K8S-kubernetes结合alertmanager实现报警通知及基于haproxy_exporter监控haproxy
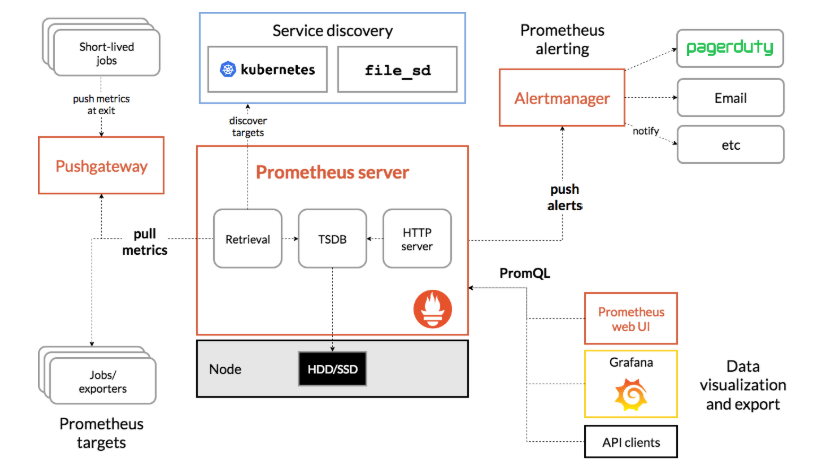
prometheus系统架构图
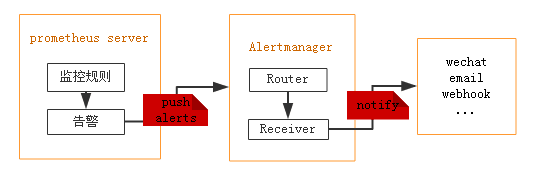
prometheus触发一条告警的过程:
prometheus--->触发阈值--->超出持续时间--->alertmanager--->分组/抑制/静默--->媒体类型--->邮件/钉钉/微信等。
分组(group): 将类似性质的警报合并为单个通知。
静默(silences): 是一种简单的特定时间静音的机制,例如:服务器要升级维护可以先设置这个时间段告警静默。
抑制(inhibition): 当警报发出后,停止重复发送由此警报引发的其他警报即合并一个故障引起的多个报警事件,可以消除冗余告警。
下载并报警组件alertmanager
# pwd /usr/local/src # tar xvf alertmanager-0.18.0.linux-amd64.tar.gz # ln -sv /usr/local/src/alertmanager-0.18.0.linux-amd64 /usr/local/alertmanager # cd /usr/local/alertmanager
配置alertmanager
官方配置文档:https://prometheus.io/docs/alerting/configuration/
# pwd /usr/local/alertmanager # cat alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'smtp.qq.com:465' smtp_from: 'xx@qq.com' smtp_auth_username: 'xxx@qq.com' smtp_auth_password: 'xxx' //授权码 smtp_hello: '@qq.com' smtp_require_tls: false
route: #route用来设置报警的分发策略 group_by: ['alertname'] #采用哪个标签来作为分组依据 group_wait: 10s #组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出 group_interval: 10s #两组告警的间隔时间 repeat_interval: 2m #重复告警的间隔时间,减少相同邮件的发送频率 receiver: 'web.hook' #设置接收人
