ELK—filebeat+logstash+redis/kafka+logstash+elasticsearch+kibana日志收集
1、Kibana--->keepalived VIP + haproxy 代理elasticsearch 集群 <---- logstash 数据写入
2、Kibana--->keepalived VIP + haproxy 代理elasticsearch 集群 <—— logstash <—— filebeat数据收集
3、Kibana--->keepalived VIP + haproxy 代理elasticsearch 集群 <—— logstash <——redis/kafka/rabiitMQ 数据缓冲(解耦)<—— logstash<—— filebeat数据收集
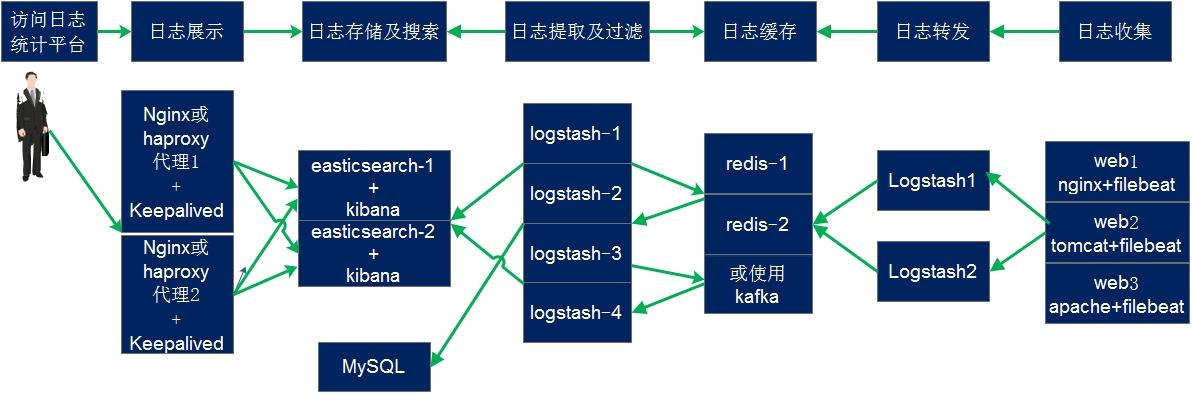
架构 规划
在下面的图当中从左向右看,当要访问 ELK 日志统计平台的时候,首先访问的是两台 nginx+keepalived 做的负载高可用,访问的地址是 keepalived 的 IP,当一台 nginx 代理服务器挂掉之后也不影响访问,然后 nginx 将请求转发到kibana,kibana 再去 elasticsearch 获取数据;
elasticsearch 是两台做的集群,数据会随机保存在任意一台 elasticsearch 服务器,同样可以使用VIP访问集群;
redis 服务器做数据的临时保存,避免 web 服务器日志量过大的时候造成的数据收集与保存不一致导致的日志丢失,可以临时保存到 redis,redis 可以是集群,然后再由 logstash 服务器在非高峰时期从 redis 持续的取出即可;
另外有一台 mysql 数据库服务器,用于持久化保存特定的数据,web 服器的日志由 filebeat 收集之后发送给另外的一台logstash,再由其写入到 redis 即可完成日志的收集,从图中可以看出,redis 服务器处于前端结合的最中间,其左右都要依赖于 redis 的正常运行,web 服务日志经过 filebeat 收集之后通过日志转发层的 logstash 写入到 redis 不同的 key当中,然后提取层 logstash 再从 redis 将数据提取并安按照不同的类型写入到elasticsearch 的不同 index 当中,用户最终通过 nginx 代理的 kibana 查看到收集到的日志的具体内容:
官 方 文 档 : https://www.elastic.co/guide/en/beats/filebeat/current/logstash-output.html
测试多行匹配,并将输出改为 logstash 进根据日志类型判断写入到不同的 redis key 当中,在一个 filebeat 服务上面同时收集不同类型的日志,比如收集系统日志的时候还要收集 tomcat 的访问日志,那么直接带来的问题就是要在写入至 redis 的时候要根据不同的日志类型写入到 reids 不通的key 当中,首先通过 logstash 监听一个端口,并做标准输出测试
filebeat设置
grep -v "#" /etc/filebeat/filebeat.yml | grep -v "^$" filebeat.input: - type: log enable: true paths: - /var/log/messages fields: type: "system-log" # 用于区分日志类型,将数据写入缓冲redis,logstash通过这个key区分写入不同的index host: 192.168.64.113 - type: log enable: true paths: - /var/log/nginx/access.log fields: type: "nginx-access-log" host: 192.168.64.113 output.logstash: host: ["192.168.64.111:5044", "192.168.64.111:5045"] # logstash监听的端口,由于资源有限,这里启用两个端口模拟两台logstash实现高可用+轮询 loadbalance: "true" # 负载均衡加健康检查 worker: 2 # 每个主机开启的工作进程 compression_level: 3 # 压缩
logstash配置 接收filebeat日志,写入redis
