
pycaret学习之受监督的机器学习-分类
PyCaret 的分类模块是一个监督式机器学习模块,用于将元素分类为组。目标是预测离散和无序的分类类标签。一些常见的用例包括预测客户违约(是或否)、预测客户流失(客户将离开或留下)、发现的疾病(阳性或阴性)。此模块可用于二进制或多类问题。它提供了几个预处理准备数据以进行建模的功能set up功能。它拥有超过 18 种即用型算法和几个情节分析已训练模型的性能。
一、set up
此函数初始化训练环境并创建转换管道。在执行任何其他函数之前,必须调用 Setup 函数。它需要两个必需参数:数据(data)和目标(target)。所有其他参数都是可选的。
from pandas import read_csv
data = read_csv('C:\\Users\86152\pycaret\datasets\diabetes.csv')
data.head()
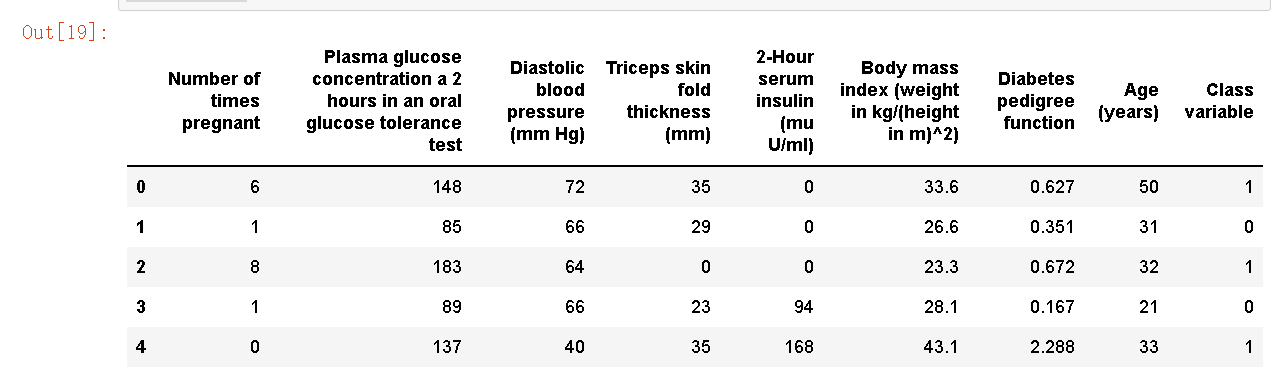
执行set up时 ,PyCaret 的推理算法将根据某些属性自动推断所有特征的数据类型。应正确推断数据类型,但情况并非总是如此。为了处理此问题,PyCaret 会在您执行设置后显示一个提示,要求确认数据类型。如果所有数据类型都正确,您可以按 Enter 键,也可以按 quit 键退出 安装程序。
