3-23日报
工作流程分析
(1)发送数据
我们看上面的架构图中,producer就是生产者,是数据的入口。注意看图中的红色箭头,Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?我们看下图: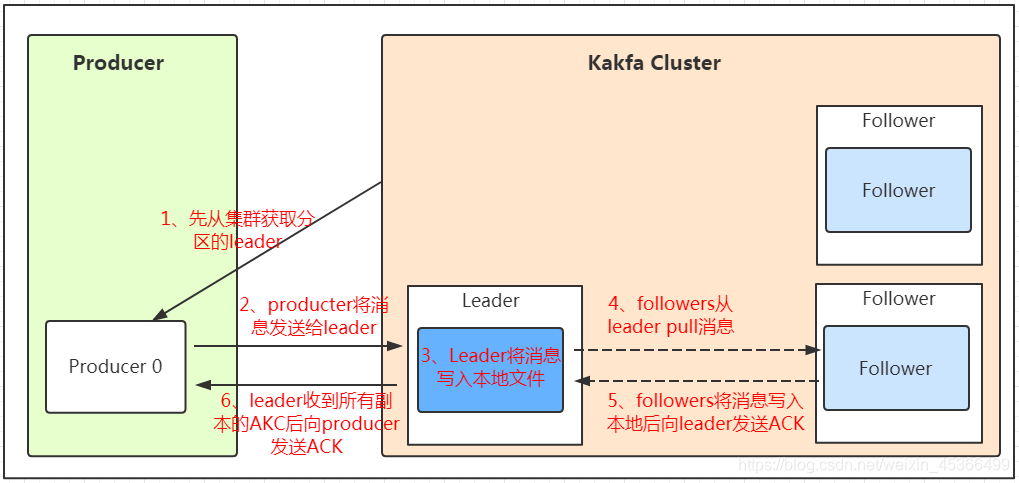
发送的流程就在图中已经说明了,就不单独在文字列出来了!需要注意的一点是,消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!写入示意图如下: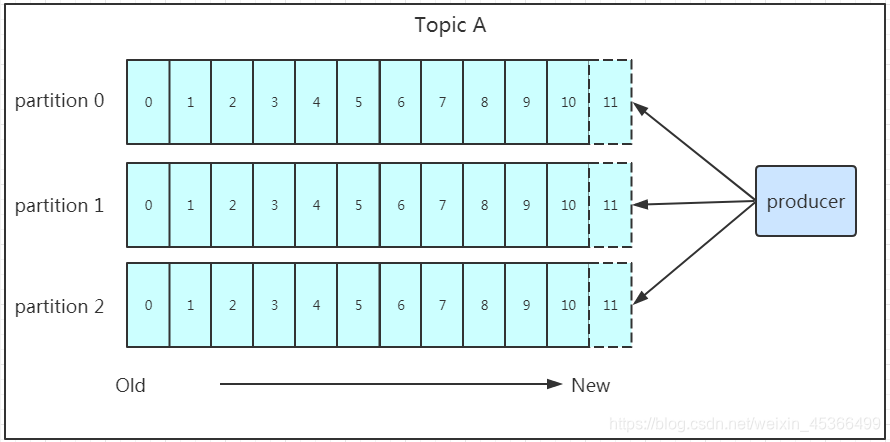
上面说到数据会写入到不同的分区,那kafka为什么要做分区呢?相信大家应该也能猜到,分区的主要目的是:
- 方便扩展:因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
- 提高并发:以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
熟悉负载均衡的朋友应该知道,当我们向某个服务器发送请求的时候,服务端可能会对请求做一个负载,将流量分发到不同的服务器,那在kafka中,如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?kafka中有几个原则:
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
- 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?其实上面的写入流程图中有描述出来,那就是通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。

