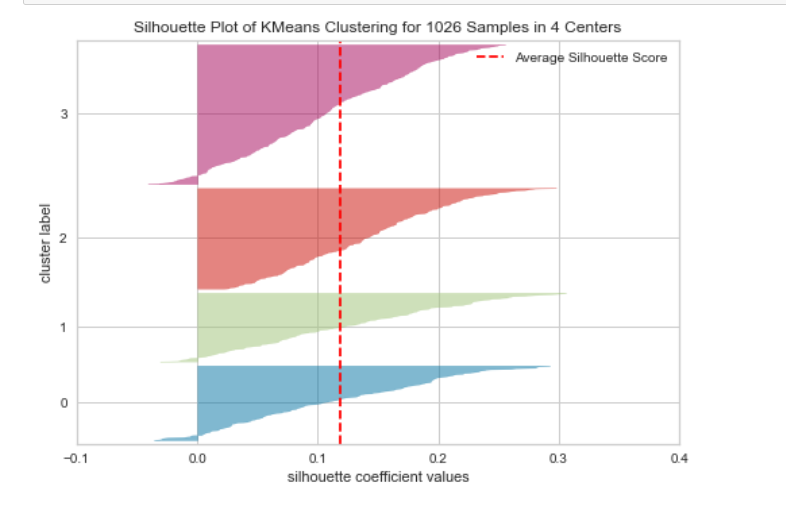
剪影是一种解释和验证数据簇内一致性的方法。该技术提供了每个对象的分类情况的简洁图形表示。换句话说,剪影值是衡量对象与其自身聚类(内聚)与其他聚类(分离)的相似程度的度量。
4、分布图
plot_model(kmeans, plot = 'distribution') #to see size of clusters
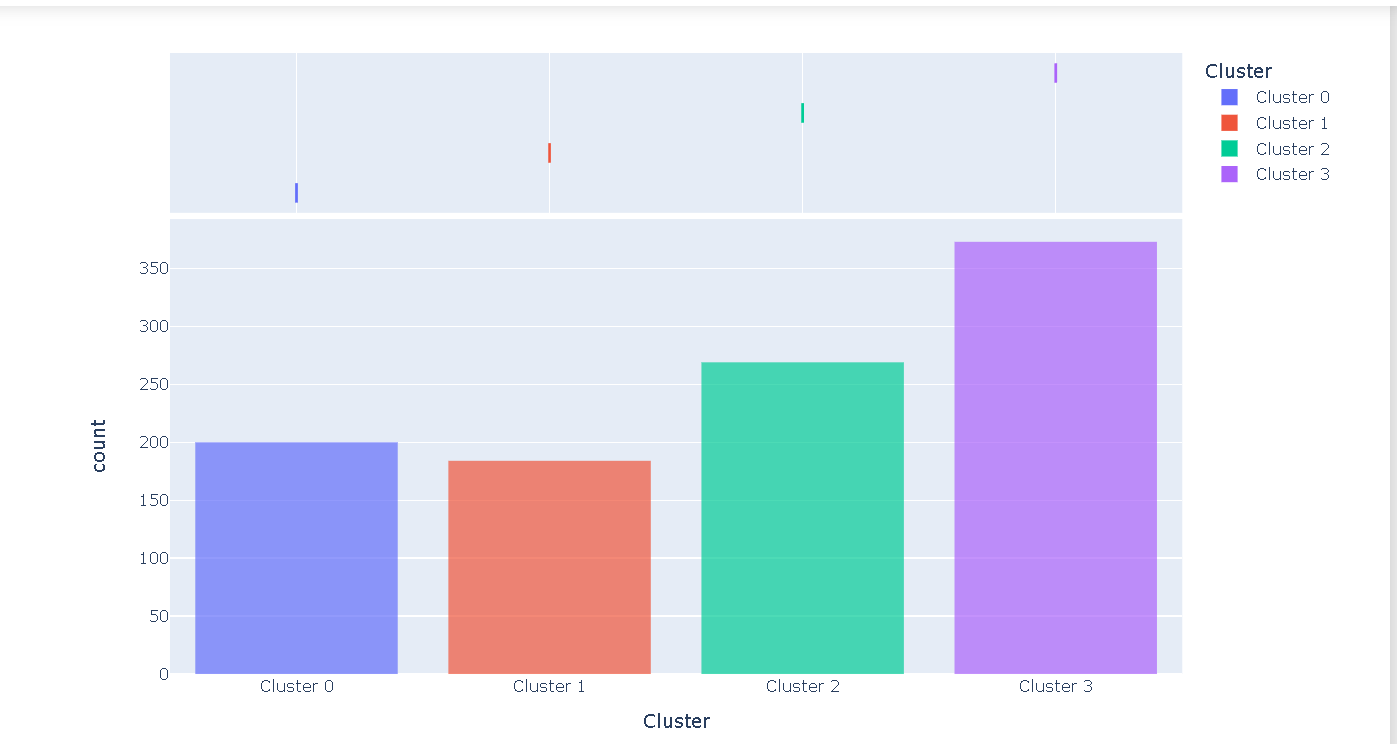
