开始学习Python爬虫-简单的爬取网站和简单的防反爬
今天开始学习Python爬虫的知识,学习了最基础的爬取网页的知识。我爬取了两个网站作为测试,一个是测试网站,
一个就是豆瓣网的top250的网页,爬取成功了。
我们首先需要用到import requests
这是爬取网页的最基本方法:

import requests response = requests.get("http://books.toscrape.com/") if response.ok: print("请求成功") print(response.text) else: print("请求失败")
对于有简单反爬机制的网站,我们可以用简单的方式伪装一下,让这些网站认为我们是浏览器访问的
比如豆瓣,我们可以先打开随便一个网站,点击f12,再点击NetWork,然后刷新一下,选择Request Headers,
找到User-Agent这一行,复制:
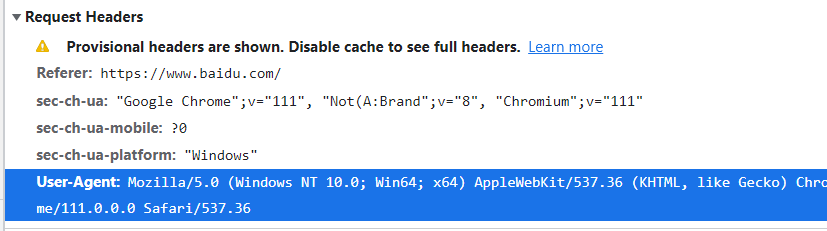
直接用百度的:
我们把上面的东西复制下来:
headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36" }
爬取豆瓣网的python代码:
import requests from bs4 import BeautifulSoup headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36" } content = requests.get("https://movie.douban.com/top250",headers=headers).text soup = BeautifulSoup(content, "html.parser") print(soup.p)
作者:冰稀饭Aurora
出处:https://www.cnblogs.com/rsy-bxf150/p/17270373.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端