

12-1每日博客
Mapreduce实例——倒排索引
"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
实现"倒排索引"主要关注的信息为:单词、文档URL及词频。
下面以本实验goods3、goods_visit3、order_items3三张表的数据为例,根据MapReduce的处理过程给出倒排索引的设计思路:
(1)Map过程
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词、文档URL和词频,接着我们对读入的数据利用Map操作进行预处理,如下图所示:
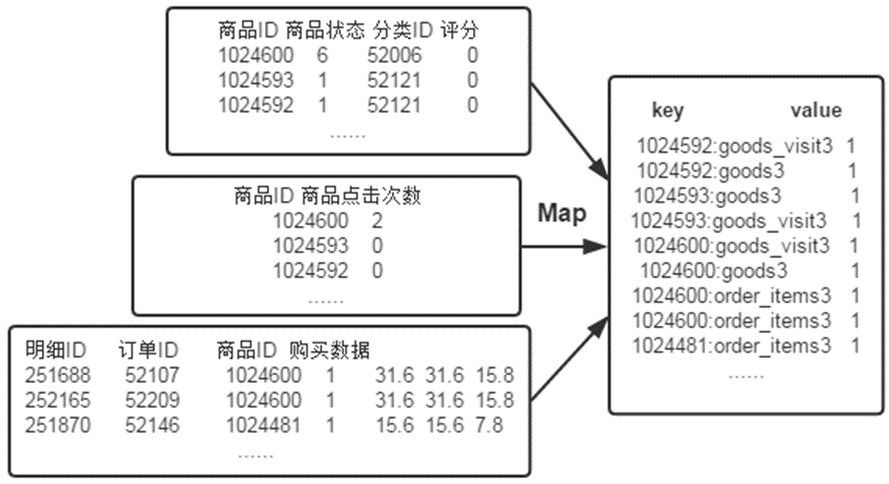
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词、文档URL和词频,这里存在两个问题:第一,<key,value>对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值。第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档中的词频。如果直接将输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词作为key值,URL和词频组成value值。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。
经过上述两个过程后,Reduce过程只需将相同key值的value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。
代码如下:
package exper;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyIndex {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("InversedIndexTest");
job.setJarByClass(MyIndex.class);
job.setMapperClass(doMapper.class);
job.setCombinerClass(doCombiner.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in1 = new Path("D:\\mapreduce\\8in\\goods3\\goods.txt");
Path in2 = new Path("D:\\mapreduce\\8in\\goods_visit3\\goods_visit3.txt");
Path in3 = new Path("D:\\mapreduce\\8in\\order_item3\\order_items3.txt");
Path out = new Path("file:///D:/mapreduce/8out");
FileInputFormat.addInputPath(job, in1);
FileInputFormat.addInputPath(job, in2);
FileInputFormat.addInputPath(job,in3);
FileOutputFormat.setOutputPath(job,out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, Text> {
public static Text myKey = new Text();
public static Text myValue = new Text();
//private
FileSplit filePath;
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String filePath = ((FileSplit)
context.getInputSplit()).getPath().toString();
if (filePath.contains("goods")) {
String val[] = value.toString().split(" ");
int splitIndex = filePath.indexOf("goods");
myKey.set(val[0] + ":" + filePath.substring(splitIndex));
} else if (filePath.contains("order")) {
String val[] = value.toString().split(" ");
int splitIndex = filePath.indexOf("order");
myKey.set(val[2] + ":" + filePath.substring(splitIndex));
}
myValue.set("1");
context.write(myKey, myValue);
}
}
public static class doCombiner extends Reducer<Text, Text, Text, Text> {
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int mysplit = key.toString().indexOf(":");
myK.set(key.toString().substring(0, mysplit));
myV.set(key.toString().substring(mysplit + 1) + ":" + sum);
context.write(myK, myV);
}
}
public static class doReducer extends Reducer<Text, Text, Text, Text> {
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String myList = new String();
for (Text value : values) {
myList += value.toString() + ";";
}
myK.set(key);
myV.set(myList);
context.write(myK, myV);
}
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具