nginx 压测、高并发优化
前言
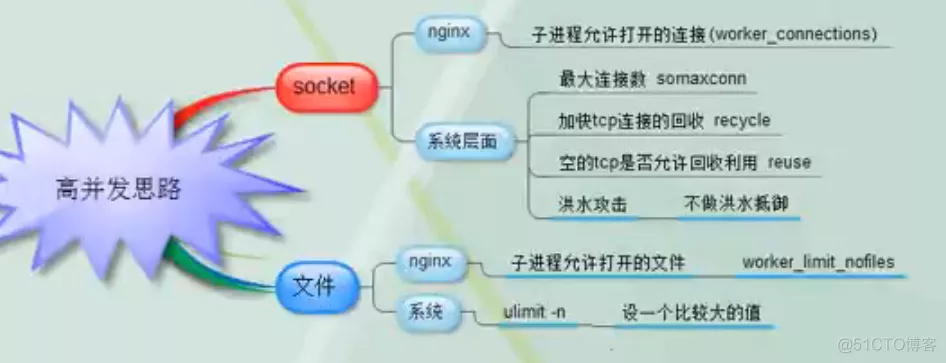
在做并发优化前,了解下什么叫做并发
连接与请求
- 连接:指的是客户端和服务器之间的TCP连接。在HTTP/1.1及更高版本中,默认启用了Keep-Alive连接,允许多个HTTP请求复用一个TCP连接。
- 请求:指的是在一个TCP连接中,客户端向服务器发送的具体HTTP请求。
并发连接数
并发连接数通常指的是在某一时间点上,服务器同时处理的活跃TCP连接数。这与每个连接中发送的请求数无关。因此:
- 如果一个客户端建立一个TCP连接(并保持该连接打开),则这个连接会被算作一个并发连接。
- 在一个并发连接内,即使客户端每秒发送多个请求,该连接在计数上仍然算作一个并发连接。
请求处理能力
服务器处理请求的能力可以用请求率来衡量,通常以每秒处理的请求数(RPS,即Requests Per Second)为单位。在一个TCP连接中:
- 单个并发连接:如果客户端在一个连接中每秒发送多个请求,服务器需要处理的请求数增加,但并发连接数保持不变。
- 多个并发连接:如果有多个并发连接,每个连接中都在发送多个请求,服务器需要处理的总请求数和总连接数都会增加。
配置和监控
-
Nginx配置:
- 连接数:由
worker_processes和worker_connections决定。 - 请求数:Nginx高效处理请求的能力与事件驱动架构有关。
- 连接数:由
-
HAProxy配置:
- 连接数:由
maxconn参数决定。 - 请求数:可以通过调整队列和缓冲区来优化处理能力。
- 连接数:由
示例场景
假设有一个Nginx服务器,配置如下:
worker_processes 4; events { worker_connections 1024; }
根据配置,每个工作进程可以处理1024个连接,因此总共可以处理的最大并发连接数是:
4×1024=4096
假设每个连接中的客户端每秒发送10个请求,那么在处理最大并发连接数的情况下,每秒的总请求数是:
4096×10=40960 RPS
了解完什么是并发后,看下如何查看并发和请求
实时监控
通过实时监控连接数和请求数,可以更好地了解服务器的负载情况。
Nginx
使用stub_status模块查看当前连接数和请求数:
location /nginx_status { stub_status; allow 127.0.0.1; deny all; }
查看指标
Active connections: 291 server accepts handled requests 802024 802024 1604037 Reading: 12 Writing: 43 Waiting: 236
参数详细解释
-
Active connections: 291
- 解释:当前正在处理的活跃连接数。这包括正在读取请求、发送响应和处于Keep-Alive状态的连接。
- 作用:反映当前Nginx服务器的总负载情况。
-
server accepts handled requests
- 解释:这行包含三个累积计数器,分别表示自Nginx启动以来的总连接数、总处理的连接数和总处理的请求数。
- 各个值的含义:
- 802024(accepts):服务器接受的总连接数。
- 802024(handled):成功处理的总连接数。通常与accepts相同,除非Nginx由于资源限制或其他原因放弃了一些连接。
- 1604037(requests):处理的总请求数。因为一个连接可以处理多个请求(Keep-Alive连接),所以这个值通常大于handled的值。
-
Reading: 12
- 解释:当前Nginx正在读取客户端请求头的连接数。
- 作用:反映正在处理请求头数据的连接数量,有助于了解当前的输入流量。
-
Writing: 43
- 解释:当前Nginx正在向客户端发送响应数据的连接数。
- 作用:反映正在处理响应输出的连接数量,有助于了解输出流量和处理速度。
-
Waiting: 236
- 解释:处于Keep-Alive状态、等待下一次请求的空闲连接数。
- 作用:反映连接保持活动但当前没有传输数据的连接数量。这些连接可能会随时发送新的请求。
如何使用这些信息
- Active connections:如果这个值过高,可能意味着服务器负载过大,需要增加Nginx实例或调整配置。
- accepts和handled:通常这两个值相等,如果有显著差异,可能存在连接被拒绝或处理失败的情况。
- requests:这个值随着时间增长,反映了服务器处理的请求量。高请求数可能需要优化Nginx配置或后端应用。
- Reading和Writing:这些值帮助识别当前服务器主要是接收数据(Reading)还是发送数据(Writing),有助于分析性能瓶颈。
