
ELK-Elasticsearch v7.6.1集群部署与使用
官网:Multiline codec plugin | Logstash Reference [8.2] | Elastic
Master 与 Slave 的区别
Master 的职责:
统计各 node 节点状态信息、集群状态信息统计、索引的创建和删除、索引分配的管理、关闭 node 节点等
Slave 的职责:从 master 同步数据、等待机会成为 Master
分片:
早期版本ES v5.X v2.x V6.X默认是5个分片,v7.X改成默认一个分片,把数据拆成5份写入 ES集群
16核心,30G等于物理机内存的一半,磁盘 2T 8块15K 600G
elasticsearch:
1.x 2.x 5.x 6.x 都没有集成JDK的安装包,也就是需要自己安装java环境
7.x 会单独出现带JDK的安装包和不带JDK,带JDK的不需要自己在服务器安装java,如果不带JDK仍然需要自己去安装java
elasticsearch优化部分:
一个是内核参数
一个是资源限制
需要允许elasticsearch用户占用系统的资源上限
内存优化
推荐是宿主机的一半内存,最大不超过30G
索引=index
index的创建机制:
按天创建
访问量比较大的业务日志,比如各种web服务的访问日志
按周创建
网络设备的日志,web服务错误日志
按月创建
系统日志,/var/log/message /var/log/syslog
分片:将数据分布式存储到不同的主机,加速存储与数据读取。负责数据读写。
副本:每个主分片的备份,当主分片运行的节点挂了,提升为主分片。
ES集群状态:
绿色状态:
表示集群各节点运行正常,而且没有丢失任何数据,各主分片和副本分片都运行正常
黄色状态:
表示由于某个节点宕机或者其他情况引起的,node节点无法连接、副本分片丢失等场景,但是还没有丢失任何数据
红色状态:
表示由于某个节点宕机或者其他情况引起的主分片丢失及数据丢失
监控:调用内置API,比如调用内置health API,对status code 进行判断
一、RPM部署elastisearch
官网下载:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-6-1 清华镜像:https://mirrors.tuna.tsinghua.edu.cn/
1.1 挂载磁盘
]# mkdir /elk [root@nginx-3 ~]# mount /dev/sdb /elk/ [root@nginx-3 ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 1.9G 0 1.9G 0% /dev tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm tmpfs tmpfs 1.9G 13M 1.9G 1% /run tmpfs tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup /dev/sda3 xfs 48G 5.6G 43G 12% / /dev/sda1 xfs 297M 163M 135M 55% /boot tmpfs tmpfs 378M 12K 378M 1% /run/user/42 tmpfs tmpfs 378M 0 378M 0% /run/user/0 /dev/sdb xfs 50G 33M 50G 1% /elk
1.2 修改配置
]# vim elasticsearch.yml
cluster.name: magedu-elastisearch-cluster //集群名称必须一致 node.name: node1 //节点名称唯一 path.data: /elk/esdata path.logs: /elk/eslogs #bootstrap.memory_lock: true //内存限制,默认1G network.host: 0.0.0.0 http.port: 9200 //客户端,内部通讯端口9300 discovery.seed_hosts: ["192.168.64.130", "192.168.64.131", "192.168.64.132"] //集群发现 cluster.initial_master_nodes: ["192.168.64.130", "192.168.64.131", "192.168.64.132"] //哪些节点可以被选举为master gateway.recover_after_nodes: 2 //半数以上机制,半数以上启动恢复 #设置是否可以通过正则或者_all 删除或者关闭索引库,默认 true 表示必须需要显式指定索引库名称,生产环境建议设置为 true,删除索引库的时候必须指定,否则可能会误删索引库中的索引库。 action.destructive_requires_name: true
1.3 创建用户
因elastisearch拒绝以root启动服务,因此需要创建用户以及修改目录权限,确保用户有权限访问目录。
useradd elasticsearch
mkdir -p /elk/{esdata,eslogs}
修改权限
chown elasticsearch:elasticsearch /elk/ -R chown -R elasticsearch:elasticsearch elk/ chown -R elasticsearch:elasticsearch /etc/elasticsearch/ 127 chown -R es:es /es7/ 128 chown -R es:es /data/ 141 chown -R es:es /etc/elasticsearch/ 144 chown -R es:es /usr/share/elasticsearch 159 chown -R es:es /etc/sysconfig/elasticsearch 163 chown -R es:es /var/log/elasticsearch
