牌桶限流 漏桶限流 guava ratelimiters
https://www.alibabacloud.com/blog/detailed-explanation-of-guava-ratelimiters-throttling-mechanism_594820
限流算法实践 https://mp.weixin.qq.com/s/2f5-2bydqbecIWQ9DDxGRg
限流算法实践
奇技 · 指南
今天小编带大家了解什么是限流?希望阅读完本文后,能对大家有所帮助。
1
限流简介
什么是限流
在不同场景下限流的定义也各不相同,可以是每秒请求数、每秒事务处理数、网络流量。
通常我们所说的限流指的是限制到达系统并发请求数,使得系统能够正常的处理部分用户的请求,来保证系统的稳定性。
为什么限流
接口无法控制调用方的行为。热点业务突发请求、恶意请求攻击等会带来瞬时的请求量激增,导致服务占用大量的 CPU、内存等资源,使得其他正常的请求变慢或超时,甚至引起服务器宕机。
按照请求次数进行收费的接口需要根据客户支付的金额来限制客户可用的次数。
限流的行为
限流的行为指的就是在接口的请求数达到限流的条件时要触发的操作,一般可进行以下行为。
-
拒绝服务:把多出来的请求拒绝掉
-
服务降级:关闭或是把后端服务做降级处理。这样可以让服务有足够的资源来处理更多的请求
-
特权请求:资源不够了,我只能把有限的资源分给重要的用户
-
延时处理:一般会有一个队列来缓冲大量的请求,这个队列如果满了,那么就只能拒绝用户了,如果这个队列中的任务超时了,也要返回系统繁忙的错误了
-
弹性伸缩:用自动化运维的方式对相应的服务做自动化的伸缩
2
限流架构
单点限流
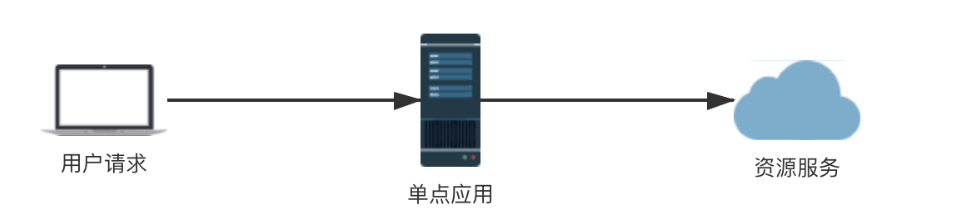
当我们的系统应用只部署在一个节点上来提供服务时,就可以采用单点限流的架构来对应用的接口进行限流,只要单点应用进行了限流,那么他所依赖的各种服务也得到了保护。
分布式限流
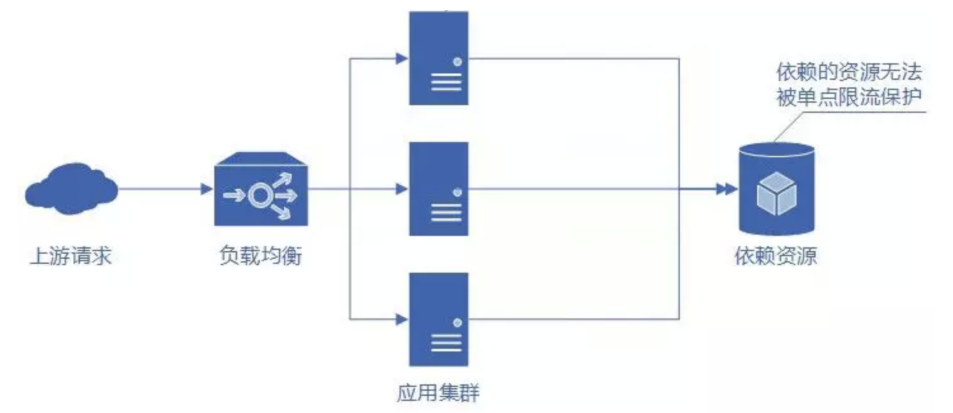
为了提供高性能的服务,往往我们的应用都是以集群结构部署在多个节点上的。这时候单点限流只能限制传入单个节点的请求,保护自身节点,无法保护应用依赖的各种服务资源。那么如果在集群中的每个节点上都进行单点限流是否可行呢?
