
Zookeeper原理
zookeeper 服务注册,监听和客户端通知机制的服务
集群:一个laeder 多个follower,奇数
1、读操作可以经过follower,主挂了从节点选举
2、半数以上损坏
3、全局数据一致
4、客户请求依次执行,先进先出
5、数据更新原子性,一次数据更新要么成功,要么失败。
6、实时性,集群内数据同步,client能读取到最新数据。
数据解构,存储
数据量很小,默认只有1MB,只存储配置信息
应用场景
统一命名服务:注册服务统一命名
统一配置管理:1、一个集群中,所有节点的配置信息是一致的 2、配置统一管理,动态更新,客户端实时加载
统一集群管理:节点注册状态监听,动态做出调整
服务器动态上下线:注册节点服务可以实现动态上下线
软负载均衡:注册服务统一命名后,这个服务可以注册多个服务节点,对客户端请求进程动态负载均衡。
集群安装
最少三台
配置修改
端口:2181 客户端连接地址
2888:主从同步数据
3888:选举端口


zk去读取server.x 这个x就是myid里面的id,通过这个文件查看谁是leader
集群选举机制
初次启动选举:myid大的选票优先,由于要半数以上机制,3启动后自己投自己一票,1和2的myid小于3,2和1将自己的选票都投给3,那么3有了三票,变成了leader。那么当4启动后,由于集群中有leader,无论后面启动的myid多大,都无法变成lerder。
主挂了怎么选举:
1、当某一台zk节点发现无法与leader通信,发起选举请求,但是由于要通过半数以上节点,其他节点告知leader节点存在的信息后,重新与leader机器进行通信,同步数据。
2、当半数以上节点认为leader挂了,集群中根据zxid和sid进行选举,zxid大的被选为leader,如果zxid一致,比较sid,sid大的被选为leader。
sid/myid:集群内服务id
zxid:事务id,标识服务器状态的变更,zxid越大,当前节点数据越新。在某一时刻,集群中节点的事务id不完全一致。
Epoch:每隔leader的的任期编号,例如当前领导的 epoch 为 5,当重新选举后,epoch值会增加+1,防止旧leader5恢复后重新被选举,选举完成后,所有节点更新当前leader的epoch值为6。
配置文件详解
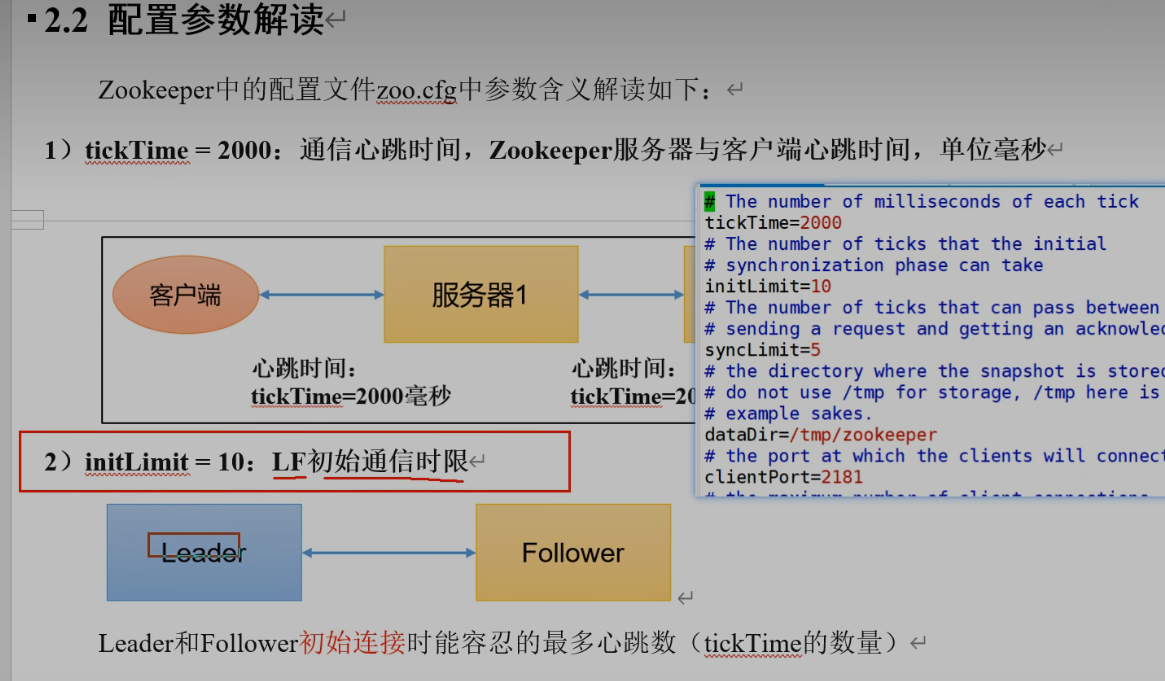

主从心跳间隔时间2s
最多10*2=20s初始化时间,主从未建立连接,则认为初始化失败
主从初始化完成后,数据之间同步超时时间。心跳2*5=10s
数据目录
客户端连接端口
客户端连接操作
命令行
创建节点
-s 带编号,可以重复创建,但是会编号递增+1
-e 临时节点,退出节点删除
create 创建
get 获取
set修改
监听器原理
1、客户端创建两个线程,一个负责网络连接通信,一个负责监听节点状态变化
2、通过connect线程将注册的监听事件发送给zk
3、在zk的注册监听器将注册的监听事件添加到列表中
4、zk监听到数据或路径变化,就会把这个消息发送给listener线程,通知客户端。
监听节点状态,配置。
命令:注册监听器,监听节点值变化
# 注册监听器,监听节点值变化 get -w /sanguo # 修改node节点值 set /sanguo "yangguifei" # 监听注册一次只能监听一次,再次注册监听才能继续监听
代码方式连接zk
zk写数据原理
1、对leader进行写操作,leader写完成后同步数据给follower,follower写完成回复ack 给leader,只要超过半数的follower确认写完成就可以通知客户端写完成,接下来继续同步数据给其他follower。
2、如果直接给follower写数据,follower会转给leader写,重复步骤1操作,但是还是由客户端连接的follower节点给客户回复ack应答。
服务器动态上下线监听案例
所谓注册就是创建节点,临时还是永久 -e,是否序列号 -s
监听就是监听节点,路径,值 变化
分布式锁
本文来自博客园,作者:不会跳舞的胖子,转载请注明原文链接:https://www.cnblogs.com/rtnb/p/18245681

 浙公网安备 33010602011771号
浙公网安备 33010602011771号