
K8S-Promethues+Grafana集群性能监控平台搭建
容器监控与报警:
容器监控的实现方对比虚拟机或者物理机来说比大的区别,比如容器在k8s环境中可以任意横向扩容与缩容,那么就需要监控服务能够自动对新创建的容器进行监控,当容器删除后又能够及时的从监控服务中删除,而传统的zabbix的监控方式需要在每一个容器中安装启动agent,并且在容器自动发现注册及模板关联方面并没有比较好的实现方式。
6.1:Prometheus:
k8s的早期版本基于组件heapster实现对pod和node节点的监控功能,但是从k8s 1.8版本开始使用metrics API的方式监控,并在1.11版本 正式将heapster替换,后期的k8s监控主要是通过metrics Server提供核心监控指标,比如Node节点的CPU和内存使用率,其他的监控交由另外一个组件Prometheus 完成。
6.1.1:prometheus简介:
官方文档:https://prometheus.io/docs/
github地址:https://github.com/prometheus
Prometheus是基于go语言开发的一套开源的监控、报警和时间序列数据库的组合,是由SoundCloud公司开发的开源监控系统,Prometheus是CNCF(Cloud Native Computing Foundation,云原生计算基金会)继kubernetes 之后毕业的第二个项目,prometheus在容器和微服务领域中得到了广泛的应用,其特点主要如下:
使用key-value的多维度格式保存数据
数据不使用MySQL这样的传统数据库,而是使用时序数据库,目前是使用的TSDB
支持第三方dashboard实现更高的图形界面,如grafana(Grafana 2.5.0版本及以上)
功能组件化
不需要依赖存储,数据可以本地保存也可以远程保存
服务自动化发现
强大的数据查询语句功(PromQL,Prometheus Query Language)
Promethues主要包含以下特点:
1. 使用指标名称及键值对标识的多维度数据模型。
2. 采用灵活的查询语句 Prom QL.
3. 不依赖分布式存储,为自治的单节点服务。
4. 使用http完成对监控数据的拉取。
5. 支持通过网关推送时序数据。
6. 支持多种图形和Dashboard 的展示,例如Grafana。
Promethues生态系统由各种组件组成,用于功能的扩充。
1. Promethues Server: 负责监控数据的采集和时序数据存储,并提供数据查询能力。
2. 客户端SDK:对接Promethues 的开发工具包。
3. Patn Gateway: 推送数据的网关组件。
4. 第三方Exporter:各种外部指标收集系统,其数据可以被Promethues采集。
5. AlertManager:告警管理器。
6. 其他辅助支持工具。