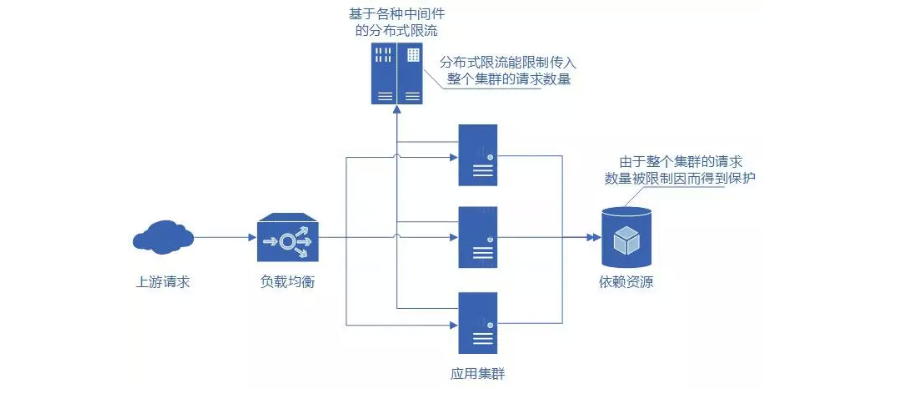
3
限流算法
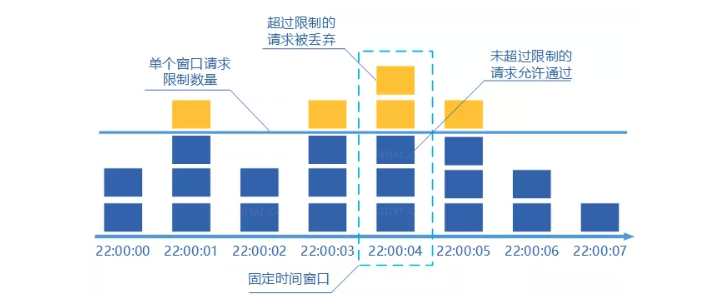
固定窗口计数器
-
将时间按照设定的周期划分为多个窗口
-
在当前时间窗口内每来一次请求就将计数器加一
-
如果计数器超过了限制数量,则拒绝服务
- 当时间到达下一个窗口时,计数器的值重置
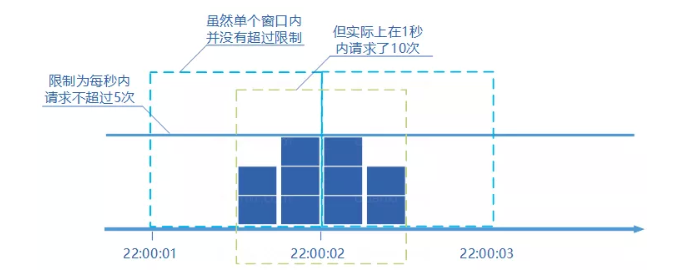
假设限制每秒通过5个请求,时间窗口的大小为1秒,当前时间窗口周期内的后半秒正常通过了5个请求,下一个时间窗口周期内的前半秒正常通过了5个请求,在这两个窗口内都没有超过限制。但是在这两个窗口的中间那一秒实际上通过了 10 个请求,显然不满足每秒5个请求的限制。
滑动窗口计数器
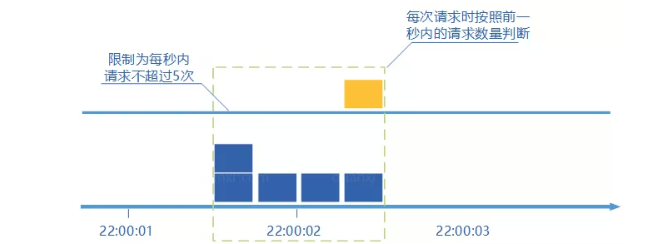
-
将设定的时间周期设为滑动窗口的大小,记录每次请求的时刻
-
当有新的请求到来时将窗口滑到该请求来临的时刻
-
判断窗口内的请求数是否超过了限制,超过限制则拒绝服务,否则请求通过
- 丢弃滑动窗口以外的请求
这种算法解决了固定窗口计数器出现的通过请求数是限制数两倍的缺陷,但是实现起来较为复杂,并且需要记录窗口周期内的请求,如果限流阈值设置过大,窗口周期内记录的请求就会很多,就会比较占用内存
漏桶算法
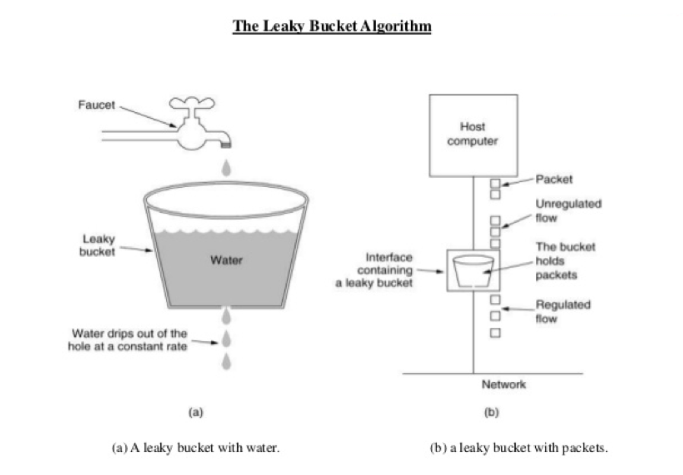
-
将进来的请求流量视为水滴先放入桶内
-
水从桶的底部以固定的速率匀速流出,相当于在匀速处理请求
- 当漏桶内的水满时(超过了限流阈值)则拒绝服务
但是漏桶算法也有一定的缺陷,因为水从桶的底部以固定的速率匀速流出,当有在服务器可承受范围内的瞬时突发请求进来,这些请求会被先放入桶内,然后再匀速的进行处理,这样就会造成部分请求的延迟。所以他无法应对在限流阈值范围内的突发请求。
令牌桶算法
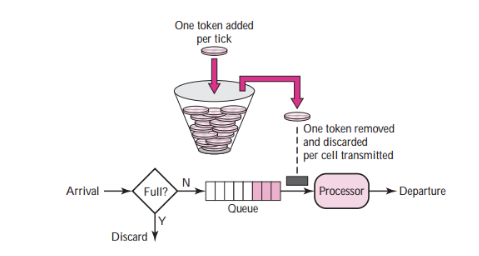
-
按照一定的速率生产令牌并放入令牌桶中
-
如果桶中令牌已满,则丢弃令牌
-
请求过来时先到桶中拿令牌,拿到令牌则放行通过,否则拒绝请求
这种算法能够把请求均匀的分配在时间区间内,又能接受服务可承受范围内的突发请求。所以令牌桶算法在业内使用也非常广泛。接下来会详细介绍该算法的实现。
4
令牌桶算法实现
我们采用 Redis + Lua 脚本的方式来实现令牌桶算法,在 Redis 中使用 Lua 脚本有诸多好处,例如:
-
减少网络开销:本来多次网络请求的操作,可以用一个请求完成,原先多次请求的逻辑放在 Redis 服务器上完成。使用脚本,减少了网络往返时延。
-