numeric_features和categorical_features参数from pycaret.classification import *
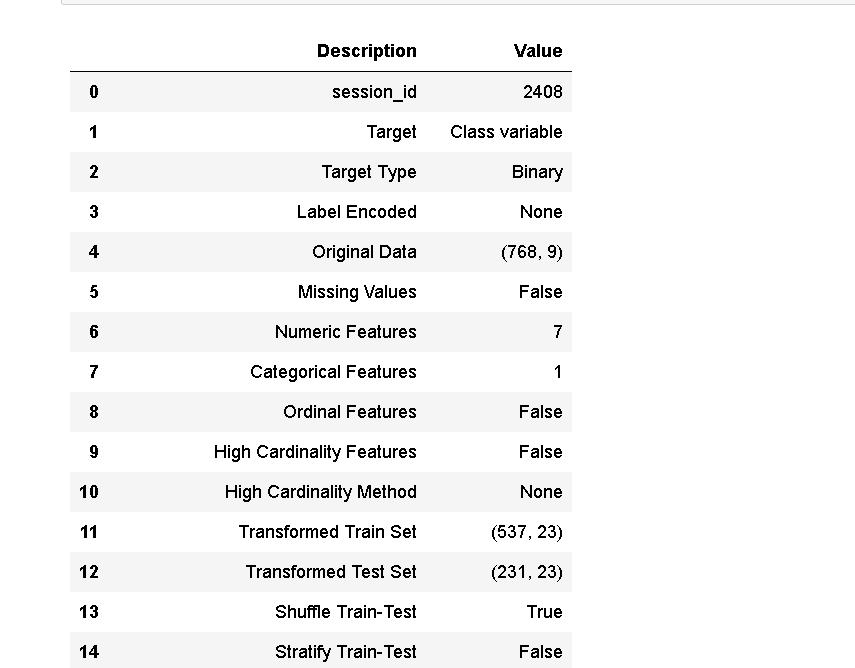
s = setup(data, target = 'Class variable')
二、比较所有模型
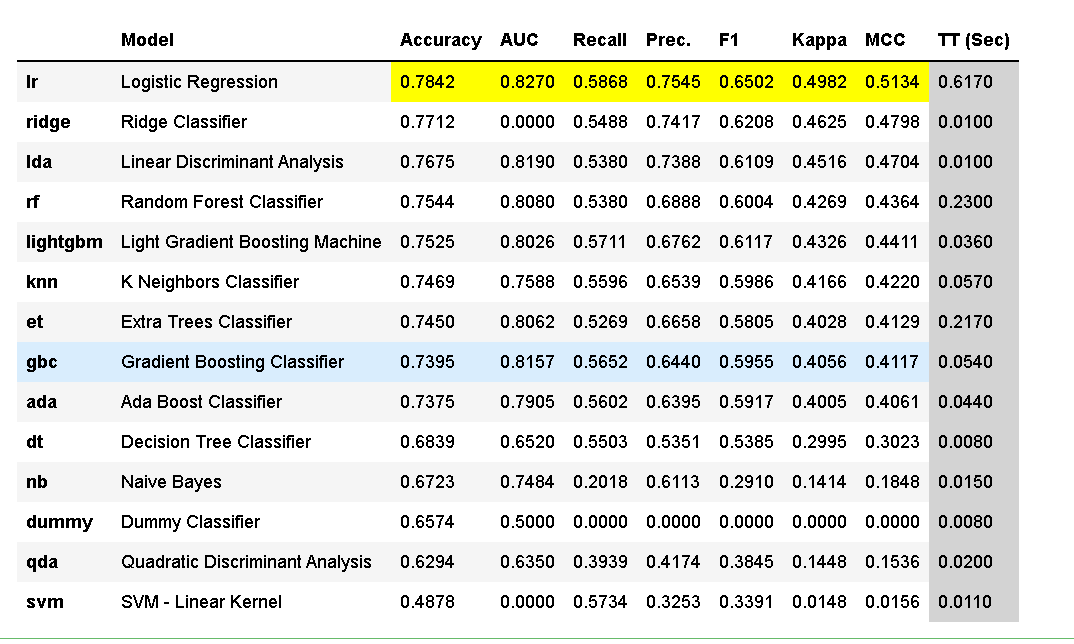
add_metric和remove_metric函数添加或删除自定义指标。best = compare_models()
以上可用的估算器 在模型库(ID - 名称)中:
-
'lr' - 逻辑回归
-
'knn' - K 邻居分类器
-
'nb' - 朴素贝叶斯
-
'dt' - 决策树分类器
-
'svm' - SVM - 线性内核
-
'rbfsvm' - SVM - 径向内核
-
'gpc' - 高斯过程分类器
-
'MLP' - MLP 分类器
-
“ridge” - Ridge 分类器
-
'rf' - 随机森林分类器
-
'qda' - 二次判别分析
-
'ada' - Ada Boost 分类器
-