1.4 修改内核参数
elasticsearch用户拥有的内存权限太小,至少需要262144,不然启动报错:
ERROR: [1] bootstrap checks failed [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] ERROR: Elasticsearch did not exit normally - check the logs at /elk/eslogs/magedu-elastisearch-cluster.log
解决方法:
vim /etc/sysctl.conf vm.max_map_count=262144 sysctl -p
[root@iZbp16v2hjkzko44az1ku6Z data]# grep "^[-]" /etc/elasticsearch/jvm.options -Xms32g -Xmx32g
1.5 修改内存限制 , 并同步 配置 文件
[root@linux-host1 ~]# vim /usr/lib/systemd/system/elasticsearch.service #修改内存限制
LimitMEMLOCK=infinity #无限制使用内存
补充:二进制部署es修改内存限制
root soft nofile 65535 root hard nofile 65535 * soft nofile 65535 * hard nofile 65535 * soft nproc unlimited * hard nproc unlimited * soft memlock unlimited * hard memlock unlimited * soft core unlimited * hard core unlimited * soft stack unlimited * hard stack unlimited es soft nofile 65536 es hard nofile 65536
1.6 查看端口,测试访问页面
]# netstat -ntpl | grep 9200 tcp6 0 0 :::9200 :::* LISTEN 6012/java
访问:
192.168.64.130:9200
测试
[root@iZbp16v2hjkzko44az1ku6Z data]# curl localhost:9200 { "name" : "iZbp16v2hjkzko44az1ku6Z", "cluster_name" : "konne-es-0602", "cluster_uuid" : "DdJCCmMgTviW5-KtY_Pemw", "version" : { "number" : "7.16.2", "build_flavor" : "default", "build_type" : "rpm", "build_hash" : "2b937c44140b6559905130a8650c64dbd0879cfb", "build_date" : "2021-12-18T19:42:46.604893745Z", "build_snapshot" : false, "lucene_version" : "8.10.1", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
二、安装 elasticsearch 插件
2.1 head
插件是为了完成不同的功能,官方提供了一些插件但大部分是收费的,另外也有一些开发爱好者提供的插件,可以实现对 elasticsearch 集群的状态监控与管理配置等功能。安装 5.x 版本的 的 head 插件:
在 elasticsearch 5.x 版本以后不再支持直接安装 head 插件,而是需要通过启动一个服务方式
git 地址:https://github.com/mobz/elasticsearch-head
docker run -d -p 9100:9100 mobz/elasticsearch-head:5
连接集群
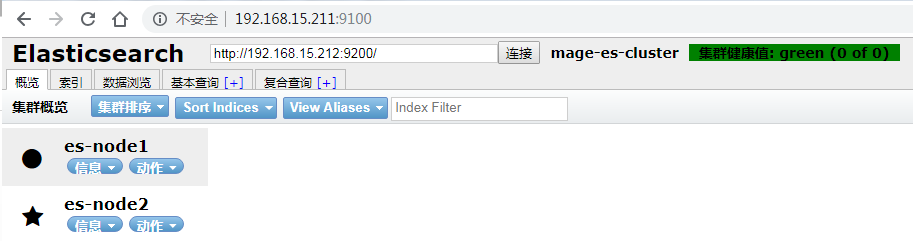
2.1 cerebro插件安装
新开源的 elasticsearch 集群 web 管理程序,需要 java1.8 或者更高版本,https://github.com/lmenezes/cerebro
cd /usr/local/src/cerebro-0.8.5 vim conf/application.conf hosts = [ { host = "http://172.31.0.201:9200" name = "magedu" # headers-whitelist = [ "x-proxy-user", "x-proxy-roles", "X-Forwarded-For" ] }
启动
./bin/cerebro
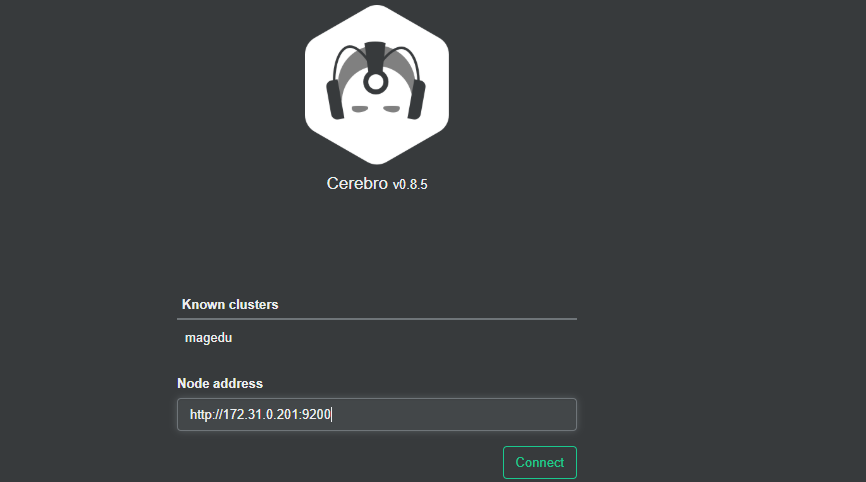
节点信息统计
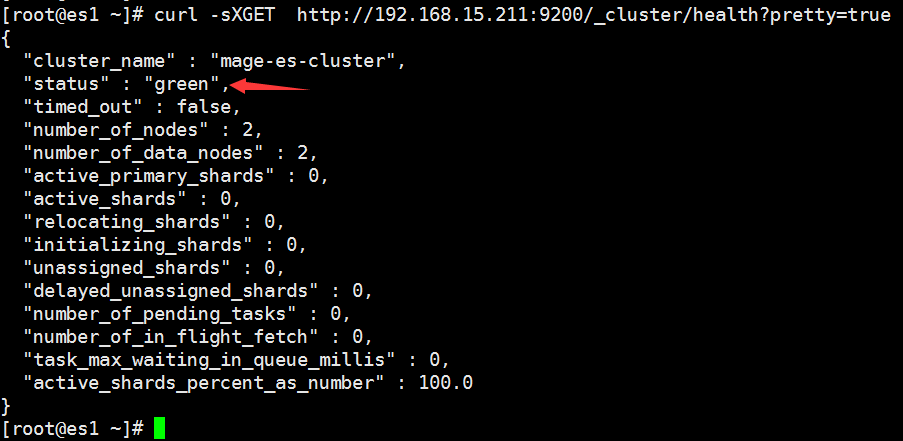
2.3 监控 h elasticsearch 集群状态
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_cluster_health.htmlcurl -sXGET http://192.168.15.211:9200/_cluster/health?pretty=true
三、logstash安装
Logstash 是一个开源的数据收集引擎,可以水平伸缩,而且 logstash 整个 ELK当中拥有最多插件的一个组件,其可以接收来自不同来源的数据并统一输出到指定的且可以是多个不同目的地。