原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他进程或者进程的命令插入。
-
复用:客户端发送的脚本会永久存储在Redis中,意味着其他客户端可以复用这一脚本而不需要使用代码完成同样的逻辑。
-
复用:客户端发送的脚本会永久存储在Redis中,意味着其他客户端可以复用这一脚本而不需要使用代码完成同样的逻辑。
这其中最重要的方法就是原子操作。将 Redis 的多条命令写成一个 Lua 脚本,然后调用脚本执行操作,相当于只有一条执行脚本的命令,所以整个 Lua 脚本中的操作都是原子性的。
在 Redis 中使用 Lua 脚本主要涉及 Script Load、Eval、Evalsha 三个命令:
Eval ${lua_script} 可以直接执行 Lua 脚本。
Script Load ${lua_script} 命令是将脚本载入 Redis,载入成功后会返回一个脚本的sha1值,一旦载入则永久存储在 Redis 中,后续可以通过 Evalsha ${sha1} 来直接调用此脚本。我们采用先 Load 脚本得到 Sha1 值,再调用这个 sha1 值来执行脚本的方式可以减少像eval ${lua_script} 命令这样每次都向 Redis 中发送一长串 Lua 脚本带来的网络开销。
使用 Redis 中的 Hash 数据结构来存储限流配置,每个 Hash 表的 Key 为限流的粒度,可以是接口Uri、客户端 IP、应用uuid或者他们的组合形式。每个 Hash 表为一个令牌桶,Hash 表中包含如下字段:
-
last_time最近一次请求的时间戳,毫秒级别。 -
curr_permits当前桶内剩余令牌数量,单位为:个。 -
bucket_cap桶的容量,即桶内可容纳最大令牌数量,代表限流时间周期内允许通过的最大请求数。 -
period限流的时间周期,单位为:秒。 -
rate令牌产生的速率,单位:个/秒,rate = bucket_cap / period
在上面的令牌桶算法描述中生产令牌的方式是按照一定的速率生产令牌并放入令牌桶中,这种方式需要一个线程不停地按照一定的速率生产令牌并更新相应的桶,如果被限流的接口(每个桶)令牌生产的速率都不一样,那么就需要开多个线程,很浪费资源。
为了提高系统的性能,减少限流层的资源消耗,我们将令牌的生产方式改为:每次请求进来时一次性生产上一次请求到本次请求这一段时间内的令牌。随意每次请求生成的令牌数就是 (curr_time -last_time) / 1000 * rate,注意:这里两次时间戳的差值单位是毫秒,而令牌产生速率的单位是 个/秒,所以要除以 1000,把时间戳的差值的单位也换算成秒。