'gbc' - 梯度提升分类器
-
'lda' - 线性判别分析
-
'et' - 额外树木分类器
-
“xgboost” - 极端梯度提升
-
'lightgbm' - 光梯度增强机
-
'CatBoost' - CatBoost 分类器
以上评估了6种最常用的分类指标(准确性、AUC,召回率,精度、F1,Kappa)。上面打印的分数网格突出显示了性能最高的指标,仅用于比较目的。默认情况下,网格使用“精度”(从高到低)排序。
同时打印出最佳模型为:

三、分析模型
此函数分析测试集上经过训练的模型的性能。在某些情况下,可能需要重新训练模型。
evaluate_model(best)
plot_model(best, plot = 'auc')
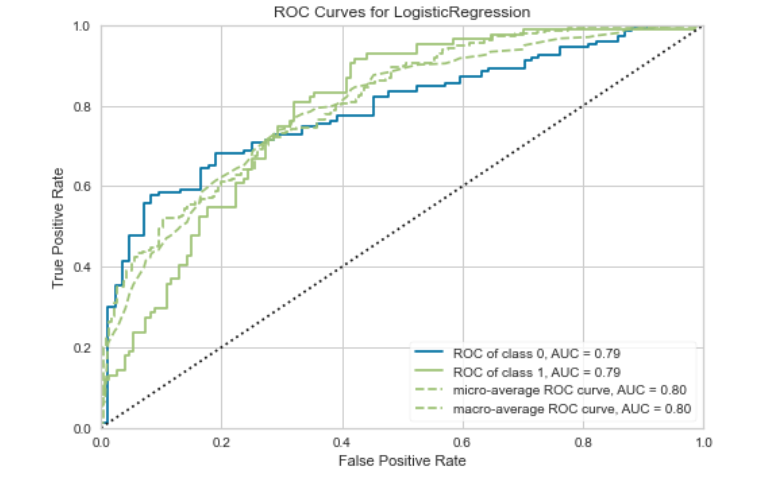
plot_model(best, plot = 'confusion_matrix')
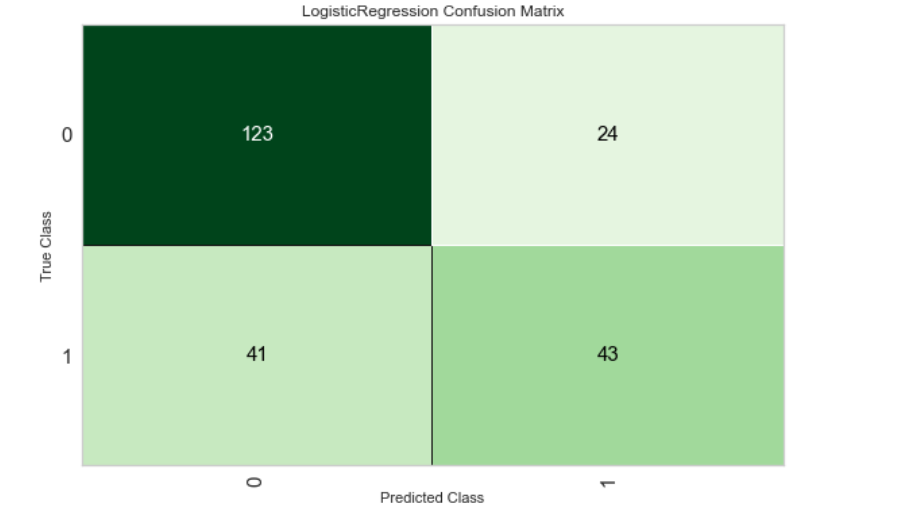
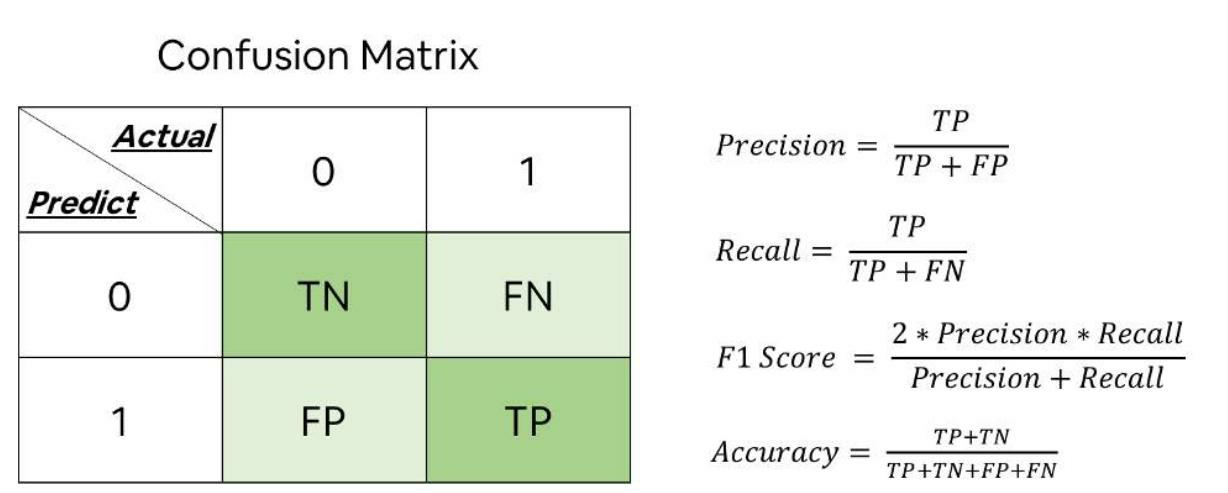
ps:
四、预测
此函数使用经过训练的模型预测“标签”和“分数(预测类的概率)”列。当数据为 None 时,它预测测试集(在设置函数期间创建)上的标签和分数 。
