
pycaret学习之受监督学习的机器学习-回归
回归
回归分析是一组统计过程,用于估计因变量(通常称为“结果变量”或“目标”)与一个或多个自变量(通常称为“特征”、“预测变量”或“协变量”)之间的关系。机器学习回归的目标是预测连续值,如销售金额、数量、温度等。
PyCaret 的回归模块是一个监督机器学习模块,用于使用各种技术和算法预测连续值/结果。回归可用于预测价值/结果,例如销售额、销售单位、温度或任何连续的数字。
一、获取数据
from pandas import read_csv dataset = read_csv('C:\\Users\86152\pycaret\datasets\diamond.csv') dataset.head()
#check the shape of data dataset.shape
为了在未见过的数据上演示该功能,已从原始数据集中保留了 600 条记录的样本,用于预测。这不应与训练/测试拆分混淆,因为执行此特定拆分是为了模拟现实生活中的场景。另一种思考方式是,这 600 条记录在执行机器学习实验时不可用。
data = dataset.sample(frac=0.9, random_state=786) data_unseen = dataset.drop(data.index) data.reset_index(drop=True, inplace=True) data_unseen.reset_index(drop=True, inplace=True) print('Data for Modeling: ' + str(data.shape)) print('Unseen Data For Predictions: ' + str(data_unseen.shape))