receivers: - name: 'web.hook' #webhook_configs: #- url: 'http://127.0.0.1:5001/' email_configs: - to: 'xxx@qq.com' inhibit_rules: #禁止的规则 - source_match: #源匹配级别 severity: 'critical' # 紧急告警 target_match: severity: 'warning' # 禁止发送警告日志 equal: ['alertname', 'dev', 'instance'] # 分组匹配
启动alertmanager服务
二进制启动
./alertmanager --config.file=./alertmanager.yml
启动脚本
[Unit] Description=Prometheus Server Documentation=https://prometheus.io/docs/introduction/overview/ After=network.target [Service] Restart=on-failure ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml [Install] WantedBy=multi-user.target
验证alertmanager的9093端口已经监听
lsof -i:9093 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME alertmana 127083 root 6u IPv6 8581566 0t0 TCP *:9093 (LISTEN)
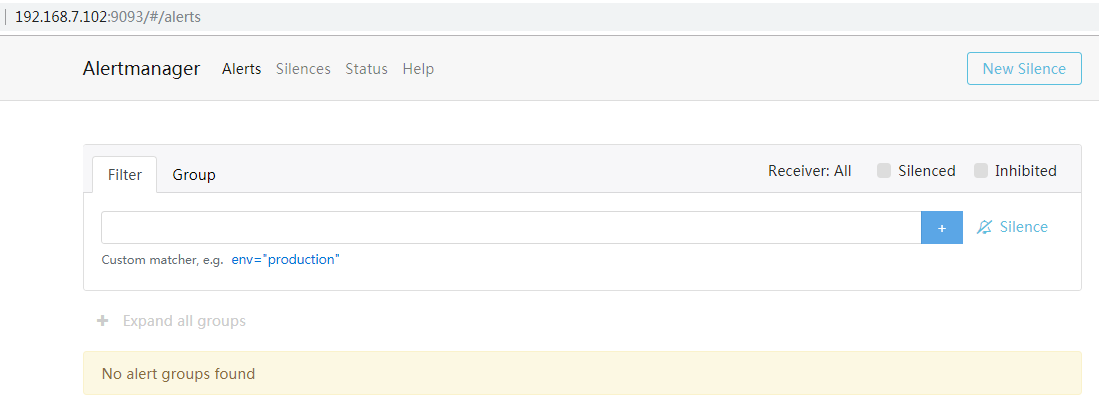
alertmanager dashboard截图
配置prometheus报警规则
# cd /usr/local/prometheus # vim prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - localhost:9093 # 指定alertmanager告警发送服务器地址 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "/usr/local/prometheus/linux39_rules.yml" # 