- Waiting:高等待数表示大量Keep-Alive连接,如果服务器资源有限,可以考虑调整Keep-Alive超时时间以减少等待连接数。
并发计算方式
nginx 并发量计算:最大并发连接数=worker_processes×worker_connections
haproxy并发量计算:
系统资源限制
在设置HAProxy的最大连接数之前,必须确保操作系统支持所需的文件描述符数量。每个连接通常需要一个文件描述符,因此要确保系统的文件描述符限制足够高。
临时设置限制(仅对当前会话有效):
ulimit -n 65535
永久设置限制(编辑 /etc/security/limits.conf):
* soft nofile 65535 * hard nofile 65535
还需要调整系统的内核参数,以支持大量的并发连接。编辑 /etc/sysctl.conf 文件,并添加以下设置:
net.core.somaxconn=10240 net.ipv4.tcp_max_tw_buckets=5000 net.ipv4.tcp_max_syn_backlog=5000 net.ipv4.tcp_fin_timeout=30 net.ipv4.ip_local_port_range = 1024 65535
全局所有进程可打开的文件描述符数量
[root@master-1 ~]# cat /proc/sys/fs/file-max 6815744
配置HAProxy的最大连接数
假设系统已经配置好文件描述符限制和内核参数,可以根据实际需求设置HAProxy的global maxconn参数。由于你提到的Nginx示例是4核,每个核可以处理65535个连接,总计约26万连接,我们可以使用类似的配置来设置HAProxy。
global maxconn 100000 # 不能超过系统文件描述符 chroot /usr/local/haproxy stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin uid 188 gid 188 daemon #nbproc 2 nbthread 4 cpu-map 1/1 0 cpu-map 1/2 1 cpu-map 1/3 2 cpu-map 1/4 3 pidfile /var/lib/haproxy/haproxy.pid log 127.0.0.1 local3 info spread-checks 5 defaults option http-keep-alive option forwardfor option redispatch maxconn 100000 mode http timeout http-keep-alive 120s timeout connect 1000ms timeout client 600ms timeout server 600ms timeout check 5s listen stats mode http bind 0.0.0.0:9999 stats enable stats uri /haproxy-status stats auth haadmin:123456 listen kube-apiserver balance roundrobin bind 0.0.0.0:8443 server web1 192.168.0.120:6443 check inter 3000 fall 2 rise 3 server web2 192.168.0.61:6443 check inter 3000 fall 2 rise 3 server web3 192.168.0.192:6443 check inter 3000 fall 2 rise 3 listen nginx balance roundrobin bind 0.0.0.0:8079 server web1 192.168.0.120:8078 check inter 3000 fall 2 rise 3 server web2 192.168.0.61:8078 check inter 3000 fall 2 rise 3
注意事项
- 系统资源监控:尽管理论上可以设置很高的最大连接数,但实际使用中应该监控系统资源(CPU、内存、网络等)的使用情况,确保不会因为过高的并发连接数导致系统资源耗尽。
- 连接数配置一致性:确保操作系统、Nginx和HAProxy的文件描述符限制配置一致,避免不一致导致连接失败。
- 性能测试:在生产环境中使用前,进行充分的性能测试,以确定系统能够稳定处理配置的最大连接数。
参数调优
[root@master-1 ~]# ulimit -n
65535
[root@master-1 ~]# cat /proc/sys/fs/file-max
6815744
这两有什么区别吗,为什么不一样
作用范围:
ulimit -n:针对单个用户进程,设置单个进程可以打开的文件描述符数。
/proc/sys/fs/file-max:针对整个系统,设置系统所有进程可以打开的文件描述符总数。
实际应用
假设一个系统有多个用户进程,每个进程的文件描述符限制是65535,如果有100个这样的进程同时运行,理论上它们最多可以使用65535 * 100 = 6553500个文件描述符。但是,由于系统的总限制是6815744,这意味着即使每个进程设置了较高的文件描述符限制,总数也不能超过系统级的6815744。
nginx高可用集群安装,并使用haproxy+keepalived做代理
两台nginx+haproxy+keepalived
192.168.0.120
192.168.0.61
nginx 部分配置
user nginx; worker_processes auto; worker_cpu_affinity auto; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; worker_rlimit_nofile 65535; # 每个工作进程可以打开的文件描述符数量 events { worker_connections 65535; # 每个工作进程可以连接的数量 use epoll; accept_mutex on; multi_accept on; } http { include mime.types; default_type application/octet-stream; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; gzip on; server { listen 8078; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; } location /nginx_status { stub_status; access_log off; } }
haproxy配置
global maxconn 100000 chroot /usr/local/haproxy stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin uid 188 gid 188 daemon #nbproc 2 nbthread 4 cpu-map 1/1 0 cpu-map 1/2 1 cpu-map 1/3 2 cpu-map 1/4 3 pidfile /var/lib/haproxy/haproxy.pid log 127.0.0.1 local3 info spread-checks 5 defaults option http-keep-alive option forwardfor option redispatch maxconn 100000 mode http timeout http-keep-alive 120s timeout connect 1000ms timeout client 600ms timeout server 600ms timeout check 5s listen stats mode http bind 0.0.0.0:9999 stats enable stats uri /haproxy-status stats auth haadmin:123456 listen nginx balance roundrobin bind 0.0.0.0:8079 server web1 192.168.0.120:8078 check inter 3000 fall 2 rise 3 server web2 192.168.0.61:8078 check inter 3000 fall 2 rise 3
keepalived
! Configuration File for keepalived global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } router_id haproxy-2 } vrrp_script chk_haproxy { user root script "/etc/keepalived/check_haproxy.sh" interval 2 weight -10 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 110 nopreempt advert_int 1 authentication { auth_type PASS auth_pass 88888888 } virtual_ipaddress { 192.168.0.190 } track_script { chk_haproxy } }
ab压力测试工具讲解