二、设置(set up())
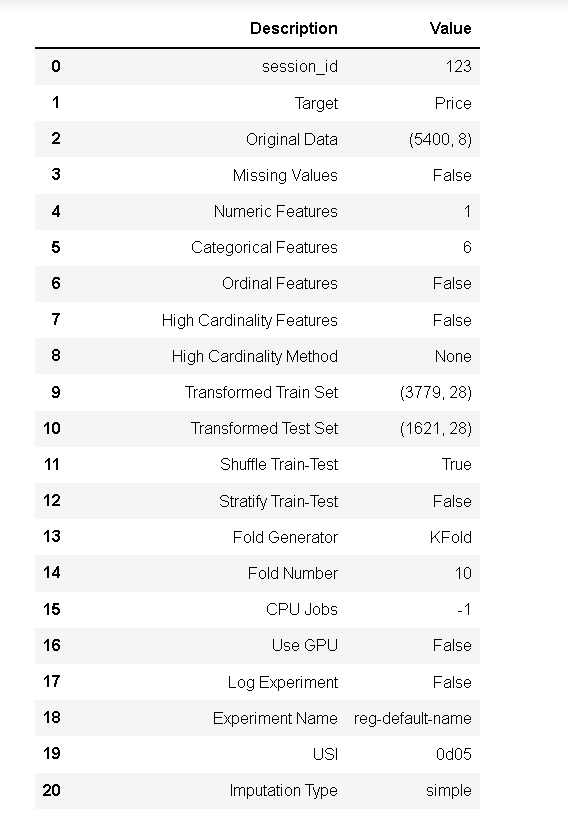
from pycaret.regression import * exp_reg101 = setup(data = data, target = 'Price', session_id=123)
三、比较所有模型(compare_models())
比较所有模型以评估性能是设置完成后建模的建议起点(除非确切知道需要哪种模型,但通常情况并非如此)。此函数训练模型库中的所有模型,并使用 k 折叠交叉验证对其进行评分以进行指标评估。输出打印一个分数网格,显示跨折叠的平均MAE(平均绝对误差),MSE(均方误差),RMSE(均方根误差),,MAPE(平均绝对百分误差),R2以及RMSLE(默认为 10)以及训练时间。
best = compare_models(exclude = ['ransac'])
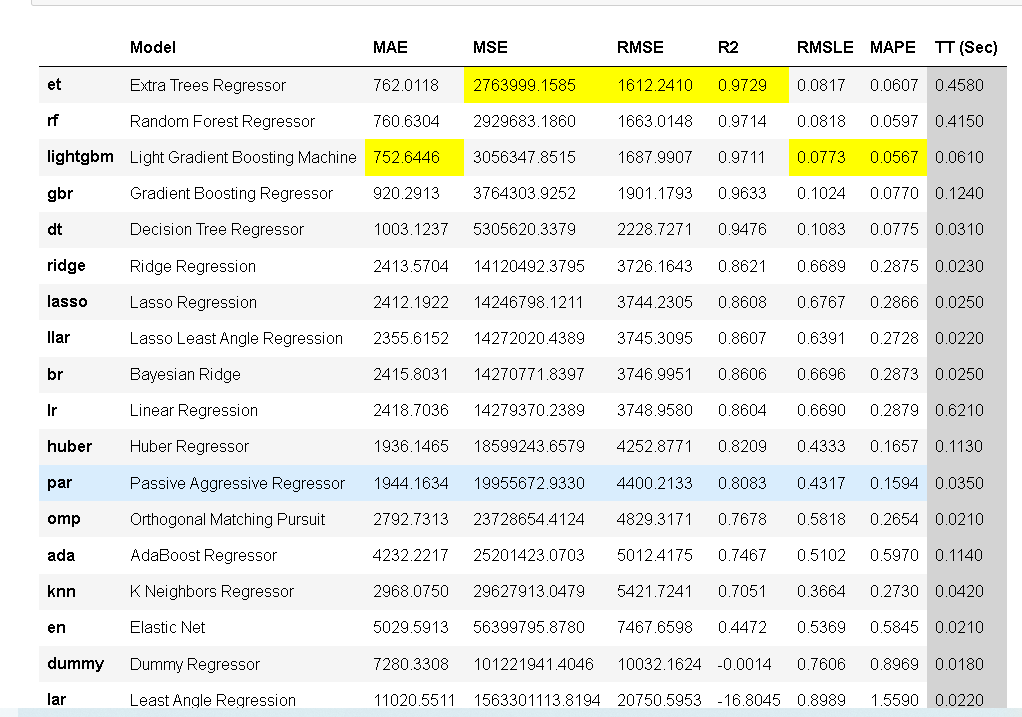
面打印的分数网格突出显示了性能最高的指标,仅用于比较目的。默认情况下,网格使用(从高到低)进行排序,可以通过传递参数来更改。例如,将按 RMSLE 对网格进行排序(从低到高,因为越低越好[compare_models(sort = 'RMSLE')])。
其中评估回归模型误差指标:
1、MSE(均方误差):是预测误差平方之和的平均数。