分布图显示了每个聚类的大小。将鼠标悬停在条形上时,您将看到分配给每个聚类的样本数。从上面的例子中,我们可以观察到聚类 3 的样本数最多。我们还可以使用该图来查看与任何其他数字或分类特征相关的聚类标签的分布。
plot_model(kmeans, plot = 'distribution', feature = 'class')
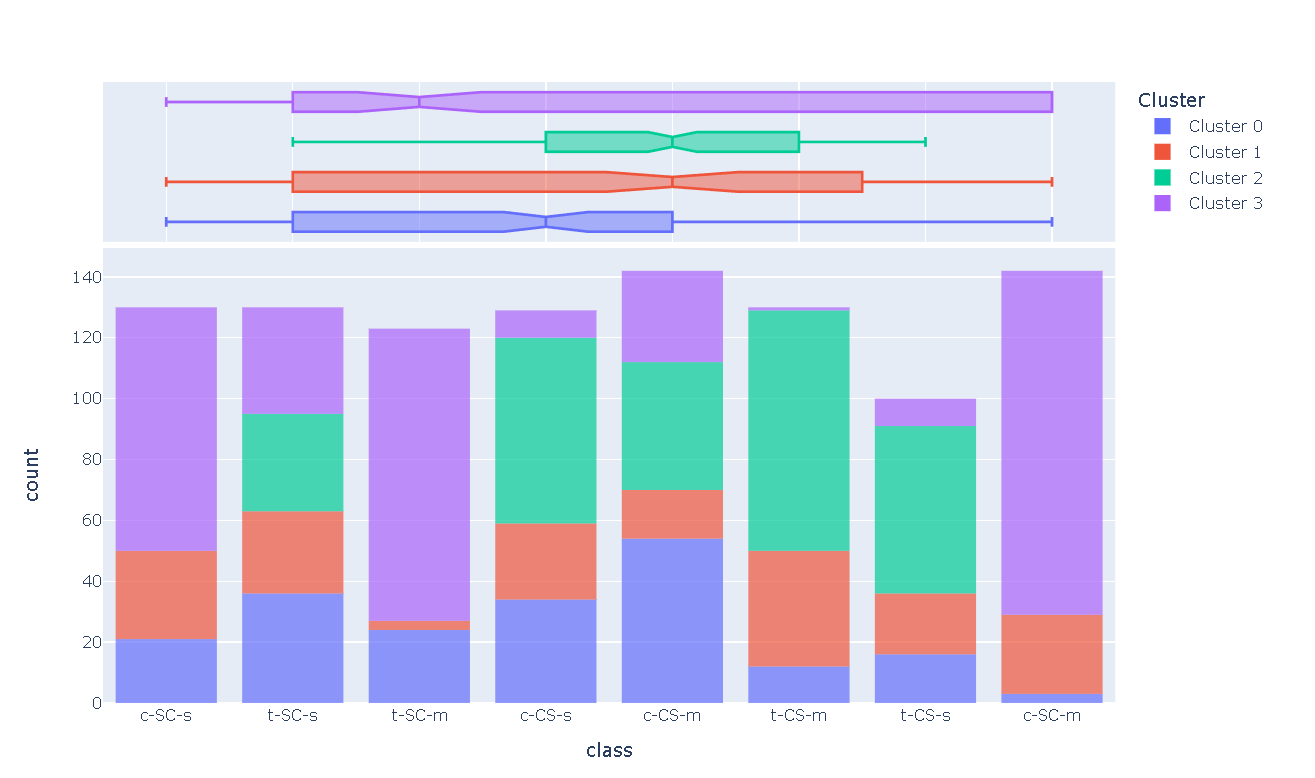