使用ab命令,对nginx进行压力测试 1、安装ab命令 yum install httpd-tools -y apt install apache2-utils 2、使用ab命令对nginx发送大量的链接 -n 请求数量 # 一共发出多少个请求 -n 10000 -c 请求并发数 -c 100 -k # 表示启动keepalived保持链接功能 ab -kc 1000 -n 100000 http://127.0.0.1/
安装磁盘查看工具
yum install sysstat
参数详解
ab -c 1000 -n 10000 http://192.168.2.38/ # -c指定1000并发,-n指定总10000次,相当于1000个人访问10次。 # -k 是否开启长连接 Server Software: nginx/1.8.1 #服务器信息和版本 Server Hostname: 192.168.2.38 #服务器的域名 Server Port: 80 #端口 Document Path: / #访问的路径 Document Length: 612 bytes #文档的大小为 612 bytes(此为http响应的正文长度) Concurrency Level: 1000 #并发请求数 Time taken for tests: 0.287 seconds #整个测试持续的时间,默认秒 Complete requests: 1000 #完成的请求数 Failed requests: 0 #失败的请求书 Write errors: 0 #网络连接写入错误数 Total transferred: 844000 bytes #传输的总数据量 HTML transferred: 612000 bytes #传输的HTML内容传输量 Requests per second: 3485.11 [#/sec] (mean) #平均每秒请求数 Time per request: 286.935 [ms] (mean) #所有用户都请求一次的平均时间 Time per request: 0.287 [ms] (mean, across all concurrent requests) #单个用户请求一次的时间 Transfer rate: 2872.49 [Kbytes/sec] received #传输速率 Connection Times (ms) min mean[+/-sd] median max Connect: 0 84 4.1 84 94 Processing: 86 99 6.6 100 109 Waiting: 0 83 16.2 84 108 Total: 95 183 7.4 182 195 #所有服务请求的百分比占用时间,这里50%的请求用时182ms,一般看90%的部分 Percentage of the requests served within a certain time (ms) 50% 182 66% 188 75% 191 80% 192 90% 193 95% 194 98% 194 99% 194 100% 195 (longest request)
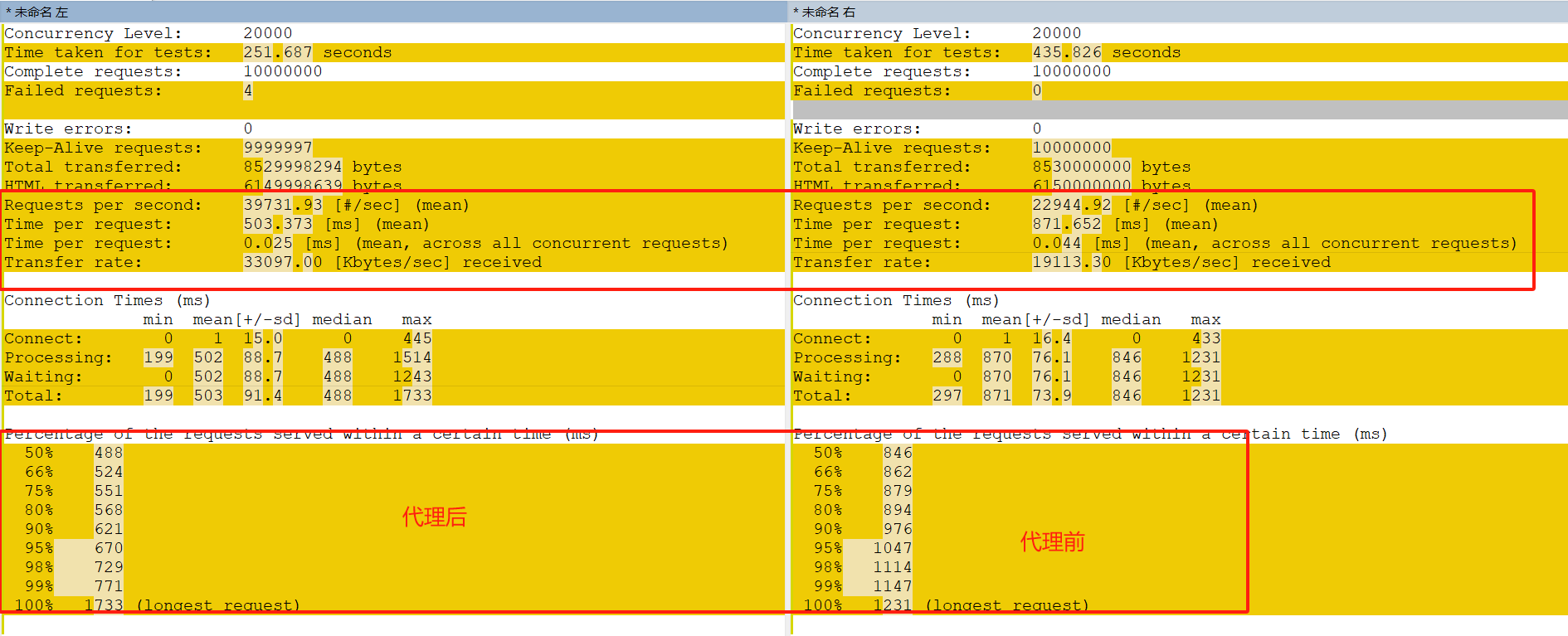
并发测试
代理后并发与单个nginx并发对比
可以看到每秒请求数,单个请求用时,请求速率,百分比用时都大大缩小。
如何设置监控呢
使用Prometheus监控Nginx的请求数是一个有效的方法。为了计算1分钟内处理的请求数,我们需要定义适当的范围,并了解如何监控和评估这些数据。
设定合理的范围
-
基准测试和容量规划:
- 在定义合适的请求范围前,首先需要了解Nginx服务器的处理能力。这可以通过基准测试来获得。
- 使用工具如
ab(ApacheBench)、wrk或JMeter进行负载测试,确定Nginx在不同负载条件下的性能表现。
示例
假设在基准测试中,Nginx服务器的处理能力是每秒1000个请求(RPS),那么1分钟内处理的请求数理论最大值为:
1000 RPS×60 seconds=60000 requests/minute
在实际生产环境中,可能会有不同的负载情况:
- 低负载:1000 - 5000 requests/minute
- 中等负载:5000 - 20000 requests/minute
- 高负载:20000 - 60000 requests/minute
使用Prometheus监控数据可以帮助确定实际的负载范围。例如,查询结果显示过去1分钟的请求数在20000 - 60000之间,结合服务器的资源使用情况和响应时间,可以评估这个范围是否合理。
本文来自博客园,作者:不会跳舞的胖子,转载请注明原文链接:https://www.cnblogs.com/rtnb/p/18238885

 浙公网安备 33010602011771号
浙公网安备 33010602011771号