2、RMSE(均方根误差):是回归模型的典型指标,用于指示模型在预测中会产生多大的误差,对于较大的误差,权重较高, RMSE越小越好。
3、MAE(平均绝对误差):用来衡量预测值与真实值之间的平均绝对误差,MAE越小表示模型越好。
4、R2:R2越大表示模型越好。
四、创建模型(create_model())
create_model()是 PyCaret 中最精细的函数,通常是大多数 PyCaret 功能背后的基础。顾名思义,此函数使用可以使用折叠参数设置的交叉验证来训练和评估模型。输出打印一个分数网格,按折叠显示 MAE、MSE、RMSE、R2、RMSLE 和 MAPE。
首先我们可以使用model()查看PyCaret 的模型库中的回归模型
model()
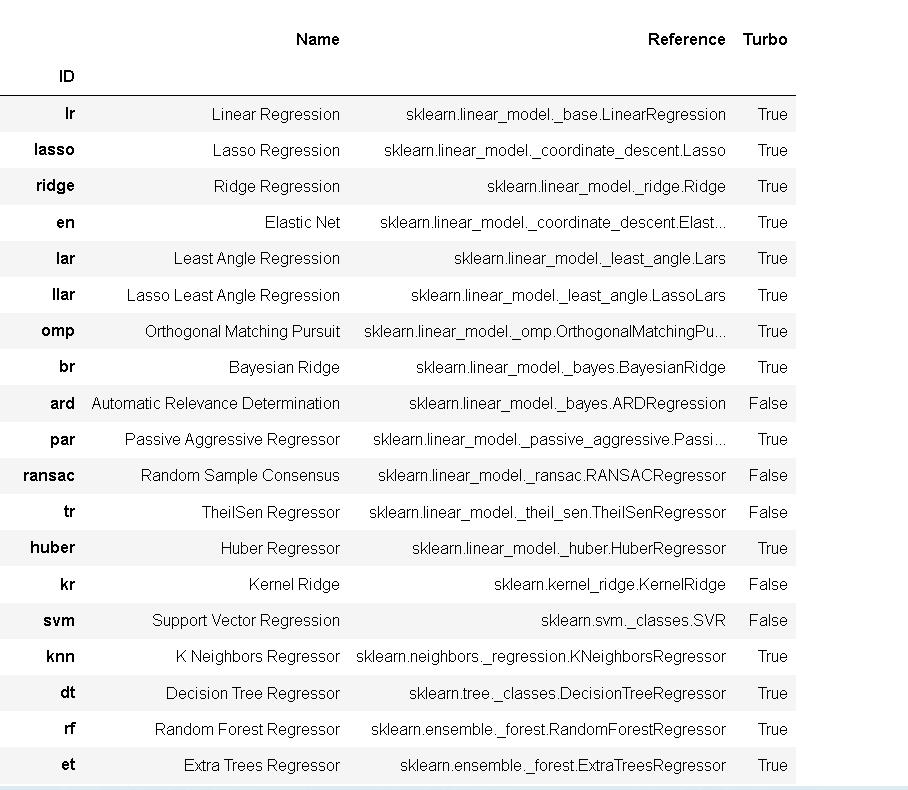
接下来,我们将使用以下模型作为候选模型。
- AdaBoost Regressor ('ada')
- Light Gradient Boosting Machine ('lightgbm')
- Decision Tree ('dt')
ada = create_model('ada'); lightgbm = create_model('lightgbm'); dt = create_model('dt')
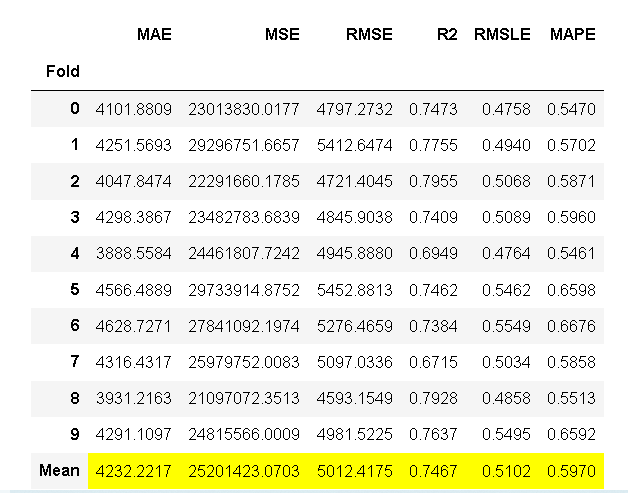
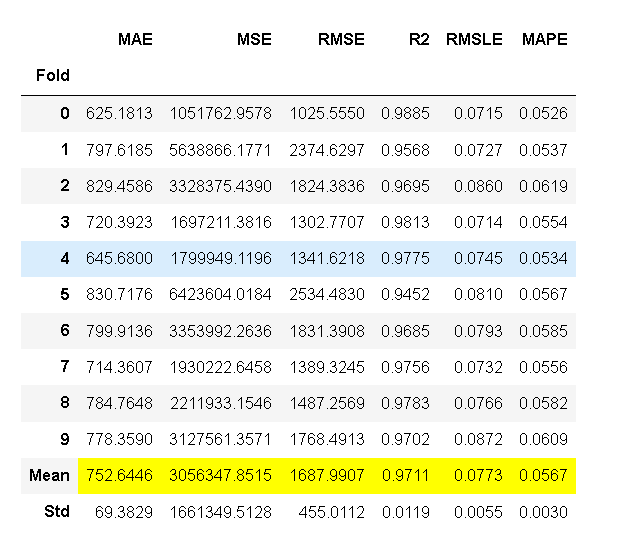
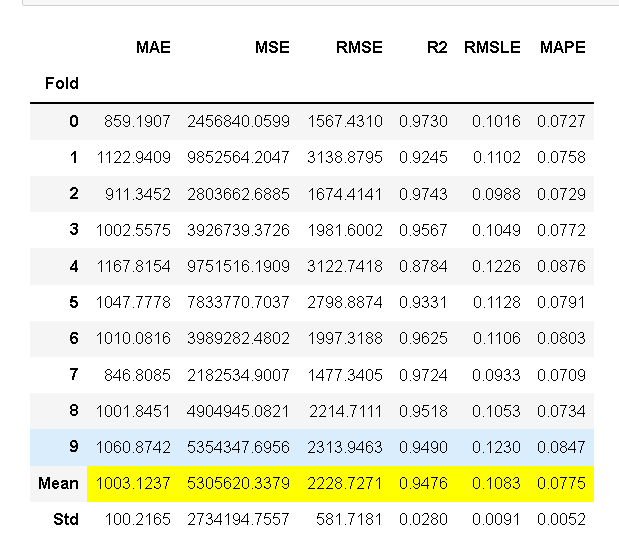
图1 ada 图2 lightgbm 图3 dt
五、调整模型(tune_model())
