

4-11日报
Spark SQL
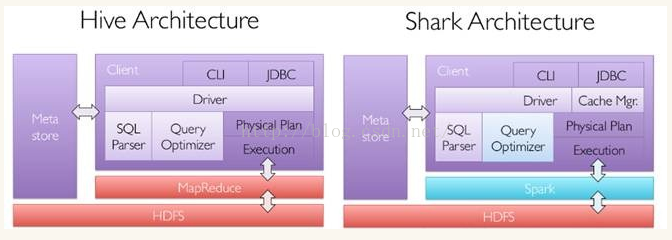
Shark是SparkSQL的前身,它发布于3年前,那个时候Hive可以说是SQL on Hadoop的唯一选择,负责将SQL编译成可扩展的MapReduce作业,鉴于Hive的性能以及与Spark的兼容,Shark项目由此而生。
Shark即Hive on Spark,本质上是通过Hive的HQL解析,把HQL翻译成Spark上的RDD操作,然后通过Hive的metadata获取数据库里的表信息,实际HDFS上的数据和文件,会由Shark获取并放到Spark上运算。Shark的最大特性就是快和与Hive的完全兼容,且可以在shell模式下使用rdd2sql()这样的API,把HQL得到的结果集,继续在scala环境下运算,支持自己编写简单的机器学习或简单分析处理函数,对HQL结果进一步分析计算。
在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。Databricks表示,Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。在会议上,Databricks表示,Shark更多是对Hive的改造,替换了Hive的物理执行引擎,因此会有一个很快的速度。然而,不容忽视的是,Shark继承了大量的Hive代码,因此给优化和维护带来了大量的麻烦。随着性能优化和先进分析整合的进一步加深,基于MapReduce设计的部分无疑成为了整个项目的瓶颈。因此,为了更好的发展,给用户提供一个更好的体验,Databricks宣布终止Shark项目,从而将更多的精力放到Spark SQL上。
Spark SQL允许开发人员直接处理RDD,同时也可查询例如在 Apache Hive上存在的外部数据。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。除了Spark SQL外,Michael还谈到Catalyst优化框架,它允许Spark SQL自动修改查询方案,使SQL更有效地执行。
还有Shark的作者是来自中国的博士生辛湜(Reynold Xin),也是Spark的核心成员,具体信息可以看他的专访 http://www.csdn.net/article/2013-04-26/2815057-Spark-Reynold
Spark SQL的特点:
l引入了新的RDD类型SchemaRDD,可以象传统数据库定义表一样来定义SchemaRDD,SchemaRDD由定义了列数据类型的行对象构成。SchemaRDD可以从RDD转换过来,也可以从Parquet文件读入,也可以使用HiveQL从Hive中获取。
l内嵌了Catalyst查询优化框架,在把SQL解析成逻辑执行计划之后,利用Catalyst包里的一些类和接口,执行了一些简单的执行计划优化,最后变成RDD的计算
l在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。
Shark的出现使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高, 那么,摆脱了Hive的限制,SparkSQL的性能又有怎么样的表现呢?虽然没有Shark相对于Hive那样瞩目地性能提升,但也表现得非常优异,如下图所示:
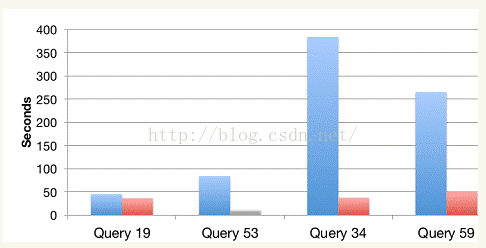
为什么sparkSQL的性能会得到怎么大的提升呢?主要sparkSQL在下面几点做了优化:
1. 内存列存储(In-Memory Columnar Storage) sparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储;
2. 字节码生成技术(Bytecode Generation) Spark1.1.0在Catalyst模块的expressions增加了codegen模块,使用动态字节码生成技术,对匹配的表达式采用特定的代码动态编译。另外对SQL表达式都作了CG优化, CG优化的实现主要还是依靠Scala2.10的运行时放射机制(runtime reflection);
3. Scala代码优化 SparkSQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说接口统一。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具