(笔记)sklearn入门 2.1 数据集的划分和流行数据集获取、转换器和估计器介绍
数据集划分
机器学习一般的数据集会划分为两个部分:
训练数据(训练集):用于训练,构建模型
测试数据(测试集):在模型检验时使用,用于评估模型是否有效
训练集和测试集的比一般有7:3, 4:1, 3:1

划分的api : sklearn.model_selection.train_test_split
获取流行数据集:



from sklearn.datasets import load_iris # 鸢尾花数据集
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
if __name__ == '__main__':
li = load_iris()
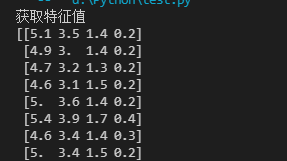
print('获取特征值')
print(li.data)
print('目标值')
print(li.target)
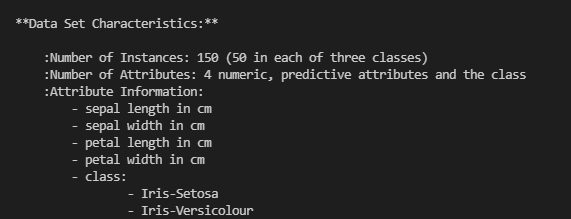
print(li.DESCR)
部分结果:

对数据集进行分割

from sklearn.datasets import load_iris # 鸢尾花数据集
from sklearn.model_selection import train_test_split
if __name__ == '__main__':
li = load_iris()
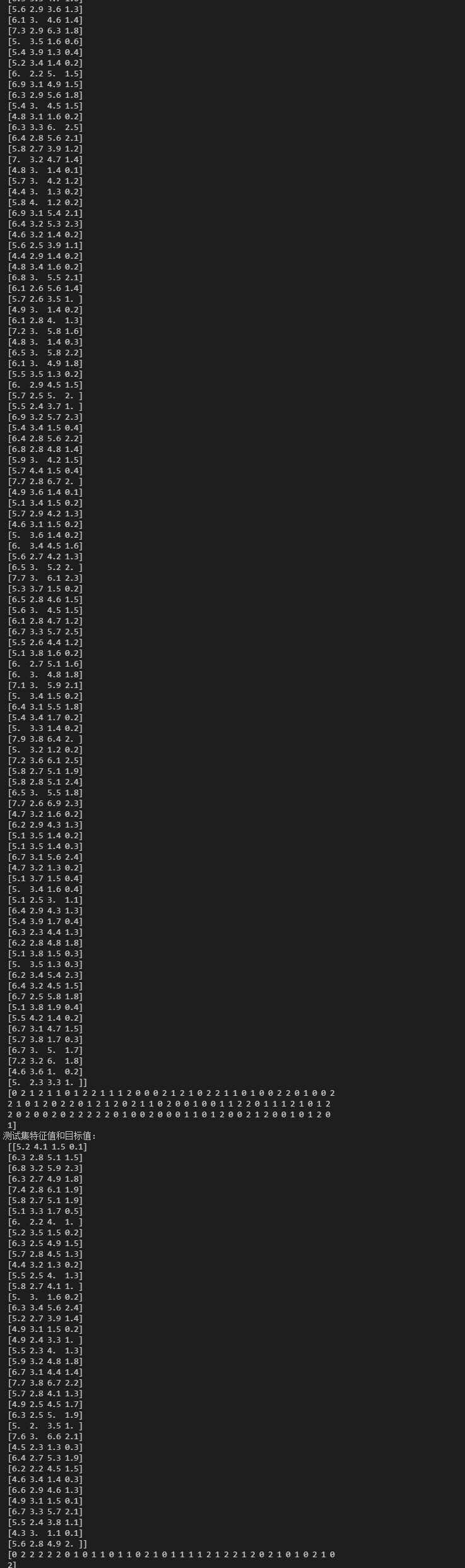
# 注意返回值 训练集 train x_train y_train 目标集 test x_test y_test
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25) # test_size测试集大小
print('训练集特征值和目标值:\n', x_train,'\n', y_train)
print('测试集特征值和目标值:\n', x_test,'\n', y_test)
用于分类的大数据集