Promethues 的核心组件Promethues Server 的主要功能包括:
1. 从Promethues Master中获取需要监控的资源或服务信息;
2. 从各种exporter中抓取指标数据,然后将指标数据存储在时序数据库(TSDB);
3. 向其他系统提供HTTP API进行查询;
4. 提供基于PromQL语言的数据查询;
5. 可以将告警数据推送给AlertManager等等。
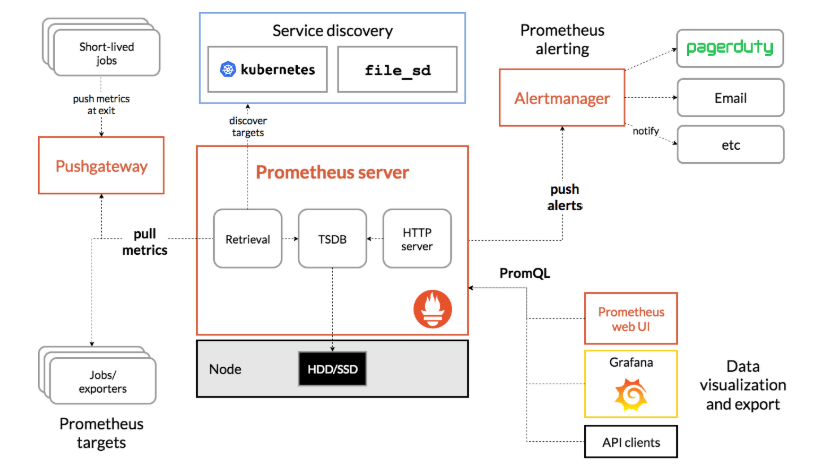
prometheus系统架构图
prometheus server:主服务,接受外部http请求,收集、存储与查询数据等
prometheus targets: 静态收集的目标服务数据
service discovery:动态发现服务
prometheus alerting:报警通知
pushgateway:数据收集代理服务器(类似于zabbix proxy)
data visualization and export: 数据可视化与数据导出(访问客户端)
prometheus 安装方式:
https://prometheus.io/download/ #官方二进制下载及安装,prometheus server的监听端口为9090
https://prometheus.io/docs/prometheus/latest/installation/ #docker镜像直接启动
https://github.com/coreos/kube-prometheus #operator部署
二进制方式安装:
grafana下载地址:https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm/
Promethues :https://mirrors.tuna.tsinghua.edu.cn/github-release/prometheus/prometheus/LatestRelease/
创建prometheus启动脚本
[Unit] Description=Prometheus Server Documentation=https://prometheus.io/docs/introduction/overview/ After=network.target
[Service] Restart=on-failure WorkingDirectory=/usr/local/prometheus/ ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml
[Install] WantedBy=multi-user.target
prometheus.yml