令牌桶算法的实现逻辑为:

假如我们的限流策略是一分钟内最多能通过600个请求,那么相应的令牌产生速率为 600 / 60 = 10 (个/秒) 。那么当限流策略刚刚配置好这一时刻就有突发的10个请求进来,此时令牌桶内还没来的及生产令牌,所以请求拿不到令牌就会被拒绝,这显然不符合我们要求。
为了解决这一问题,我们在限流策略刚刚配置好后的第一个请求来临时将当前可用令牌的值设置为桶的最大容量 600,将最近一次请求时间设置为本次请求来临时一分钟后的时间戳,减去出本次请求需要的令牌后更新桶。这样,在这一分钟以内,有下一次请求进来时,从 Hash 表内取出配置计算当前时间就会小于最近一次请求的时间,随后计算生成的令牌就会是一个小于0的负数。所以在更新桶这一步,要根据生成的令牌是否为负数来决定是否更新最后一次请求时间的值。用 Lua 脚本实现上述逻辑:
local key = KEYS[1] -- 要进行限流的Key,可以是 urilocal consume_permits = tonumber(ARGV[1]) -- 请求消耗的令牌数,每个请求消耗一个local curr_time = tonumber(ARGV[2]) -- 当前时间local limiter_info = redis.pcall("HMGET", key, "last_time", "curr_permits", "bucket_cap", "rate", "period")if not limiter_info[3] thenreturn -1endlocal last_time = tonumber(limiter_info[1]) or 0local curr_permits = tonumber(limiter_info[2]) or 0local bucket_cap = tonumber(limiter_info[3]) or 0local rate = tonumber(limiter_info[4]) or 0local period = tonumber(limiter_info[5]) or 0local total_permits = bucket_caplocal is_update_time = trueif last_time > 0 thenlocal new_permits = math.floor((curr_time-last_time)/1000 * rate)if new_permits <= 0 thennew_permits = 0is_update_time = falseendtotal_permits = new_permits + curr_permitsif total_permits > bucket_cap thentotal_permits = bucket_capendelselast_time = curr_time + period * 1000endlocal res = 1if total_permits >= consume_permits thentotal_permits = total_permits - consume_permitselseres = 0endif is_update_time thenredis.pcall("HMSET", key, "curr_permits", total_permits, "last_time", curr_time)elseredis.pcall("HSET", key, "curr_permits", total_permits)endreturn res
上述脚本在调用时接收三个参数,分别为:限流的key、请求消耗的令牌数、 当前时间戳(毫秒级别)。
在我们的业务代码中,先调用 Redis 的SCRIPT LOAD 命令将上述脚本 Load 到 Redis 中并将该命令返回的脚本 sha1 值保存。
在后续的请求进来时,调用 Redis 的 EVALSHA 命令执行限流逻辑,根据返回值判断是否对本次请求触发限流行为。假如限流的 key 为每次请求的 uri,每次请求消耗 1 个令牌,那么执行 Evalsha 命令进行限流判断的具体操作为:EVALSHA ${sha1} 1 ${uri} 1 ${当前时间戳} (第一个数字 1 代表脚本可接收的参数中有 1 个Key,第二个数字 1 代表本次请求消耗一个令牌);执行完这条命令后如果返回值是 1 代表桶中令牌够用,请求通过;如果返回值为 0 代表桶中令牌不够,触发限流;如果返回值为 -1 代表本次请求的 uri 未配置限流策略,可根据自己的实际业务场景判断是通过还是拒绝。
5
总结
本文主要介绍了四种限流的算法,分别为:固定窗口计数器算法、滑动窗口计数算法、漏桶算法、令牌桶算法。
-
固定窗口计数算法简单易实现,其缺陷是可能在中间的某一秒内通过的请求数是限流阈值的两倍,该算法仅适用于对限流准确度要求不高的应用场景。
-
滑动窗口计数算法解决了固定窗口计数算法的缺陷,但是该算法较难实现,因为要记录每次请求所以可能出现比较占用内存比较多的情况。
-
漏桶算法可以做到均匀平滑的限制请求,Ngixn 热 limit_req 模块也是采用此种算法。因为匀速处理请求的缘故所以该算法应对限流阈值内的突发请求无法及时处理。
- 令牌桶算法解决了以上三个算法的所有缺陷,是一种相对比较完美的限流算法,也是限流场景中应用最为广泛的算法。使用 Redis + Lua脚本的方式可以简单的实现。