使用该函数创建模型时,它使用默认超参数来训练模型。为了调整超参数,使用了该函数。此函数在预定义的搜索空间上使用自动调整模型的超参数。
tuned_ada = tune_model(ada); import numpy as np lgbm_params = {'num_leaves': np.arange(10,200,10), 'max_depth': [int(x) for x in np.linspace(10, 110, num = 11)], 'learning_rate': np.arange(0.1,1,0.1) } tuned_lightgbm = tune_model(lightgbm, custom_grid = lgbm_params); tuned_dt = tune_model(dt);
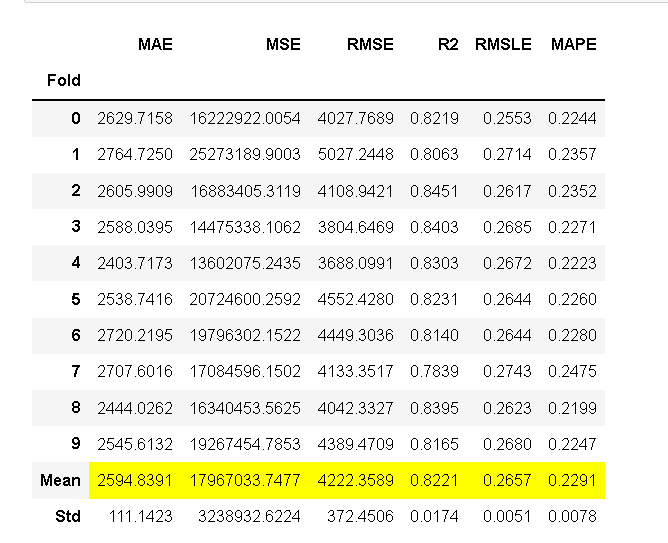
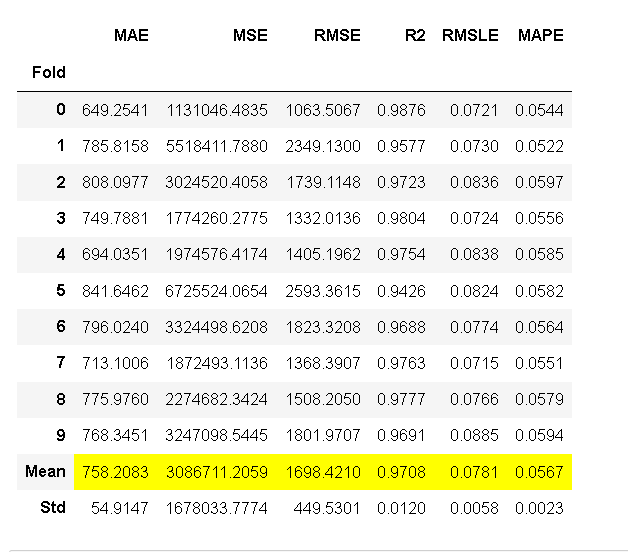
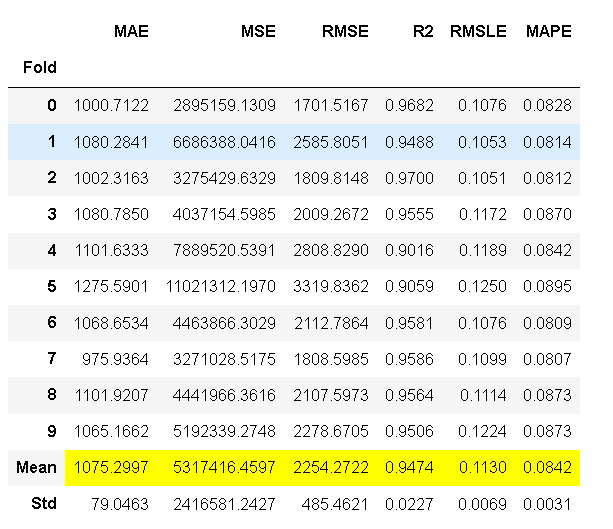
图1 ada 图2 lightgbm 图3 dt
默认情况下优化,可以使用优化参数进行更改。例如:tune_model(dt, optimize = 'MAE') 将搜索决策树回归器的超参数,该参数的结果是最低而不是最高。
六、绘制模型(plot_model())
在模型最终确定之前,该函数可用于分析不同方面的性能,例如残差图、预测误差、特征重要性等。此函数采用经过训练的模型对象,并根据测试/维持集返回图。
1、残差图