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus-local" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: 'promethues-k8s-node' static_configs: - targets: ['192.168.64.114:9100','192.168.64.113:9100'] - job_name: 'promethues-k8s-master' static_configs: - targets: ['192.168.64.110:9100']
参数解释:
Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "first_rules.yml" - "second_rules.yml" ``` 这个配置是用于加载和周期性地评估规则的。具体来说,它指定了一个或多个规则文件,在启动时加载这些规则文件中的规则,并按照全局配置中指定的 evaluation_interval 周期性地重新评估这些规则。 在这个配置中,规则文件的路径被注释掉了,也就是说,在默认情况下不会加载任何规则文件。如果要加载规则文件,需要将注释去掉,并将路径指定为相应规则文件的路径。 需要注意的是,这个配置只是一个示例,具体实现取决于特定应用程序或系统的需求。 示例: 假设我们有一个监控系统,需要定期检查服务器的 CPU 使用率和磁盘空间使用情况,并在达到阈值时发出警报。我们可以将规则定义在两个不同的规则文件中,分别是 cpu_usage_rules.yml 和 disk_space_rules.yml,每个文件中包含了对应监控项的规则定义。具体内容如下: cpu_usage_rules.yml 文件内容: - alert: HighCpuUsage expr: node_cpu_seconds_total{mode="idle"} < 50 for: 5m labels: severity: warning alert:告警规则的名称,用于标识该规则,必须是唯一的。 expr:告警规则的表达式,用于定义触发告警的条件。表达式由 Prometheus 的查询语言 PromQL 组成。在这个例子中,表达式 node_cpu_seconds_total{mode="idle"} < 50 表示当空闲 CPU 时间低于 50 秒时触发告警。 for:告警规则的持续时间,即在满足触发条件后持续多长时间才触发告警。在这个例子中,for: 5m 表示当满足条件持续 5 分钟时触发告警。 labels:告警规则的标签,用于为告警规则添加元数据。在这个例子中,severity: warning 表示告警的严重程度为警告级别。 