在上面的示例中,我们用作一个特征,因此每个条形代表一个用聚类标签着色的条形(右侧图例)。我们可以观察到该类,并且主要由.我们还可以使用相同的图来查看任何连续特征的分布。
plot_model(kmeans, plot = 'distribution', feature = 'CaNA_N')
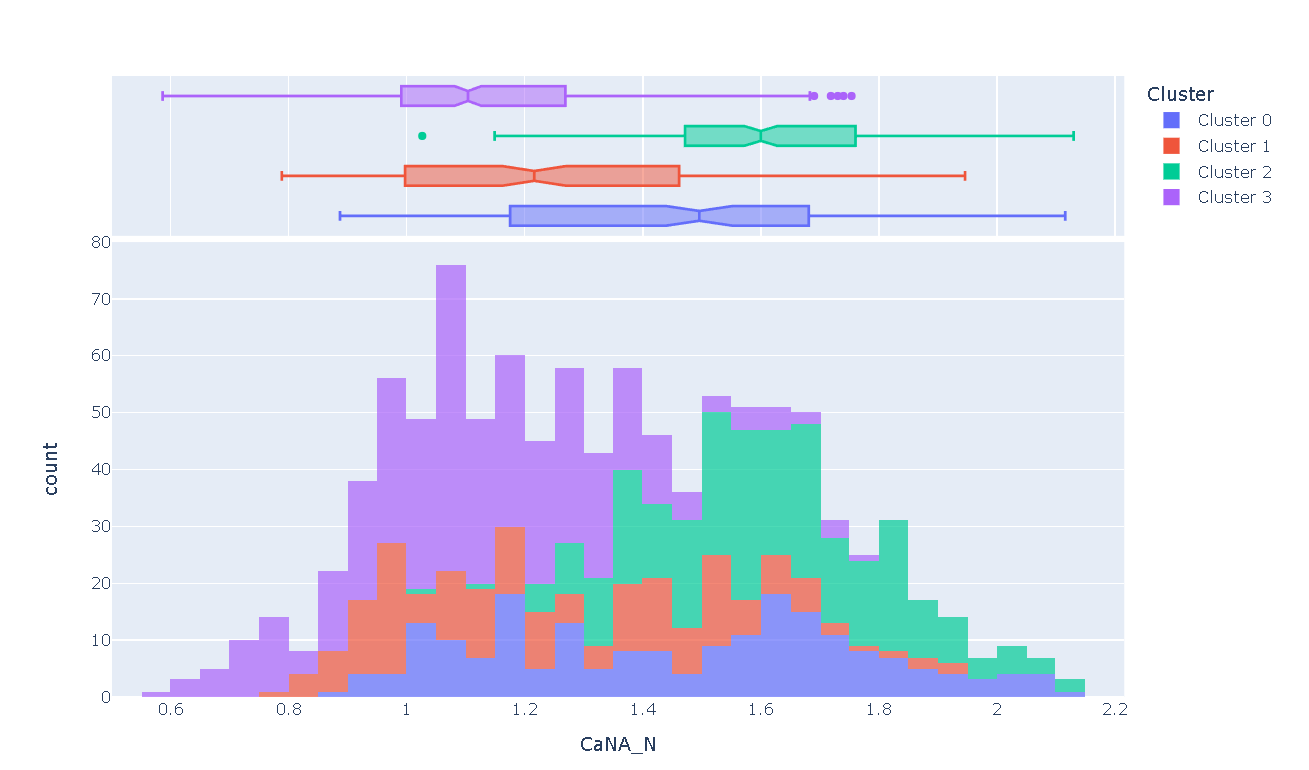
接下来的保存模型(save_model())和加载保存模型(load_model())跟之前的一致步骤。