plot_model(tuned_lightgbm)
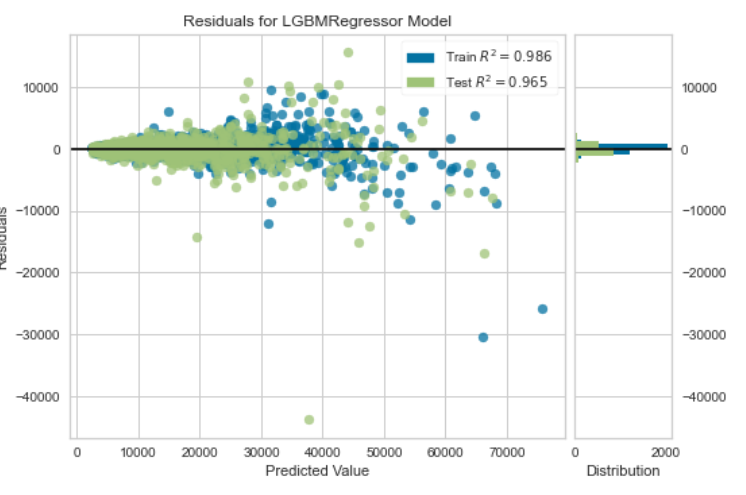
2、预测误差图
plot_model(tuned_lightgbm, plot = 'error')
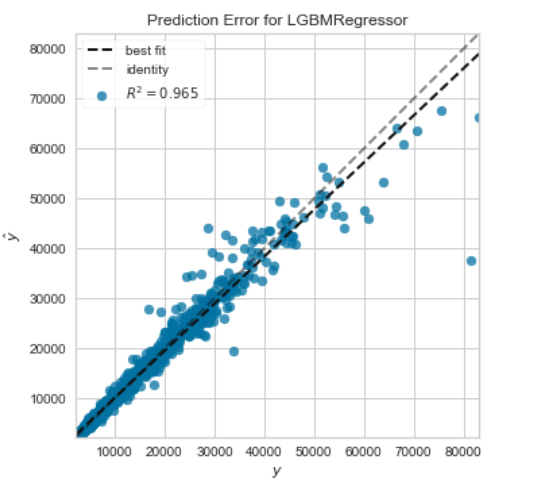
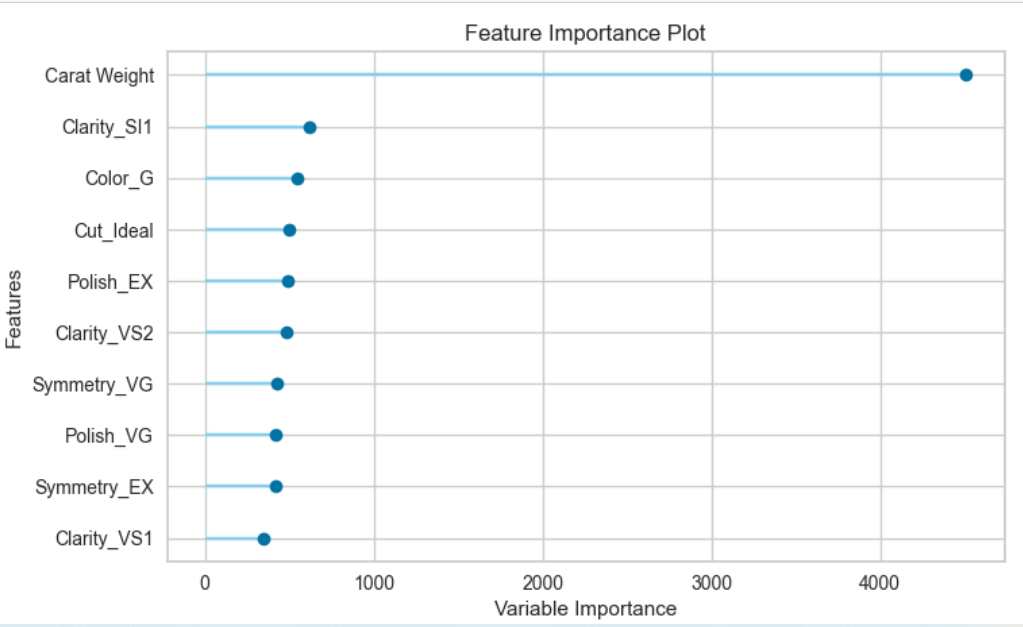
3、特征重要性图
plot_model(tuned_lightgbm, plot='feature')
分析模型性能的另一种方法是使用该函数,该函数显示给定模型的所有可用绘图的用户界面。它在内部使用该函数。evaluate_model()
七、测试预测/保留样本(predict_model())
在最终确定模型之前,建议通过预测测试/维持集并查看评估指标来执行最终检查。如果您查看上面第 6 节中的信息网格,您会发现 30%(1621 个样本)的数据已作为测试/保留样本分离出来。我们在上面看到的所有评估指标都是仅基于训练集(70%)的交叉验证结果。现在,使用存储在变量中的最终训练模型,我们将预测保留样本并评估指标,以查看它们是否与 CV 结果存在实质性差异。
predict_model(tuned_lightgbm);

测试/维持集的 R2 为 0.9652,而 CV 结果为 0.9708(见上文第 9.2 节)。这不是一个显着的区别。如果测试/维持和CV结果之间存在很大差异,则这通常表明过度拟合,但也可能是由于其他几个因素造成的,需要进一步调查。在这种情况下,我们将继续完成模型并预测看不见的数据。
八、完成部署模型(finalize_model())