input { beat { port => 5044 # 为什么启动两个端口?答:模拟logstash多台机器 codec => "json" } beat { port => 5045 codec => "json" # 收集日志对日志进行json解析 } } output { if [fields][type] == "system-log" { # 因为filebeat无法根据日志类型判断,所以还需要添加logstash对收集到的日志类型进行判断,写入到哪个key或者哪个DB redis { host => "192.168.64.110" port => "6379" db => 2 password => "123456" data_type => "list" key => "system-log" # 自定义key名称,默认是type名称 } } if [fields][type] == "nginx-access-log" { redis { host => "192.168.64.110" port => "6379" db => 1 # 不同类型写入到不同db password => "123456" data_type => "list" key => "nginx-access-log-web" # 自定义key名称,默认是type名称 codec => "json" # json类型的日志必须指定json,写入的 时候用 使用 json 编码 ,为 因为 logstash 收集后会转换成json } } }
logstash读取redis数据,写入es集群
input { redis { host => "192.168.64.110" port => "6379" db => 1 password => "123456" data_type => "list" key => "nginx-access-log-web" } redis { host => "192.168.64.110" port => "6379" db => 2 password => "123456" data_type => "list" key => "system-log" } } output { if [fields][type] == "system-log" { elasticsearch { host => ["192.168.64.110:9200"] # 可以指定es 集群的VIP index => "system-log-%{+YYYY.MM.dd}" db => 2 } } if [fields][type] == "nginx-access-log" { elasticsearch { host => ["192.168.64.110:9200"] # 可以指定es 集群的VIP index => "nginx-access-log-%{+YYYY.MM.dd}" codec => "json" } }
}
logstash接收日志,写入kafka
input { beat { port => 5044 # 为什么启动两个端口?答:模拟logstash多台机器 codec => "json" } beat { port => 5045 codec => "json" # 收集日志对日志进行json解析 } } output { if [fields][type] == "system-log" { # 因为filebeat无法根据日志类型判断,所以还需要添加logstash对收集到的日志类型进行判断,写入到哪个topic kafka { bootstrap_servers => "192.168.64.110:9002" topic_id => "kafka-system-log" } } if [fields][type] == "nginx-access-log" { # 因为filebeat无法根据日志类型判断,所以还需要添加logstash对收集到的日志类型进行判断,写入到哪个topic kafka { bootstrap_servers => "192.168.64.110:9002" topic_id => "kafka-nginx-access-log" codec => "json" } } }
logstash读取kafka数据,并根据类型写入es集群
input { kafka { bootstrap_servers => "192.168.64.110:9002,192.168.64.111:9002" # kafka集群地址 topic_id => "kafka-system-log" codec => "json" } kafka { bootstrap_servers => "192.168.64.110:9002" topic_id => "kafka-nginx-access-log" codec => "json" } output { if [fields][type] == "system-log" { elasticsearch { host => ["192.168.64.110:9200"] # 可以指定es 集群的VIP index => "kafka-system-log-%{+YYYY.MM.dd}" } } if [fields][type] == "nginx-access-log" { elasticsearch { host => ["192.168.64.110:9200"] # 可以指定es 集群的VIP index => "kafka-nginx-access-log-%{+YYYY.MM.dd}" } } }
本文来自博客园,作者:不会跳舞的胖子,转载请注明原文链接:https://www.cnblogs.com/rtnb/p/16276365.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号