predict_model(best)
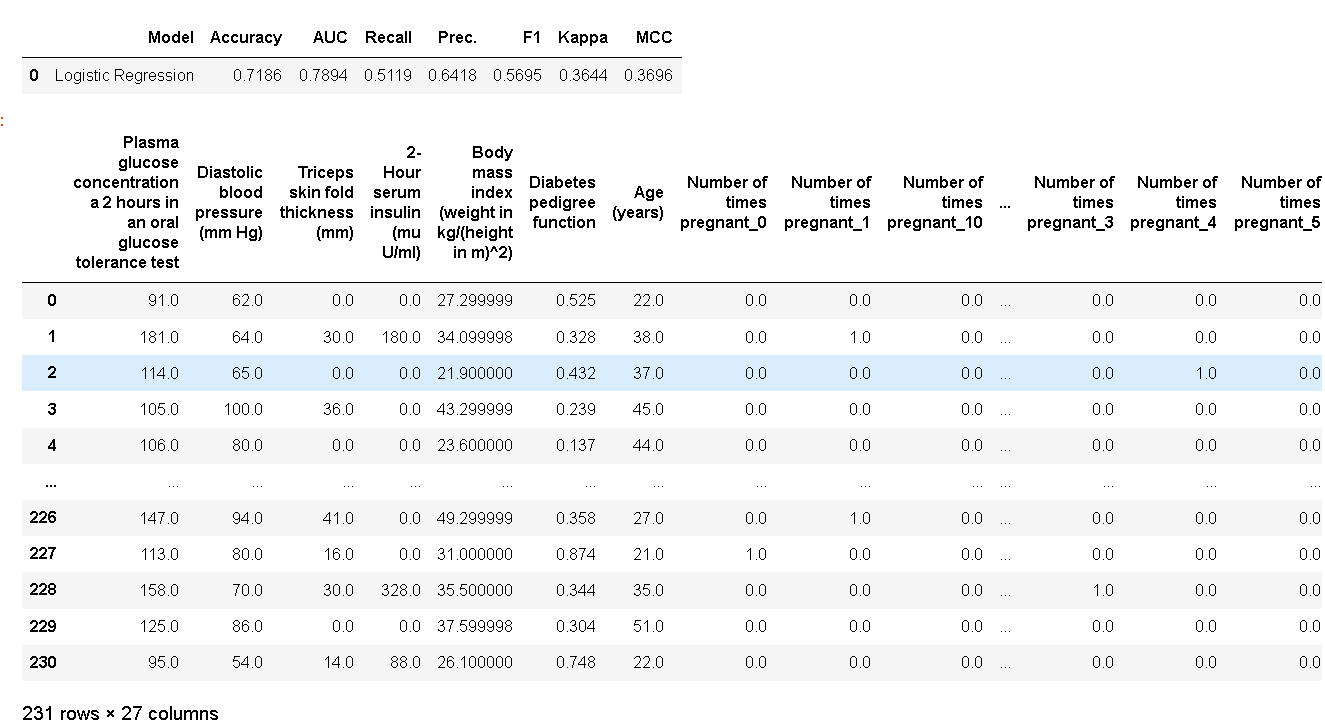
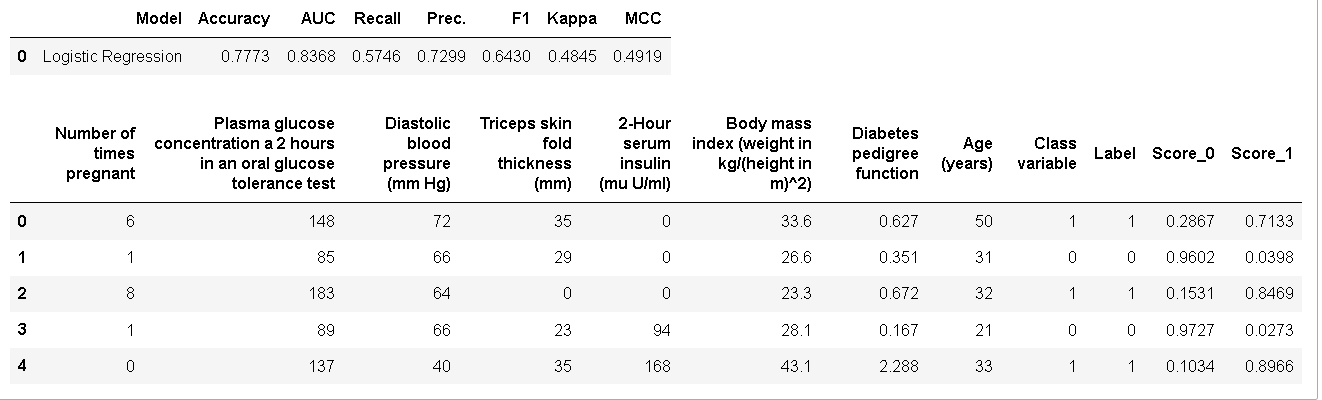
评估指标在测试集上计算。第二个输出是pd.DataFrame测试集预测的数据帧(请参阅最后两列)。要在未见过的(新)数据集上生成标签,
只需在predict_model函数中传递数据集。
predictions = predict_model(best, data=data)
predictions.head()

分数表示预测类(不是正类)的概率。如果标签为 0,分数为 0.90,则表示类为 0 的概率为 90%。如果你想查看这两个类的概率,
只需 在predict_model函数中传递 raw_score=True。
predictions = predict_model(best, data=data, raw_score=True)
predictions.head()
五、保存模型
save_model(best, 'my_best_pipeline')
loaded_model = load_model('my_best_pipeline') print(loaded_model)