disk_space_rules.yml 文件内容: - alert: LowDiskSpace expr: (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 < 20 for: 10m labels: severity: critical 然后,在监控系统的配置文件中,我们可以将这两个规则文件的路径指定为 rule_files 字段的值,同时设置 evaluation_interval 为 1m,表示每隔 1 分钟重新评估一次规则: global: evaluation_interval: 1m rule_files: - "cpu_usage_rules.yml" - "disk_space_rules.yml" 这样,监控系统会在启动时加载这两个规则文件中的规则,并每隔 1 分钟重新评估这些规则,如果某个规则的条件满足,就会触发相应的警报。 ```
部署node exporter
# pwd /usr/local/src # tar xvf node_exporter-0.18.1.linux-amd64.tar.gz # ln -sv /usr/local/src/node_exporter-0.18.1.linux-amd64 /usr/local/node_exporter # cd /usr/local/node_exporter
创建node exporter启动脚本
[Unit] Description=Prometheus Node Exporter After=network.target [Service] ExecStart=/usr/local/node_exporter/node_exporter [Install] WantedBy=multi-user.target
启动node exporter服务
# systemctl daemon-reload # systemctl restart node-exporter # systemctl enable node-exporter
访问node exporter web界面
prometheus采集node 指标数据
- job_name: 'promethues-k8s-node' static_configs: - targets: ['192.168.64.114:9100','192.168.64.113:9100'] - job_name: 'promethues-k8s-master' static_configs: - targets: ['192.168.64.110:9100']
重启prometheus服务
systemctl restart prometheus
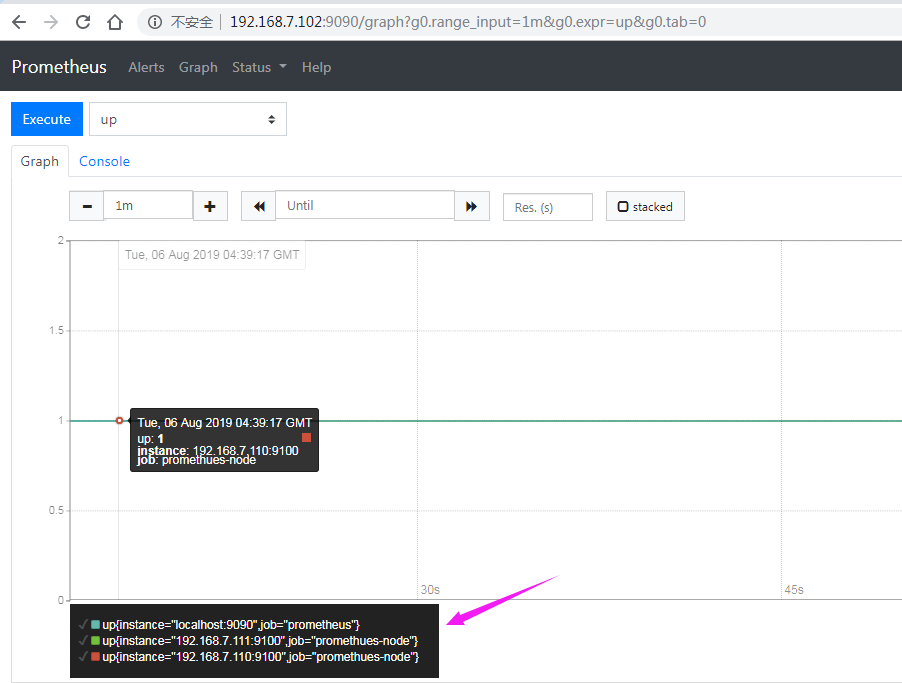
prometheus验证node节点状态
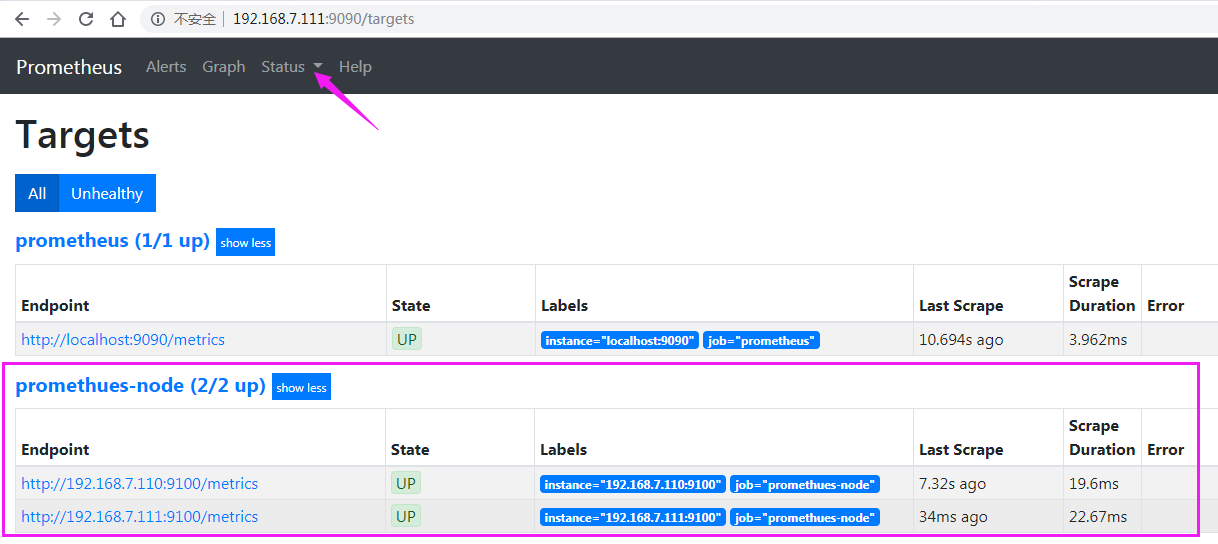
prometheus验证node节点监控数据
安装Grafana
镜像:https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm/
]# yum -y install grafana-6.7.2-1.x86_64.rpm
启动