指定报警规则文件 # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus-local" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: 'promethues-k8s-node' static_configs: - targets: ['192.168.64.114:9100','192.168.64.113:9100'] - job_name: 'promethues-k8s-master' static_configs: - targets: ['192.168.64.110:9100'] - job_name: 'promethues-k8s-containers' static_configs: - targets: ['192.168.64.110:8080','192.168.64.113:8080','192.168.64.114:8080']
创建报警规则文件,/usr/local/prometheus/rule-linux36.yml
# pwd /usr/local/prometheus groups: - name: linux37_pod.rules rules: - alert: Pod_all_cpu_usage # cpu监控 expr: (sum by(name)(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 10 # 测试设置为10%,不然触发不了告警 for: 5m # labels: severity: critical service: pods annotations: description: 容器 {{ $labels.name }} CPU 资源利用率大于 75% , (current value is {{$value }}) summary: Dev CPU 负载告警 - alert: Pod_all_memory_usage # 内存监控 expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 1024*10^3*2 # 单位转换 for: 10m labels: severity: critical annotations: description: 容器 {{ $labels.name }} Memory 资源利用率大于 2G , (current value is {{$value }}) summary: Dev Memory 负载告警 - alert: Pod_all_network_receive_usage # 网络监控 expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 1024*1024*50 for: 10m labels: severity: critical annotations: description: 容器 {{ $labels.name }} network_receive 资源利用率大于 50M , (currentvalue is {{ $value }})
报警规则验证
# pwd /usr/local/prometheus #验证报警规则设置: # ./promtool check rules rule-linux36.yml #监测rule规则文件是否正确 Checking rule-linux36.yml SUCCESS: 3 rules found
重启prometheus
systemctl restart prometheus
验证报警规则匹配
# pwd /usr/local/alertmanager # ./amtool alert --alertmanager.url=http://192.168.7.102:9093 Alertname Starts At Summary Pod_all_cpu_usage 2019-08-07 07:39:04 CST Dev CPU 负载告警
prometheus首页状态
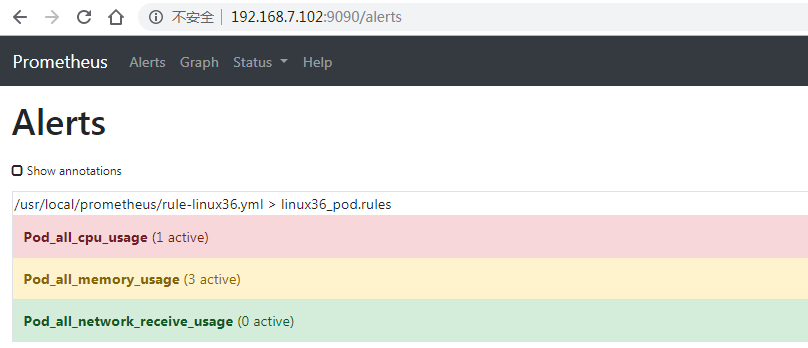
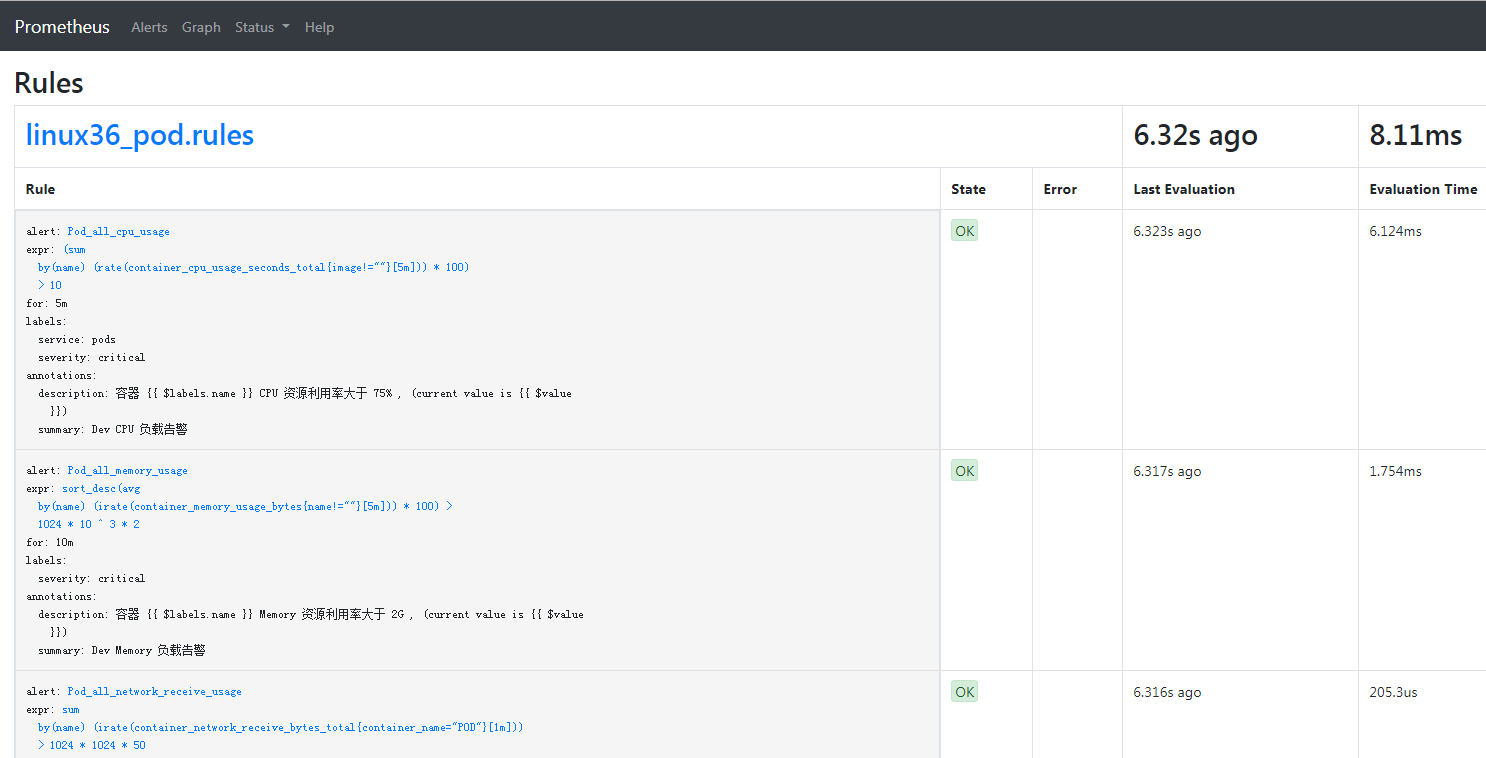
prometheus web界面验证报警规则
status-rules
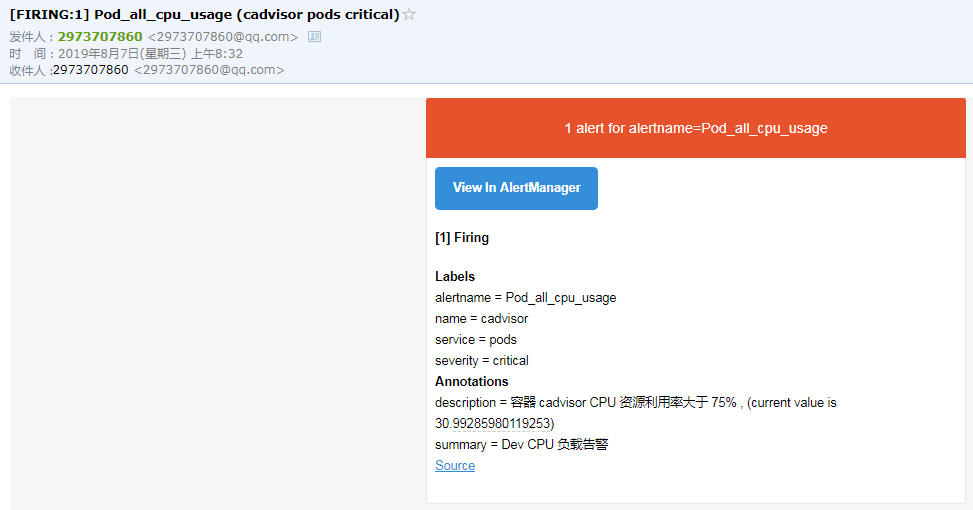
验证收到的报警邮件
prometheus监控haproxy
部署haproxy_exporter
# pwd /usr/local/src # tar xvf haproxy_exporter-0.9.0.linux-amd64.tar.gz # ln -sv /usr/local/src/haproxy_exporter-0.9.0.linux-amd64 /usr/local/haproxy_exporter # cd /usr/local/haproxy_exporter
# ./haproxy_exporter --haproxy.scrape-uri=unix:/run/haproxy/admin.sock //指定haproxy sock文件监控 # ./haproxy_exporter --haproxy.scrape-uri="http://haadmin:q1w2e3r4ys@127.0.0.1:9999/haproxy-status;csv" # 指定状态页面监控
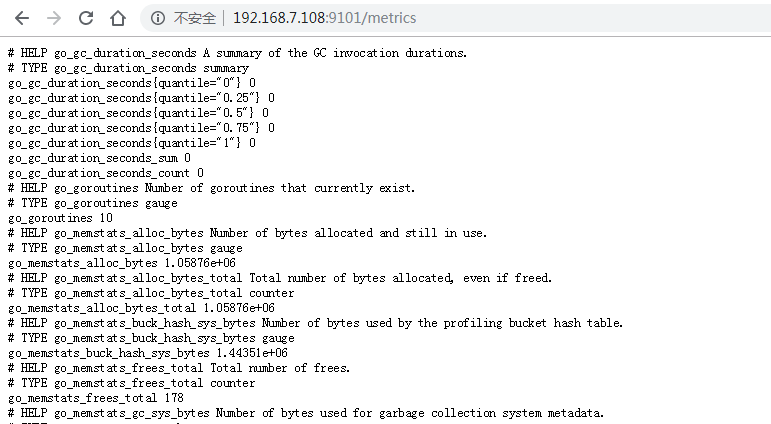
验证web界面数据
prometheus server端添加haproxy数据采集
# vim /usr/local/prometheus/prometheus.yml # cd /usr/local/prometheus/ # grep -v "#" prometheus.yml | grep -v "^$" global: alerting: alertmanagers: - static_configs: - targets: ["192.168.7.102:9093"] rule_files: - "/usr/local/prometheus/rule-linux36.yml" scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'promethues-node' static_configs: - targets: ['192.168.7.110:9100','192.168.7.111:9100'] - job_name: 'prometheus-containers' static_configs: - targets: ["192.168.7.110:8080","192.168.7.111:8080"]
- job_name: 'prometheus-haproxy' # haproxy static_configs: - targets: ["192.168.7.108:9101"]
重启prometheus
systemctl restart prometheus
grafana添加模板
367 2428

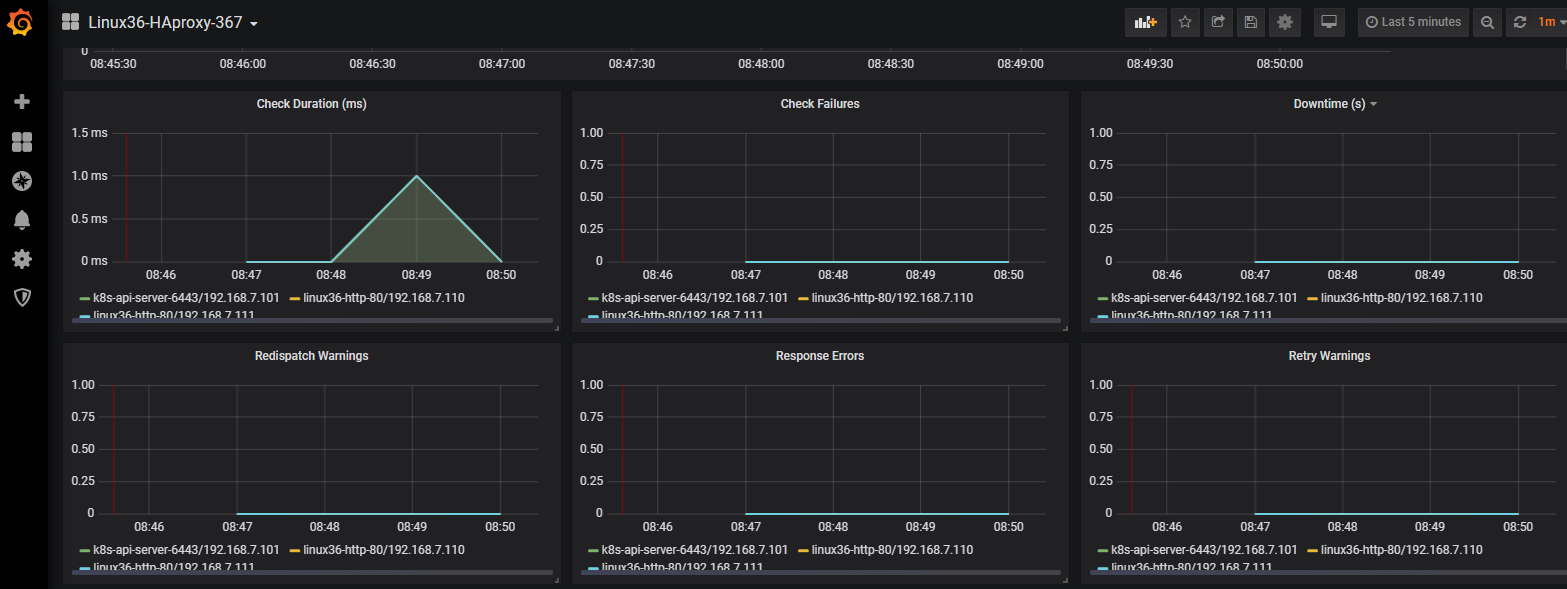
验证haproxy监控数据
本文来自博客园,作者:不会跳舞的胖子,转载请注明原文链接:https://www.cnblogs.com/rtnb/p/16218871.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号