财政收入预测
一、灰度预测函数
def GM11(x0): #自定义灰色预测函数 import numpy as np x1 = x0.cumsum() #1-AGO序列 z1 = (x1[:len(x1)-1] + x1[1:])/2.0 #紧邻均值(MEAN)生成序列 z1 = z1.reshape((len(z1),1)) B = np.append(-z1, np.ones_like(z1), axis = 1) Yn = x0[1:].reshape((len(x0)-1, 1)) [[a],[b]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Yn) #计算参数 f = lambda k: (x0[0]-b/a)*np.exp(-a*(k-1))-(x0[0]-b/a)*np.exp(-a*(k-2)) #还原值 delta = np.abs(x0 - np.array([f(i) for i in range(1,len(x0)+1)])) C = delta.std()/x0.std() P = 1.0*(np.abs(delta - delta.mean()) < 0.6745*x0.std()).sum()/len(x0) return f, a, b, x0[0], C, P #返回灰色预测函数、a、b、首项、方差比、小残差概率
import sys sys.path.append('C:/Users/86152/Documents/chapter6/demo/code') # 设置路径 import numpy as np import pandas as pd from GM11 import GM11 # 引入自编的灰色预测函数 inputfile1 = '../tmp/new_reg_data.csv' # 输入的数据文件 inputfile2 = '../data/data.csv' # 输入的数据文件 new_reg_data = pd.read_csv(inputfile1) # 读取经过特征选择后的数据 data = pd.read_csv(inputfile2) # 读取总的数据 new_reg_data.index = range(1994, 2014) new_reg_data.loc[2014] = None new_reg_data.loc[2015] = None l = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] for i in l: f = GM11(new_reg_data.loc[range(1994, 2014),i].values)[0] new_reg_data.loc[2014,i] = f(len(new_reg_data)-1) # 2014年预测结果 new_reg_data.loc[2015,i] = f(len(new_reg_data)) # 2015年预测结果 new_reg_data[i] = new_reg_data[i].round(2) # 保留两位小数 outputfile = '../tmp/new_reg_data_GM11.xls' # 灰色预测后保存的路径 y = list(data['y'].values) # 提取财政收入列,合并至新数据框中 y.extend([np.nan,np.nan]) new_reg_data['y'] = y new_reg_data.to_excel(outputfile) # 结果输出 print('预测结果为:\n',new_reg_data.loc[2014:2015,:]) # 预测结果展示
LinearSVR()函数后进行预测
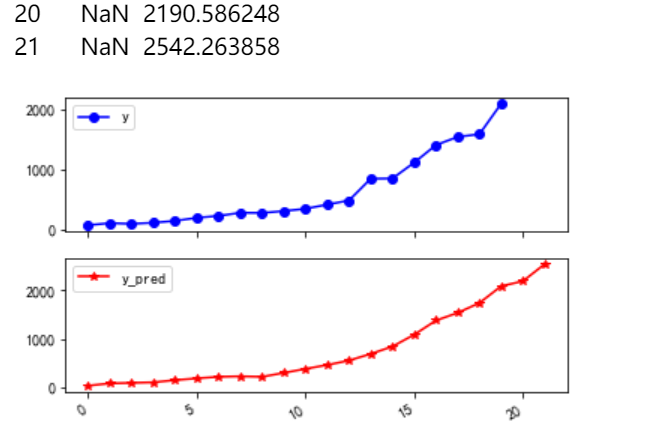
import matplotlib.pyplot as plt from sklearn.svm import LinearSVR inputfile = '../tmp/new_reg_data_GM11.xls' # 灰色预测后保存的路径 data = pd.read_excel(inputfile) # 读取数据 feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] # 属性所在列 data_train = data.iloc[0:20].copy() # 取2014年前的数据建模 data_mean = data_train.mean() data_std = data_train.std() data_train = (data_train - data_mean)/data_std # 数据标准化 x_train = data_train[feature].values # 属性数据 y_train = data_train['y'].values # 标签数据 linearsvr = LinearSVR() # 调用LinearSVR()函数 linearsvr.fit(x_train,y_train) x = ((data[feature] - data_mean[feature])/data_std[feature]).values # 预测,并还原结果。 data['y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y'] outputfile = '../tmp/new_reg_data_GM11_revenue.xls' # SVR预测后保存的结果 data.to_excel(outputfile) print('真实值与预测值分别为:\n',data[['y','y_pred']]) fig = data[['y','y_pred']].plot(subplots = True, style=['b-o','r-*']) # 画出预测结果图 plt.show()
AERIMA
import pandas as pd # 参数初始化 discfile = 'C:/Users/86136/Desktop/python数据挖掘/课本源代码及数据/chapter6/demo/data/data.csv' forecastnum = 5 # 读取数据,指定日期列为指标,pandas自动将“日期”列识别为Datetime格式 data = pd.read_csv(discfile) x = 'y' data = data[[x]] # 时序图 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 data.plot() plt.show() # 自相关图 from statsmodels.graphics.tsaplots import plot_acf plot_acf(data).show() # 平稳性检测 from statsmodels.tsa.stattools import adfuller as ADF print('原始序列的ADF检验结果为:', ADF(data['y'])) # 返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore # 差分后的结果 D_data = data.diff().dropna() D_data.columns = ['收入差分'] D_data.plot() # 时序图 plt.show() plot_acf(D_data).show() # 自相关图 from statsmodels.graphics.tsaplots import plot_pacf plot_pacf(D_data).show() # 偏自相关图 print('差分序列的ADF检验结果为:', ADF(D_data['收入差分'])) # 平稳性检测 # 白噪声检验 from statsmodels.stats.diagnostic import acorr_ljungbox print('差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) # 返回统计量和p值 from statsmodels.tsa.arima_model import ARIMA # 定阶 data['y'] = data['y'].astype(float) pmax = int(len(D_data)/10) # 一般阶数不超过length/10 qmax = int(len(D_data)/10) # 一般阶数不超过length/10 bic_matrix = [] # BIC矩阵 for p in range(pmax+1): tmp = [] for q in range(qmax+1): try: # 存在部分报错,所以用try来跳过报错。 tmp.append(ARIMA(data, (p,1,q)).fit().bic) except: tmp.append(None) bic_matrix.append(tmp) bic_matrix = pd.DataFrame(bic_matrix) # 从中可以找出最小值 p,q = bic_matrix.stack().idxmin() # 先用stack展平,然后用idxmin找出最小值位置。 print('BIC最小的p值和q值为:%s、%s' %(p,q)) model = ARIMA(data, (p,1,q)).fit() # 建立ARIMA(0, 1, 1)模型 print('模型报告为:\n', model.summary2()) print('预测未来5天,其预测结果、标准误差、置信区间如下:\n', model.forecast(5))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号