
ELK—JAVA日志合并收集
使用 codec 的 multiline 插件实现多行匹配,这是一个可以将多行进行合并的插件,而且可以使用 what 指定将匹配到的行与前面的行合并还是和后面的行合并。
https://www.elastic.co/guide/en/logstash/current/plugins-codecs-multiline.html
一、标准输入输出测试
[root@linux-host1 ~]# cat /etc/logstash/conf.d/java-to-es.conf input { stdin { codec => multiline { pattern => "^\[" #当遇到[开头的行时候将多行进行合并 negate => true #true 为匹配成功进行操作,false 为不成功进行操作 what => "previous" #与以前的行合并,如果是下面的行合并就是 next } } } output { stdout { codec => rubydebug } }
测试可以正常启动
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/java.conf
测试标准 输入和标准输出
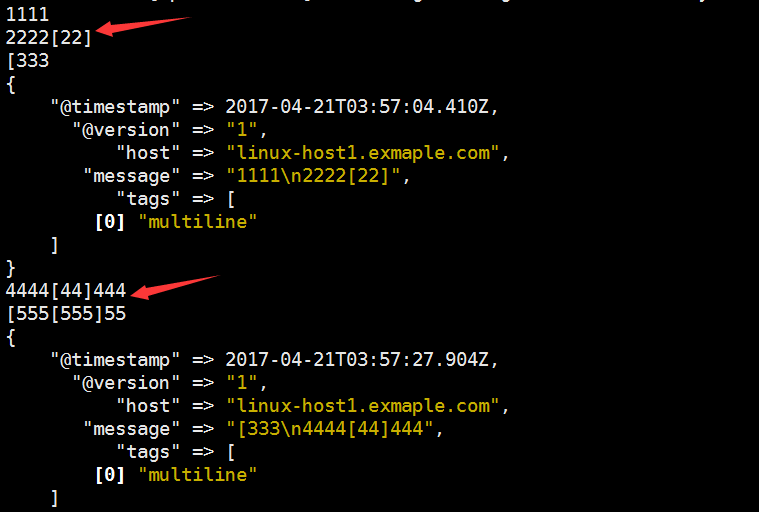
二、将输出改为 elasticsearch
input { file { path => "/var/logs/tomcat.log" # 可以写tomcat日志路径 type => "javalog" start_position => "beginning" codec => multiline { # 使用multiline 插件 pattern => "^\[" # 合并 [ 之前的日志,不是以[ 开头的日志都进行合并,支持正则表达式,根据业务格式定义 negate => true # 匹配成功执行,还是匹配不成功执行 what => "previous" # 合并之前的日志 } } } output { if [type] == "javalog" { elasticsearch { hosts => ["172.31.2.102:9200"] # 集群地址,如果配置了集群,这里最好指定VIP实现容灾 index => "java-error-log-2.105-%{+YYYY.MM.dd}" # 按天创建索引,周为: ww; } }
sincedb
[root@linux-host1~]# cat /var/lib/logstash/plugins/inputs/file/.sincedb_1ced15cfacdbb0380466be84d620085a 134219868 0 2064 29465 #记录了收集文件的 inode 信息
[root@linux-host1 ~]# ll -li /elk/logs/ELK-Cluster.log 134219868 -rw-r--r-- 1 elasticsearch elasticsearch 29465 Apr 21 14:33 /elk/logs/ELK- Cluster.log
本文来自博客园,作者:不会跳舞的胖子,转载请注明原文链接:https://www.cnblogs.com/rtnb/p/16275716.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号