https://github.com/elastic/logstash
关闭防火墙和 selinux,并且安装 java 环境 [root@linux-host3 ~]# systemctl stop firewalld [root@linux-host3 ~]# systemctl disable firewalld [root@linux-host3 ~]# sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config [root@linux-host3 ~]# yum install jdk-8u121-linux-x64.rpm [root@linux-host3 ~]# java -version java version "1.8.0_121" Java(TM) SE Runtime Environment (build 1.8.0_121-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode) [root@linux-host3 ~]# reboot
在清华镜像站下载安装包
[root@linux-host3 ~]# yum install logstash-5.3.0.rpm [root@linux-host3 ~]# chown logstash.logstash /usr/share/logstash/data/queue –R #权限更改为 logstash 用户和组,否则启动的时候日志报错
3.1 测试 logstash
测试标准输入和输出
[root@linux-host3 ~]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug }}' #标准输入和输出
hello { "@timestamp" => 2017-04-20T02:30:01.600Z, #当前事件的发生时间, "@version" => "1", #事件版本号,一个事件就是一个 ruby 对象 "host" => "linux-host3.exmaple.com", #标记事件发生在哪里 "message" => "hello" #消息的具体内容 }
测试输出到文件
[root@linux-host3 ~]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { file { path => "/tmp/log-%{+YYYY.MM.dd}messages.gz"}}' hello 11:01:15.229 [[main]>worker1] INFO logstash.outputs.file - Opening file {:path=>"/tmp/log-2017-04-20messages.gz"} [root@linux-host3 ~]# tail /tmp/log-2017-04-20messages.gz #打开文件验证
测试输出到 elasticsearch
[root@linux-host3 ~]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch {hosts => ["192.168.15.11:9200"] index => "mytest-%{+YYYY.MM.dd}" }}'

elasticsearch 服务器验证收到数据
[root@linux-host1 ~]# ll /elk/data/nodes/0/indices/ #5.x 版本以后不再显示原名称 total 0 drwxr-xr-x 8 elasticsearch elasticsearch 59 Apr 19 19:08 JbnPSBGxQ_WbxT8jF5-TLw drwxr-xr-x 8 elasticsearch elasticsearch 59 Apr 19 20:18 kZk1UbsjTliYfooevuQVdQ drwxr-xr-x 4 elasticsearch elasticsearch 27 Apr 19 19:24 m6EiWqngS0C1bspg8JtmBg drwxr-xr-x 8 elasticsearch elasticsearch 59 Apr 20 08:49 YhtJ1dEXSOa0YEKhe6HW8w
四、kibana 部署 及日志 收集
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作,可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作,您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
https://github.com/elastic/kibana
默认端口:5601
[root@linux-host1 ~]# yum localinstall kibana-5.3.0-x86_64.rpm
[root@linux-host1 ~]# grep -n "^[a-Z]" /etc/kibana/kibana.yml 2:server.port: 5601 #监听端口 7:server.host: "0.0.0.0" #监听地址 28:elasticsearch.hosts: ["http://192.168.7.101:9200"] 114:i18n.locale: "zh-CN" #支持中文 21:elasticsearch.url: http://192.168.15.11:9200 #elasticsearch 服务器地址
本文来自博客园,作者:不会跳舞的胖子,转载请注明原文链接:https://www.cnblogs.com/rtnb/p/16154576.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号