我的第一个网页
一、文件读写笔记
1、文件的类型
文件概述:-文件时存储在辅助存储器上的数据序列
-文件时数据存储的一种形式
-文件的展现形态:文本文件和二进制文件
文本文件:-由单一特定的编码组成的文件,如UTF-8
-由于存在编码,也被看成时存储着的长字符串
-适用于例如:.txt文件、.py文件等
二进制文件:-之间由比特0和1组成,没有统一字符编码
-一般存在二进制0和1的组织结构,即文件格式
-适用于例如:.png文件、.avi文件等
文本文件和二进制文件打开区别
#文本形式 tf=open("f.txt","rt") print(tf.readline()) tf.close() #二进制形式 bf=open("f.txt","rb") print(bf.readline()) bf.close()
2、文件的打开与关闭
文件处理步骤:打开-操作-关闭
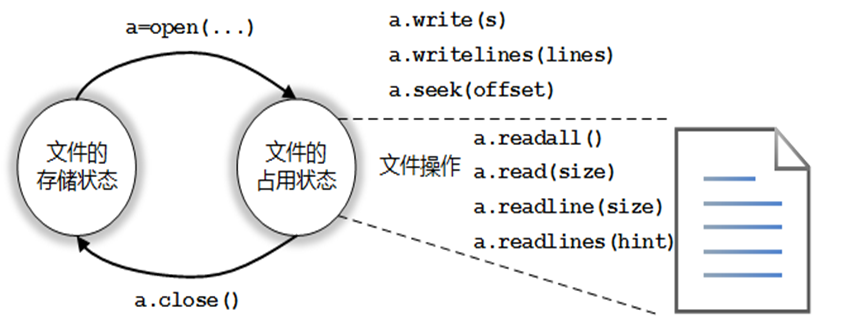
文件的打开:<变量名>=open(<文件名>,<打开模式>)
open()函数提供的7种基本的打开模式:

文件读取4种方法:
|
方法 |
含义 |
|
<file>.readall() |
读入整个文件内容,返回一个字符串或字节流* |
|
<file>.read(size=-1) |
从文件中读入整个文件内容,如果给出参数,读入前size长度的字符串或字节流 |
|
<file>.readline(size = -1) |
从文件中读入一行内容,如果给出参数,读入该行前size长度的字符串或字节流 |
|
<file>.readlines(hint=-1) |
从文件中读入所有行,以每行为元素形成一个列表,如果给出参数,读入hint行 |
实例:
文件全文本操作:
#一次读入。统一处理 fname=input("请输入要打开的文件名称:") fo=open(fname,"r") txt=fo.read fo.close #按数量读入,逐步处理 fname=input("请输入要打开的文件名称:") fo=open(fname,"r") txt=fo.read(2) while txt !="": txt=fo.read(2) fo.close
文件的逐行操作:
#一次读入,分行处理 fname=input("请输入要打开的文件名称:") fo=open(fname,"r") for line in fo.readline(): print(line) txt=fo.read #分行读入。逐行处理 fname=input("请输入要打开的文件名称:") fo=open(fname,"r") for line in fo: print(line) txt=fo.read
文件写入函数:
|
方法 |
含义 |
|
<file>.write(s) |
向文件写入一个字符串或字节流 |
|
<file>.writelines(lines) |
将一个元素为字符串的列表写入文件 |
|
<file>.seek(offset) |
改变当前文件操作指针的位置,offset的值: 0:文件开头; 1: 当前位置; 2: 文件结尾 |
实例:
#写入一个字符串列表 #无输出 fo=open("output.txt","w+") ls=["中国","法国","美国"] fo writelines(ls) for line to fo: print(line) fo.close() #有输出 fo=open("output.txt","w+") ls=["中国","法国","美国"] fo writelines(ls) fo.seek(0) for line to fo: print(line) fo.close()
二、python读入excel文件,更改内容后存为csv格式
import pandas as pd df = pd.read_excel('file:///D:\Python成绩登记信计.xlsx') # 读取excel文件中的数据 print(df) df1=df[:] df1['一']=df1['一'].map({'优秀':90,'良好':80,'及格':60}) df1['二']=df1['二'].map({'优秀':90,'良好':80,'及格':60}) df1['三']=df1['三'].map({'优秀':90,'良好':80,'及格':60}) df1['四']=df1['四'].map({'优秀':90,'良好':80,'及格':60}) df1=df1.fillna(0) print(df1) df1.to_csv('D:\\thon.csv')
运行结果(运行结果过长,这里给出部分做对比):
更改前
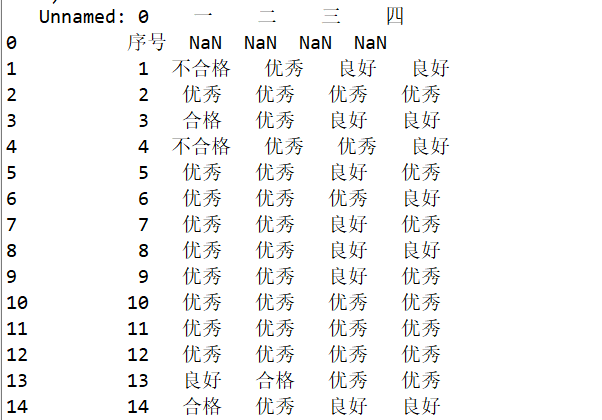
更改后:
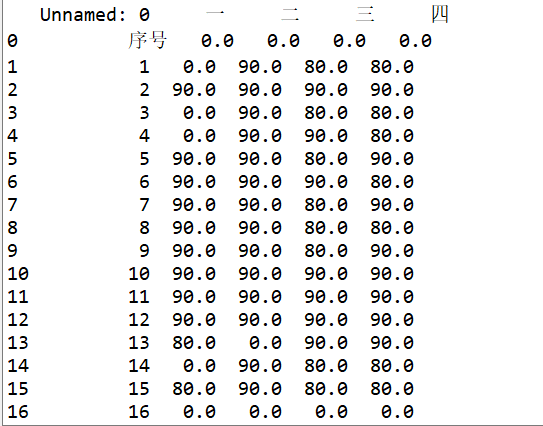
最后将其存为csv文件,会在你保存的文件你多了一个csv文件

三、将上述的csv文件保存为html格式
代码如下:
df1.to_html('d:\\thon1.html')
同样会在你保存的文件夹中会多出一个html格式的文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号