]# systemctl enable grafana-server.service && systemctl start grafana-server.service
查看端口
]# netstat -ntpl Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 659/rpcbind tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 1276/dnsmasq tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1088/sshd tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 1078/cupsd tcp 0 0 127.0.0.1:43298 0.0.0.0:* LISTEN 1096/containerd tcp6 0 0 :::9100 :::* LISTEN 117233/node_exporte tcp6 0 0 :::111 :::* LISTEN 659/rpcbind tcp6 0 0 :::22 :::* LISTEN 1088/sshd tcp6 0 0 :::3000 :::* LISTEN 118052/grafana-serv tcp6 0 0 :::9090 :::* LISTEN 117670/prometheus
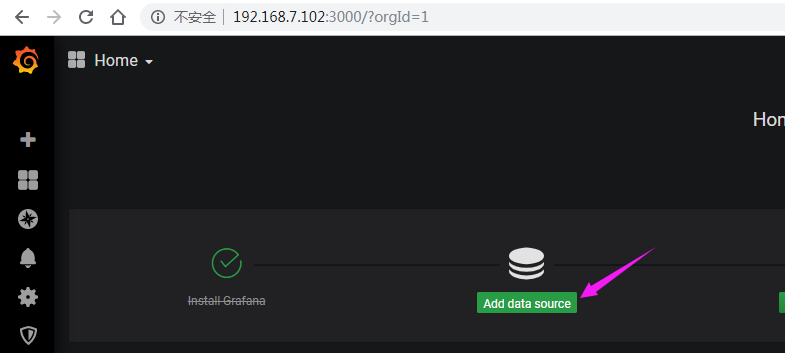
访问grafana web界面

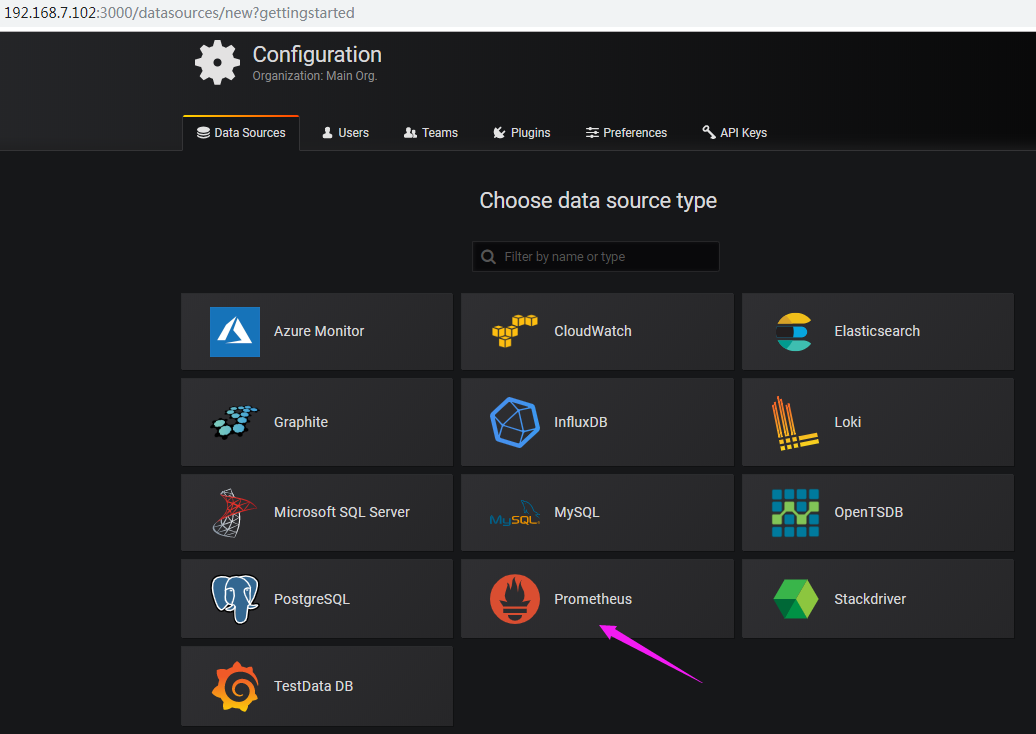
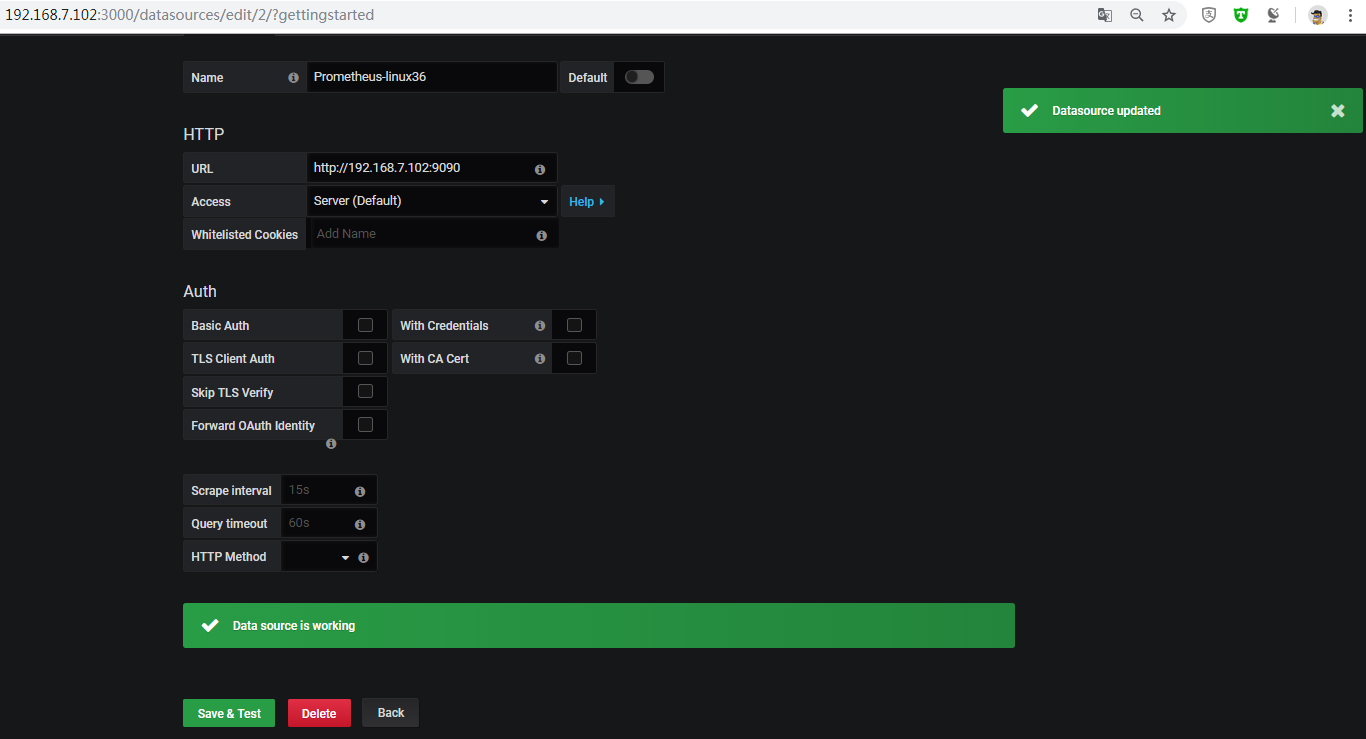
添加prometheus数据源
import模板
模板下载地址
模板可以在左侧栏匹配或搜索相关名称
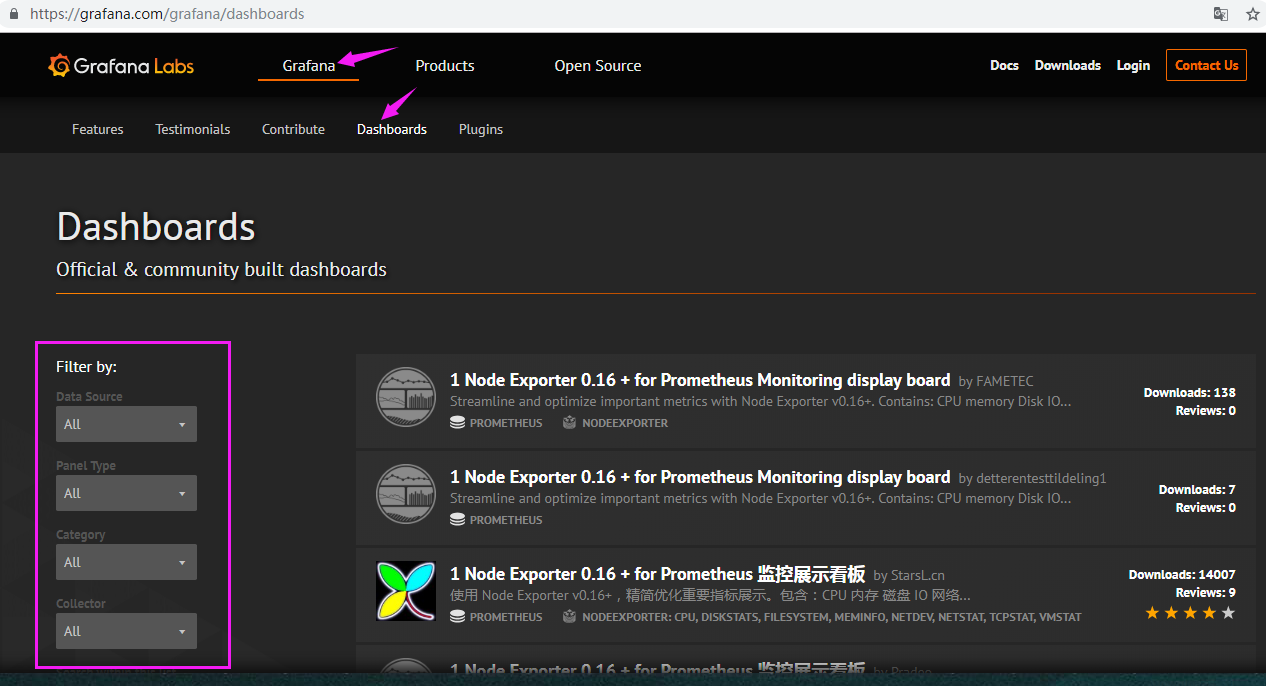
点击目标模板
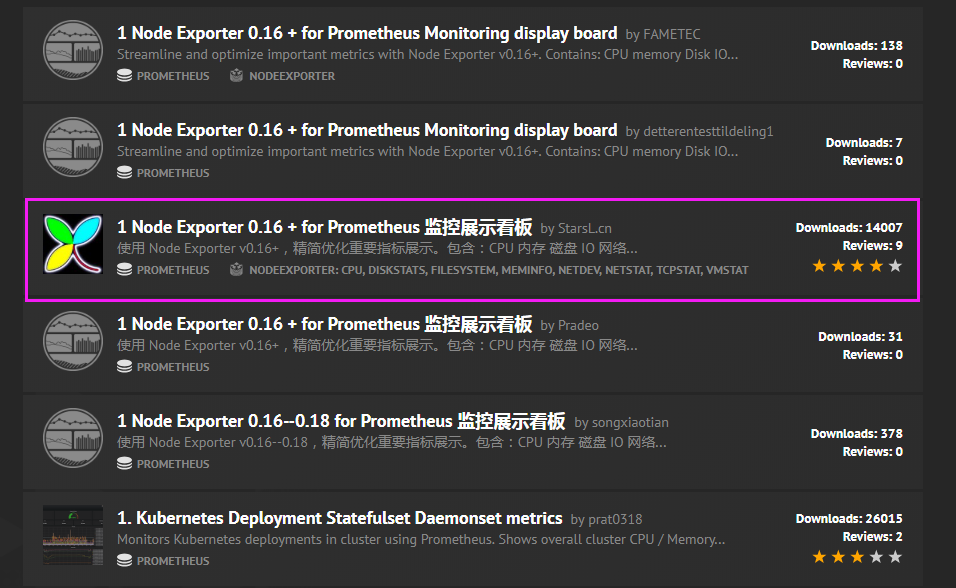
下载模板
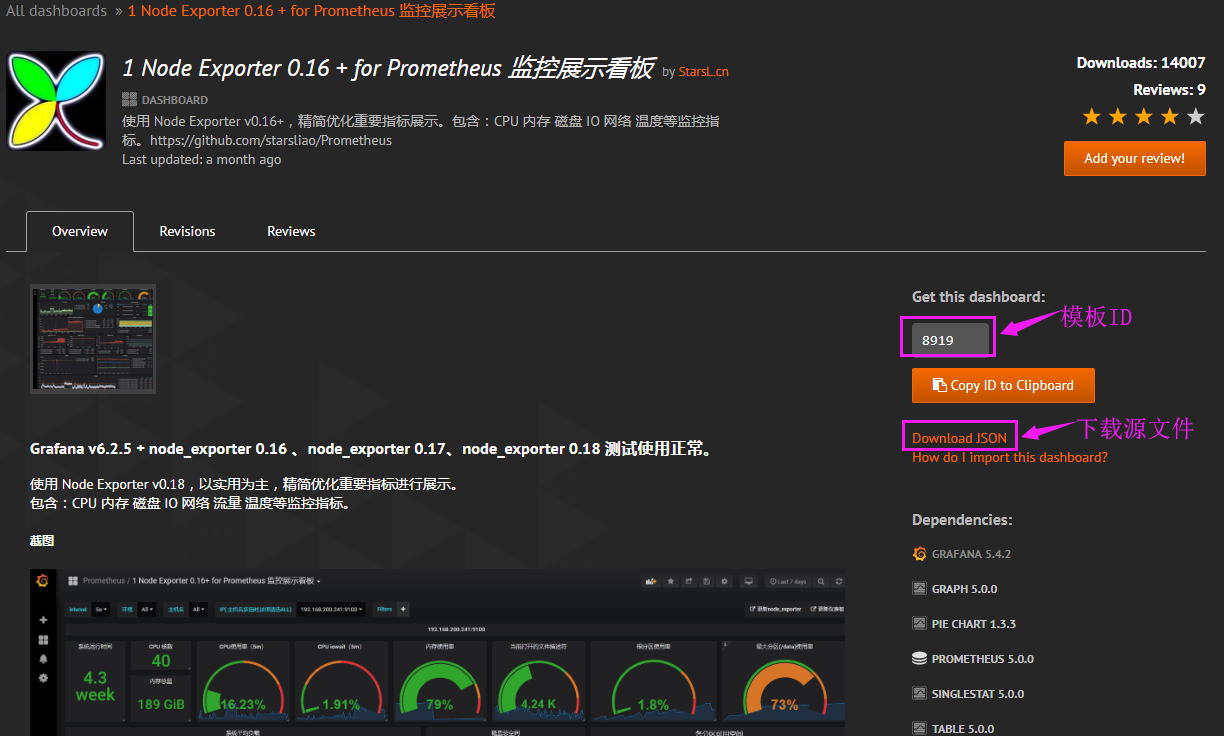
通过模板ID导入
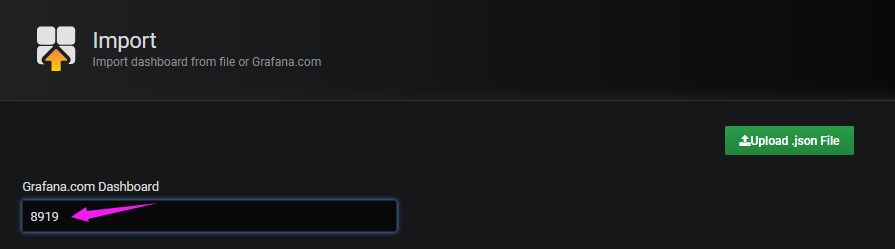
确认模板信息
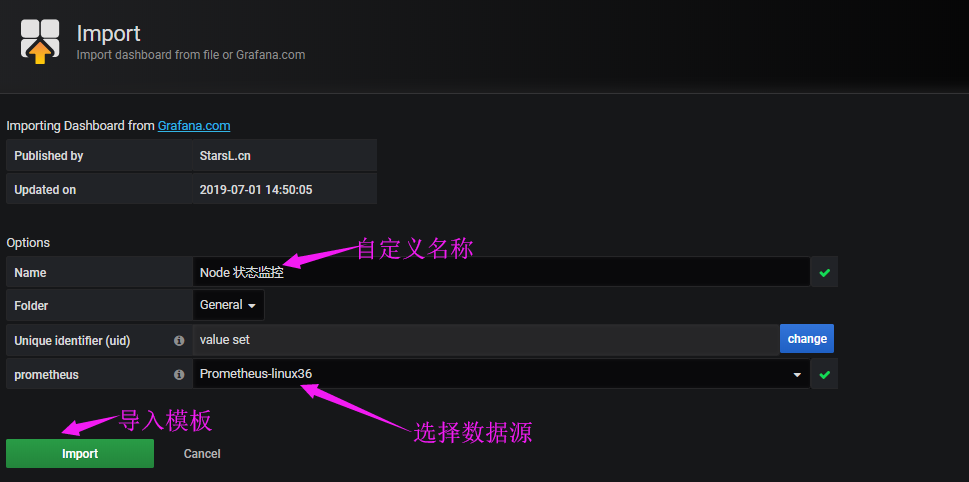
在线安装
列出插件列表
]# grafana-cli plugins --help NAME: Grafana CLI plugins - Manage plugins for grafana USAGE: Grafana CLI plugins command [command options] [arguments...] COMMANDS: install install <plugin id> <plugin version (optional)> list-remote list remote available plugins list-versions list-versions <plugin id> update, upgrade update <plugin id> update-all, upgrade-all update all your installed plugins ls list all installed plugins uninstall, remove uninstall <plugin id> help, h Shows a list of commands or help for one command OPTIONS: --help, -h show help (default: false) --version, -v print the version (default: false) [root@master-2 prometheus]# grafana-cli plugins list-remote id: abhisant-druid-datasource version: 0.0.6 id: aceiot-svg-panel version: 0.0.8 id: ae3e-plotly-panel version: 0.2.1 id: agenty-flowcharting-panel version: 0.9.1 id: aidanmountford-html-panel version: 0.0.2 id: akumuli-datasource version: 1.3.12 id: alexanderzobnin-zabbix-app version: 4.0.1
插件安装
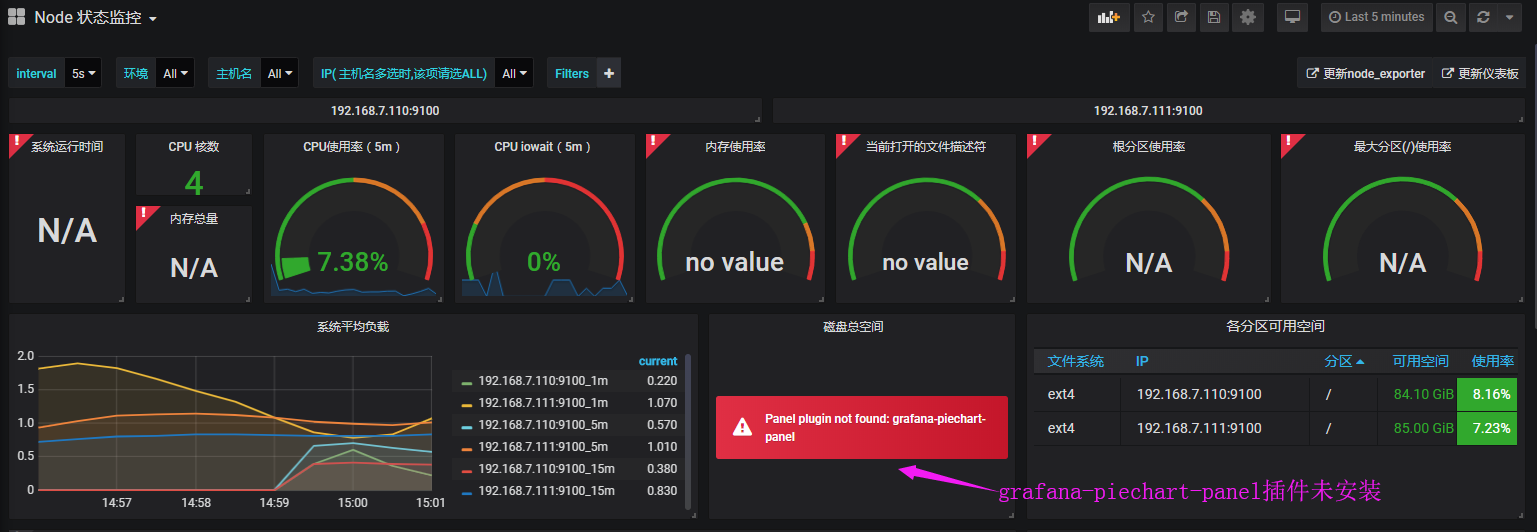
饼图插件未安装,需要提前安装
https://grafana.com/grafana/plugins/grafana-piechart-panel
在线安装: # grafana-cli plugins install grafana-piechart-panel 离线安装: # pwd /var/lib/grafana/plugins # unzip grafana-piechart-panel-v1.3.8-0-g4f34110.zip # mv grafana-piechart-panel-4f34110 grafana-piechart-panel # systemctl restart grafana-server
查看插件目录