模型最终确定是实验的最后一步。PyCaret 中的正常机器学习工作流从 开始,然后比较所有模型,并使用一些候选模型(基于感兴趣的指标)入围,以执行多种建模技术,例如超参数调优、集成、堆叠等。此工作流最终将引导您找到用于对新的和未见过的数据进行预测的最佳模型。该函数将模型拟合到完整的数据集上,包括测试/维持样本(在本例中为 30%)。此函数的目的是在将模型部署到生产环境之前,在完整的数据集上训练模型。
final_lightgbm = finalize_model(tuned_lightgbm);
print(final_lightgbm)

九、对看不见的数据进行预测
unseen_predictions = predict_model(final_lightgbm, data=data_unseen)
unseen_predictions.head()
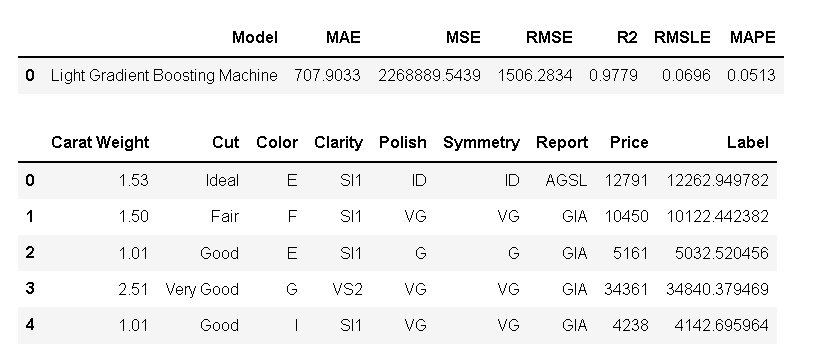
十、保存模型(save_model())
现在,我们已经完成了实验,最终确定了现在存储在变量中的模型。
save_model(final_lightgbm,'Final LightGBM Model 18Dec2022')

十一、加载保存的模型(load_model())
为了在未来某个日期在相同或替代环境中加载保存的模型,我们将使用 PyCaret 的函数,然后轻松地将保存的模型应用于新的看不见的数据以进行预测。
saved_final_lightgbm = load_model('Final LightGBM Model 18Dec2022')