from sklearn.datasets import fetch_20newsgroups #
from sklearn.model_selection import train_test_split
if __name__ == '__main__':
news = fetch_20newsgroups(subset='all')
print(news.data)
print(news.target)
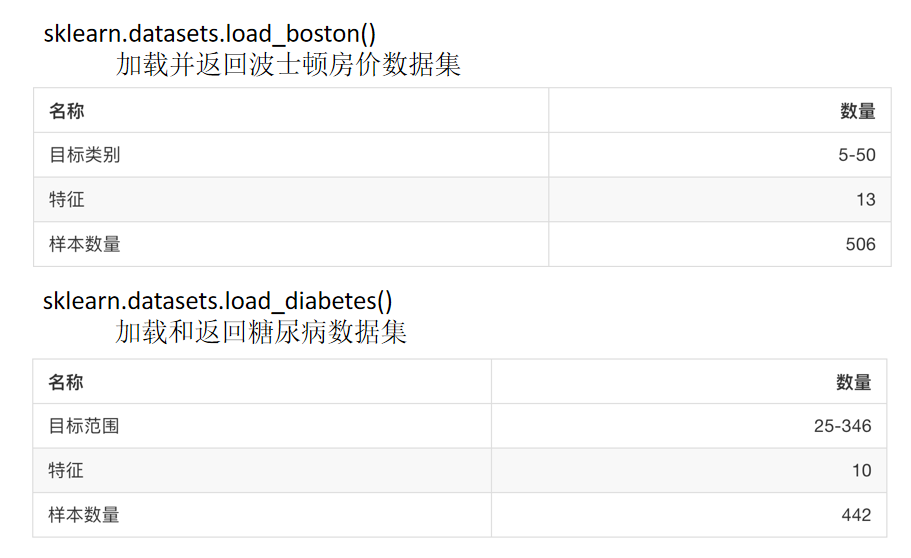
sklearn回归数据集
转换器和估计器
转换器
fit()计算每一列的平均值、标准差
transform() 进行标准化
\(X' = \frac{x - mean}{\sigma}\)
作用于每一列,\(mean\)为平均值,\(σ\)为标准差(考量数据的稳定性)
\(var\)称为方差,\(var = \frac{\sum(x-mean)^2}{n(每个特征的样本数)}\) , \(\sigma = \sqrt{var}\)
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
if __name__ == '__main__':
# fit()计算每一列的平均值、标准差
# transform() (x-mean)/std
# fit_transform 等同于 fit + transform
s = StandardScaler()
data = s.fit_transform([[1,2,3],[4,5,6]])
print(data,'\n')
ss = StandardScaler()
data = ss.fit([[1,2,3],[4,5,6]])
print(data,'\n')
data = ss.transform([[1,2,3],[4,5,6]])
print(data,'\n')
#--------------------------------------------------------
ss.fit([[2,3,4],[4,5,7]]) # fit 之后标准改了
data = ss.transform([[1,2,3],[4,5,6]])
print(data)
估计器

过程:
x_train特征值,y_train目标值
1、调用fit(x_train, y_train)进行训练
2、输入测试集的数据,进行sorce(x_train,y_train)得到结果精度和predict(x_train)得到预测结果
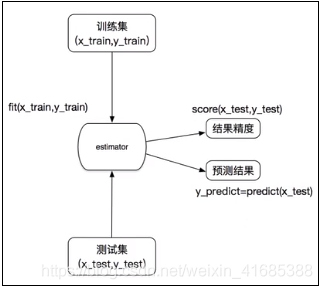
利用训练集构建一个机器学习模型,模型构建好之后可以利用测试集来评估我们模型的性能。