]# ll /var/lib/grafana/plugins/grafana-piechart-panel/ total 252 -rw-r--r-- 1 root root 1005 May 3 16:01 dark.js -rw-r--r-- 1 root root 4635 May 3 16:01 dark.js.map -rw-r--r-- 1 root root 5191 May 3 16:01 editor.html drwxr-xr-x 2 root root 284 May 3 16:01 img -rw-r--r-- 1 root root 1074 May 3 16:01 LICENSE -rw-r--r-- 1 root root 1004 May 3 16:01 light.js -rw-r--r-- 1 root root 4635 May 3 16:01 light.js.map -rw-r--r-- 1 root root 2855 May 3 16:01 MANIFEST.txt -rw-r--r-- 1 root root 277 May 3 16:01 module.html -rw-r--r-- 1 root root 42486 May 3 16:01 module.js -rw-r--r-- 1 root root 884 May 3 16:01 module.js.LICENSE.txt -rw-r--r-- 1 root root 152610 May 3 16:01 module.js.map -rw-r--r-- 1 root root 1645 May 3 16:01 plugin.json -rw-r--r-- 1 root root 2240 May 3 16:01 README.md drwxr-xr-x 2 root root 39 May 3 16:01 styles
未安装饼图插件:
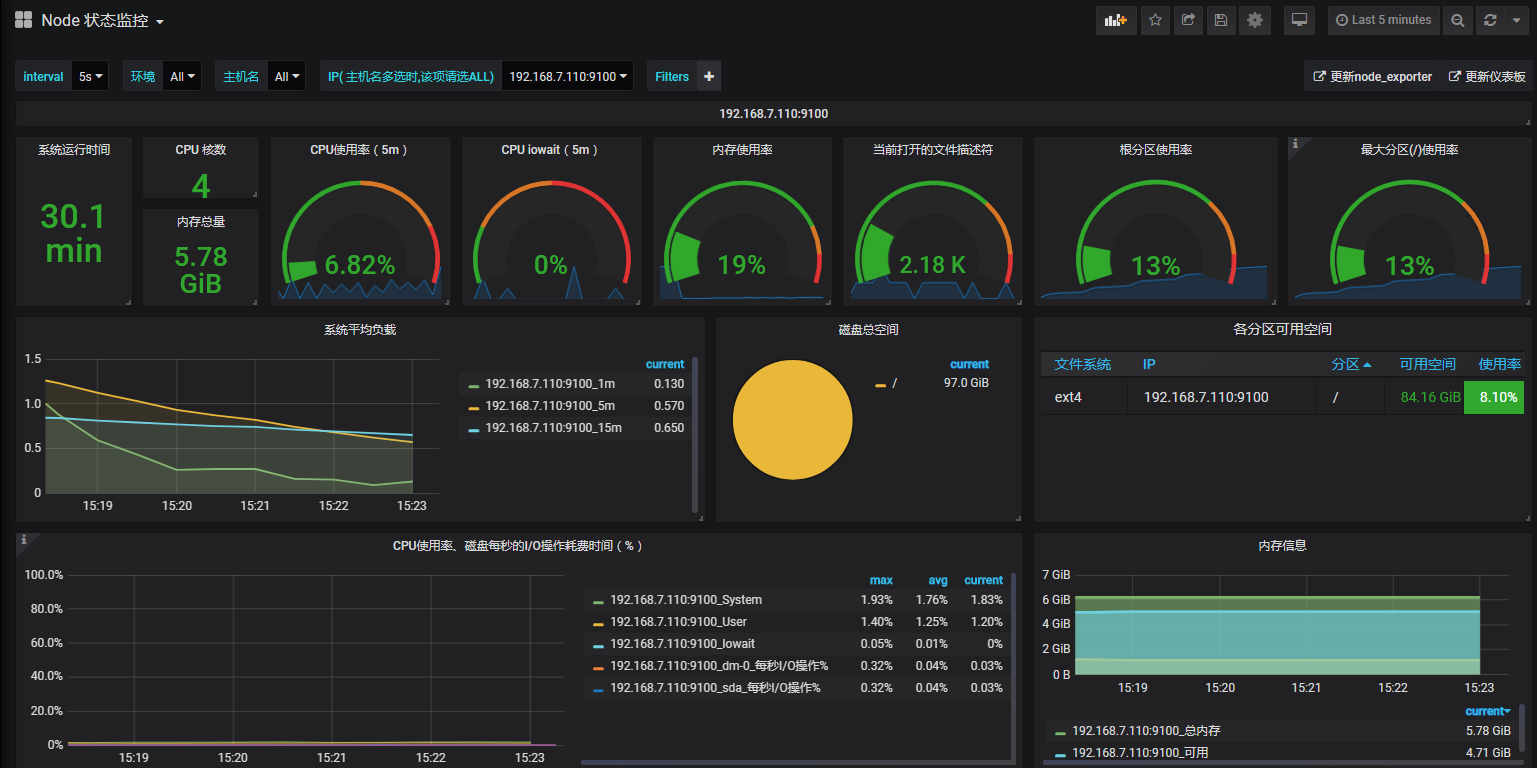
已安装饼图插件
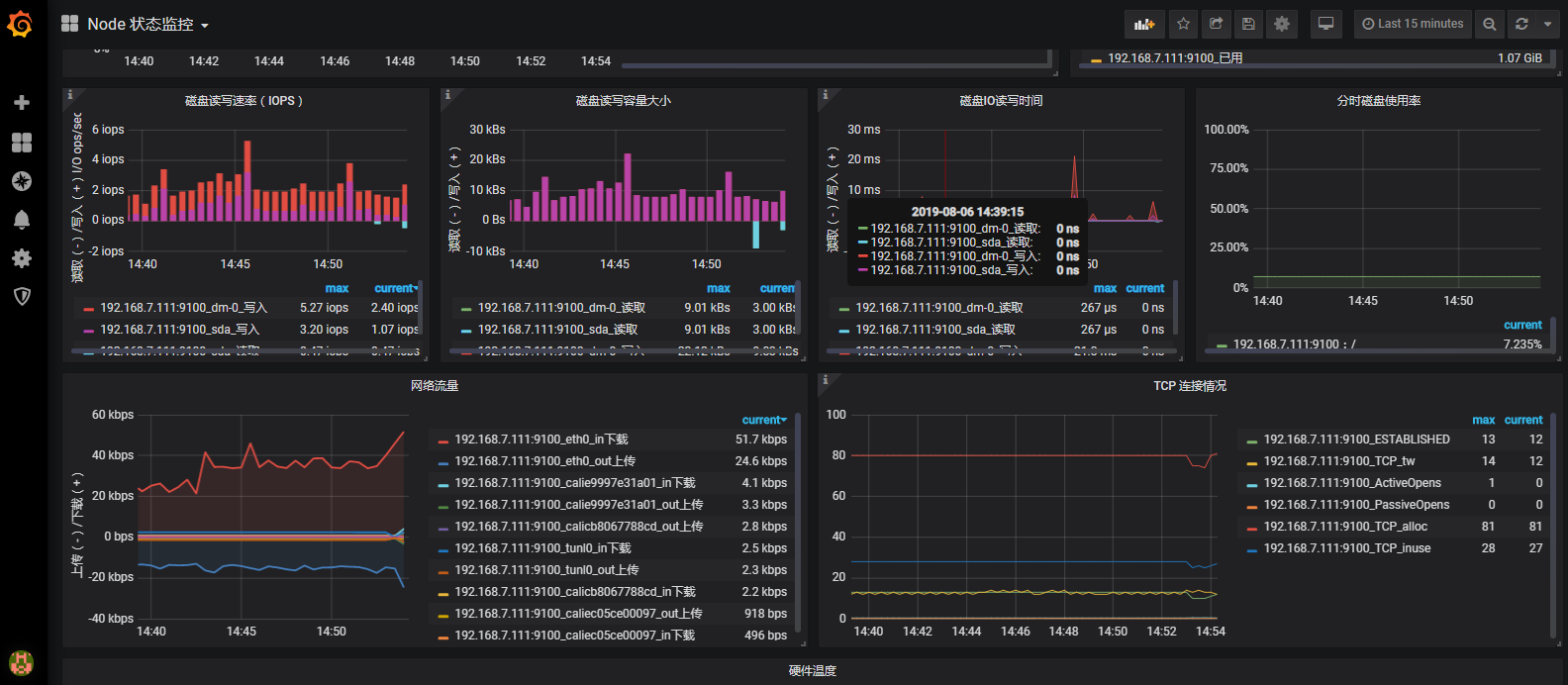
其他监控项图形
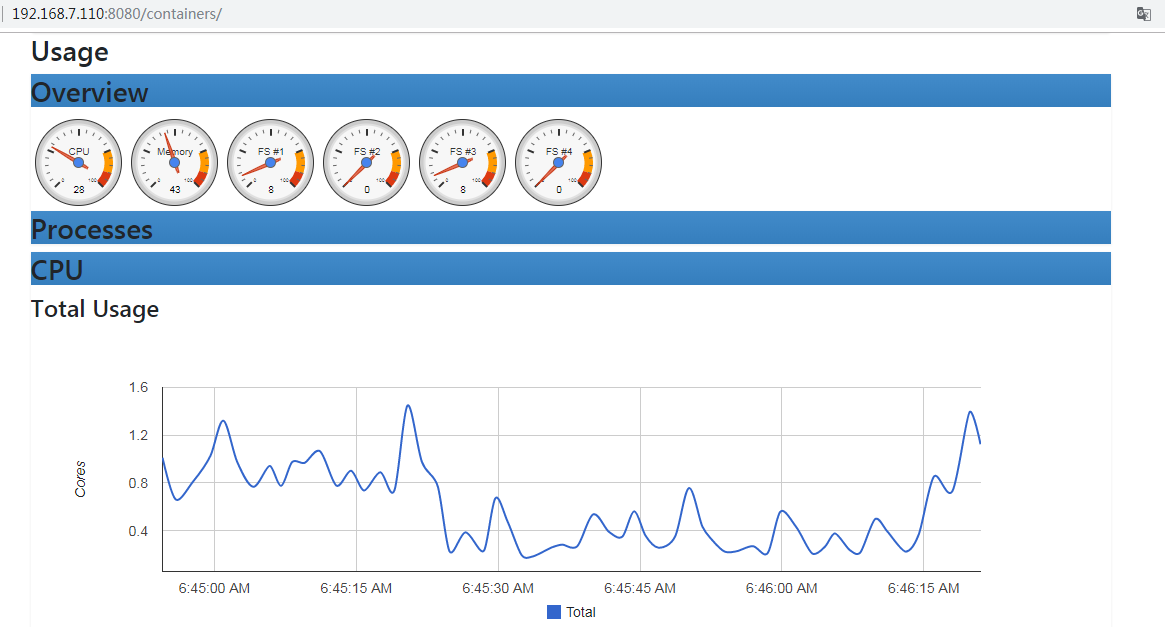
监控pod资源:
cadvisor由谷歌开源,cadvisor不仅可以搜集一台机器上所有运行的容器信息,还提供基础查询界面和http接口,方便其他组件如Prometheus进行数据抓取,cAdvisor可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
k8s 1.12之前cadvisor集成在node节点的上kubelet服务中,从1.12版本开始分离为两个组件,因此需要在node节点单独部署cadvisor。
官网:https://github.com/google/cadvisor
cadvisor镜像准备
# docker load -i cadvisor_v0.33.0.tar.gz # docker tag gcr.io/google-containers/cadvisor:v0.33.0 harbor.magedu.net/baseimages/cadvisor:v0.33.0 # docker push harbor.magedu.net/baseimages/cadvisor:v0.33.0
启动cadvisor容器:
