

4-17日报
GraphX
GraphX是Spark中用于图(e.g., Web-Graphs and Social Networks)和图并行计算(e.g., PageRank and Collaborative Filtering)的API,可以认为是GraphLab(C++)和Pregel(C++)在Spark(Scala)上的重写及优化,跟其他分布式图计算框架相比,GraphX最大的贡献是,在Spark之上提供一栈式数据解决方案,可以方便且高效地完成图计算的一整套流水作业。GraphX最先是伯克利AMPLAB的一个分布式图计算框架项目,后来整合到Spark中成为一个核心组件。
GraphX的核心抽象是Resilient Distributed Property Graph,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,有Table和Graph两种视图,而只需要一份物理存储。两种视图都有自己独有的操作符,从而获得了灵活操作和执行效率。如同Spark,GraphX的代码非常简洁。GraphX的核心代码只有3千多行,而在此之上实现的Pregel模型,只要短短的20多行。GraphX的代码结构整体下图所示,其中大部分的实现,都是围绕Partition的优化进行的。这在某种程度上说明了点分割的存储和相应的计算优化的确是图计算框架的重点和难点。
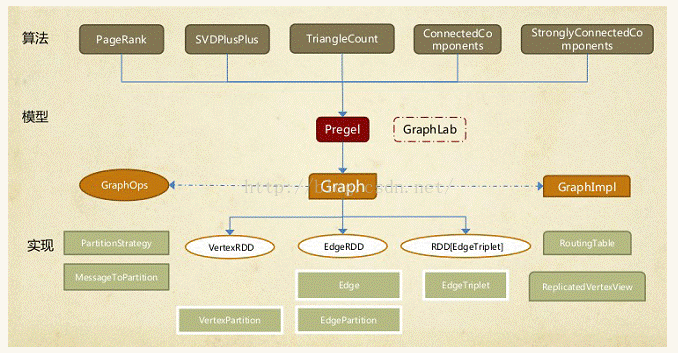
GraphX的底层设计有以下几个关键点。
1.对Graph视图的所有操作,最终都会转换成其关联的Table视图的RDD操作来完成。这样对一个图的计算,最终在逻辑上,等价于一系列RDD的转换过程。因此,Graph最终具备了RDD的3个关键特性:Immutable、Distributed和Fault-Tolerant。其中最关键的是Immutable(不变性)。逻辑上,所有图的转换和操作都产生了一个新图;物理上,GraphX会有一定程度的不变顶点和边的复用优化,对用户透明。
2.两种视图底层共用的物理数据,由RDD[Vertex-Partition]和RDD[EdgePartition]这两个RDD组成。点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartition/EdgePartition在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的,降低了计算和存储开销。
3.图的分布式存储采用点分割模式,而且使用partitionBy方法,由用户指定不同的划分策略(PartitionStrategy)。划分策略会将边分配到各个EdgePartition,顶点Master分配到各个VertexPartition,EdgePartition也会缓存本地边关联点的Ghost副本。划分策略的不同会影响到所需要缓存的Ghost副本数量,以及每个EdgePartition分配的边的均衡程度,需要根据图的结构特征选取最佳策略。目前有EdgePartition2d、EdgePartition1d、RandomVertexCut和CanonicalRandomVertexCut这四种策略。在淘宝大部分场景下,EdgePartition2d效果最好。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具