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor gcr.io/google_containers/cadvisor:v0.36.0
查看容器
]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d45b35118651 gcr.io/google_containers/cadvisor:v0.36.0 "/usr/bin/cadvisor -…" 5 seconds ago Up 3 seconds 0.0.0.0:8080->8080/tcp cadvisor
查看端口
]# netstat -ntpl Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp6 0 0 :::8080 :::* LISTEN 118875/docker-proxy
访问
prometheus采集cadvisor数据
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus-local" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: 'promethues-k8s-node' static_configs: - targets: ['192.168.64.114:9100','192.168.64.113:9100'] - job_name: 'promethues-k8s-master' static_configs: - targets: ['192.168.64.110:9100'] - job_name: 'promethues-k8s-containers' static_configs: - targets: ['192.168.64.110:8080','192.168.64.113:8080','192.168.64.114:8080']
重启
]# systemctl restart prometheus.service
验证prometheus数据
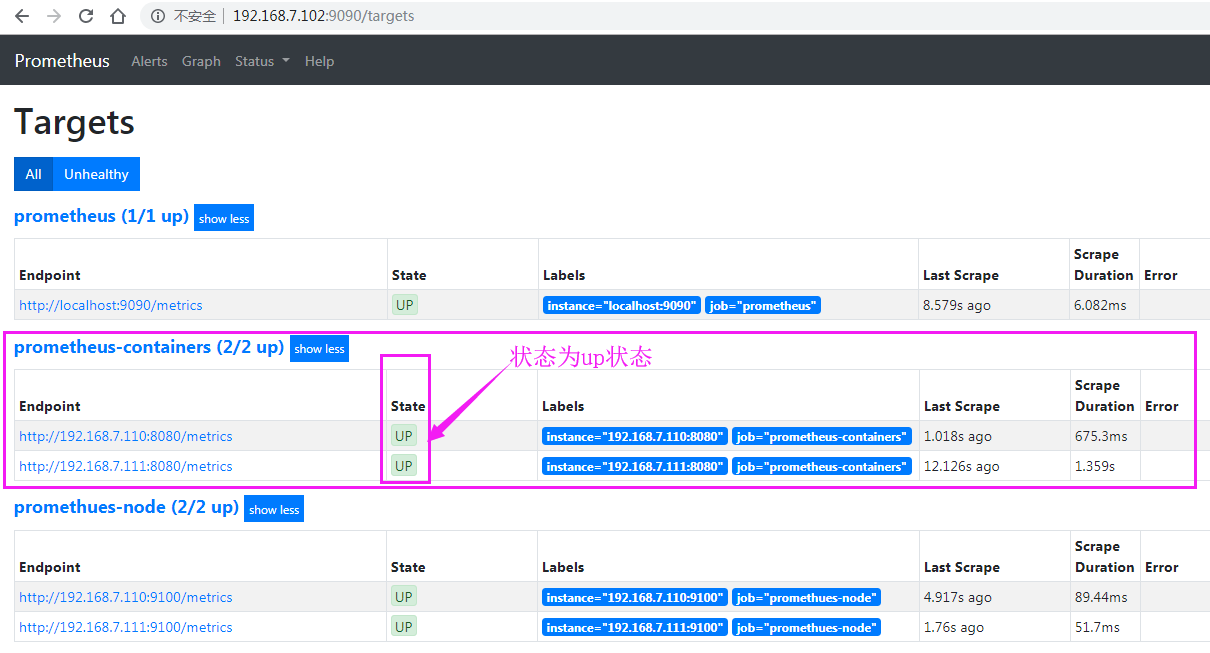
grafana添加pod监控模板
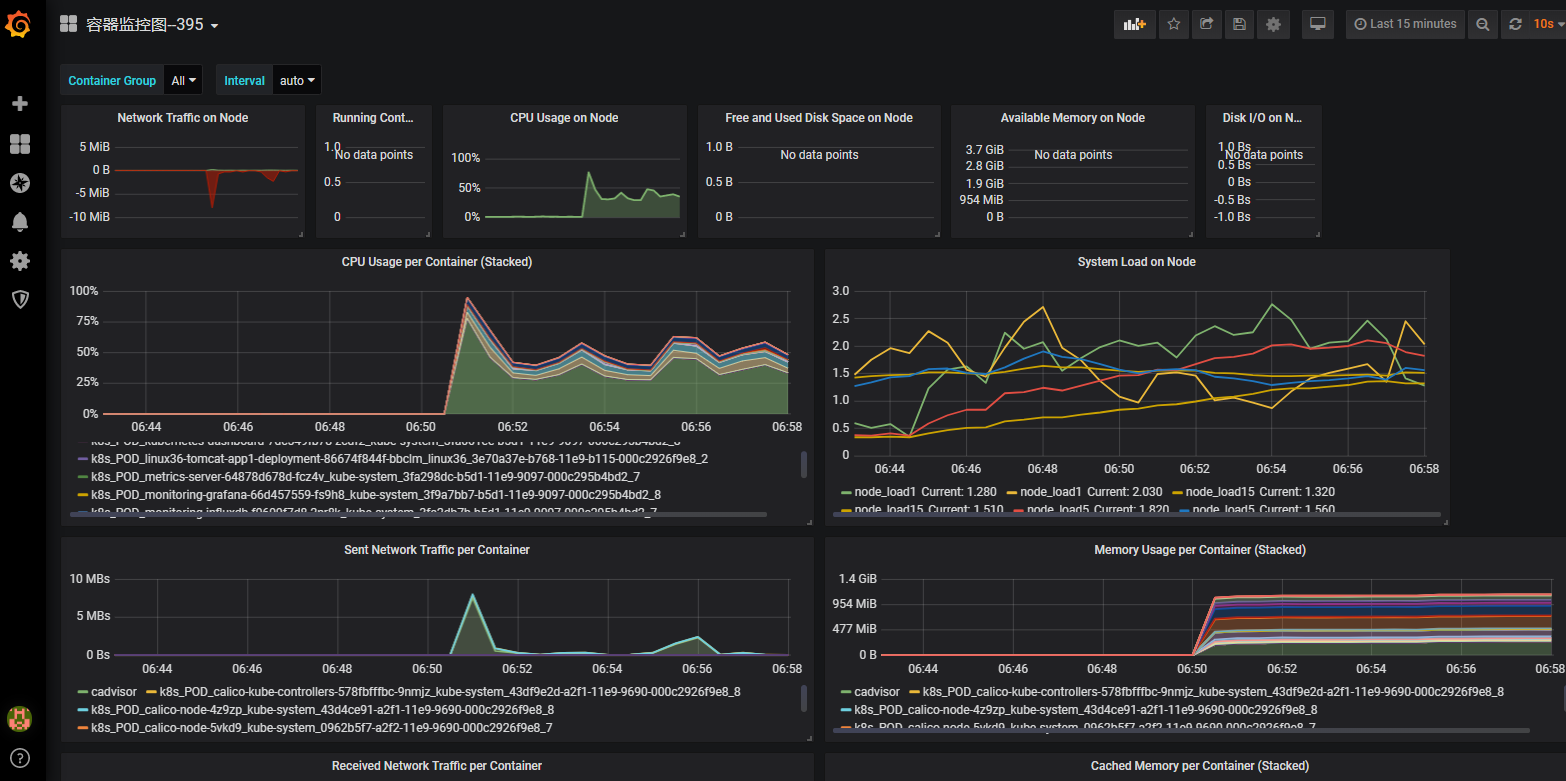
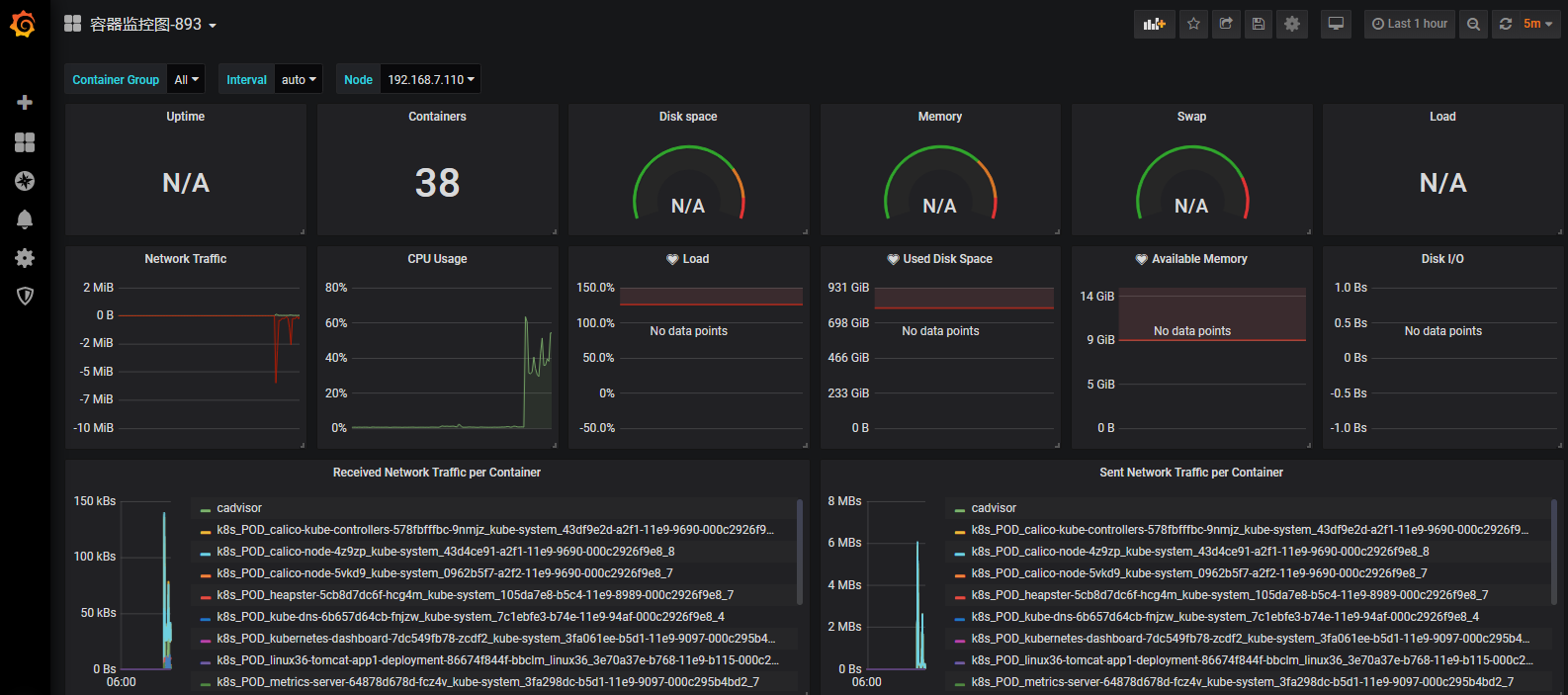
395 893 容器模板ID
395模板
893模板:
本文来自博客园,作者:不会跳舞的胖子,转载请注明原文链接:https://www.cnblogs.com/rtnb/p/16204229.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号