参考链接
https://www.nginx.com/blog/rate-limiting-nginx/
https://www.infoq.cn/article/qg2tx8fyw5vt-f3hh673https://segmentfault.com/a/1190000019676878https://en.wikipedia.org/wiki/Token_bucket
有赞API网关实践 https://tech.youzan.com/api-gateway-in-practice/
有赞API网关实践
一、API网关简介
随着移动互联网的兴起、开放合作思维的盛行,不同终端和第三方开发者都需要大量的接入企业核心业务能力,此时各业务系统将会面临同一系列的问题,例如:如何让调用方快速接入、如何让业务方安全地对外开放能力,如何应对和控制业务洪峰调用等等。于是就诞生了一个隔离企业内部业务系统和外部系统调用的屏障 - API网关,它负责在上层抽象出各业务系统需要的通用功能,例如:鉴权、限流、ACL、降级等。另外随着近年来微服务的流行,API网关已经成为一个微服务架构中的标配组件。
二、有赞API网关简介
有赞API网关目前承载着微商城、零售、微小店、餐饮、美业、AppSDK、部分PC、三方开发者等多个业务的调用,每天有着亿级别的流量。
有赞后端服务最开始是由PHP搭建,随着整个技术体系的升级,后面逐步从PHP迁移到Java体系。在API网关设计之初主要支持Dubbo、Http两种协议。迁移过程中,我们发现部分服务需要通过RPC方式调用PHP服务,于是我们(公司)基于Dubbo开发了一个新的框架Nova,兼容Dubbo调用,同时支持调用PHP服务。于是网关也支持了新的Nova协议,这样就有Dubbo、Http、Nova三种协议。
随着业务的不断发展,业务服务化速度加快,网关面临各类新的需求。例如回调类型的API接入,这种API不需要鉴权,只需要一个限流服务,路由到后端服务即可;另外还有参数、返回值的转换需求也不断到来,这期间我们快速迭代满足新的需求。而在这个过程中我们也走了很多弯路,例如API的规范,在最开始规范意识比较笼统,导致返回值在对外暴露时出现了不统一的情况,后续做SDK自动化的时候比较棘手,经过不断的约束开发者,最终做到了统一。
三、架构与设计
1. 网关架构
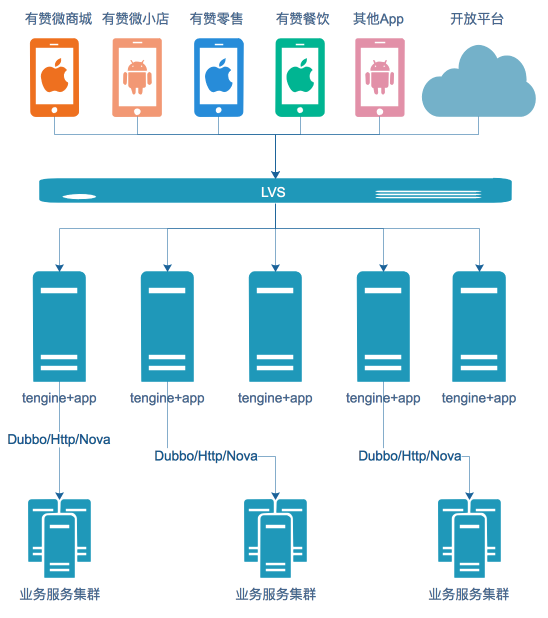
网关的调用方主要包括微商城、微小店、零售等App应用,以及三方开发者和部分PC业务。通过LVS做负载均衡,后端Tengine实现反向代理,网关应用调用到实际的业务集群
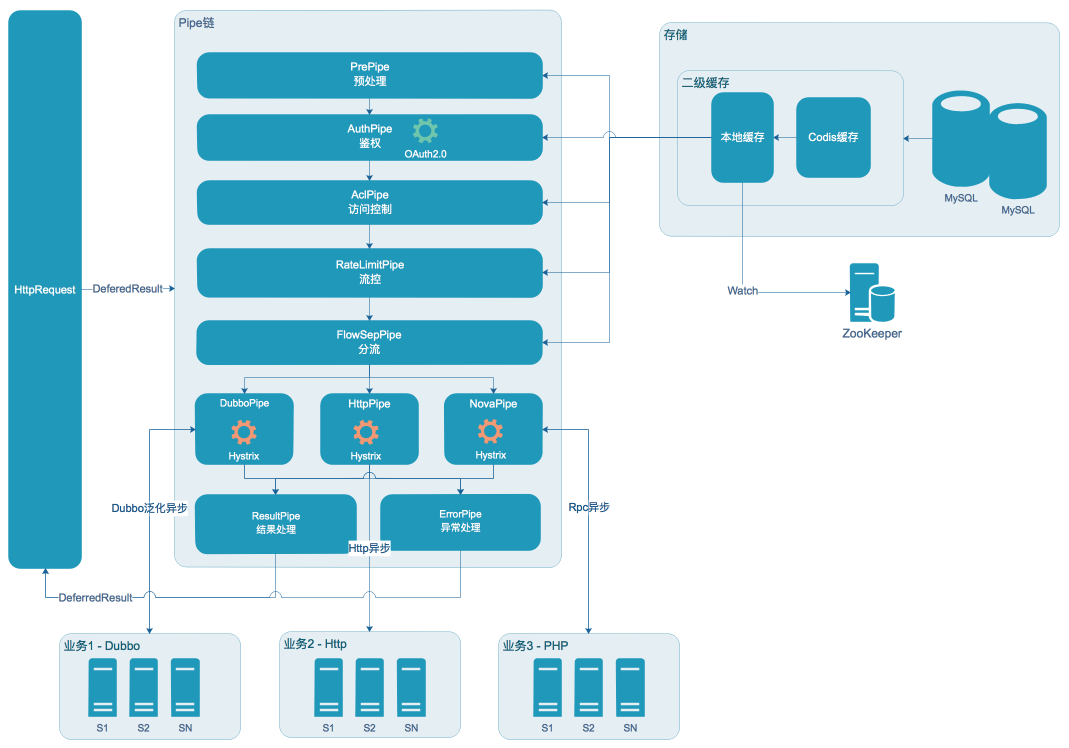
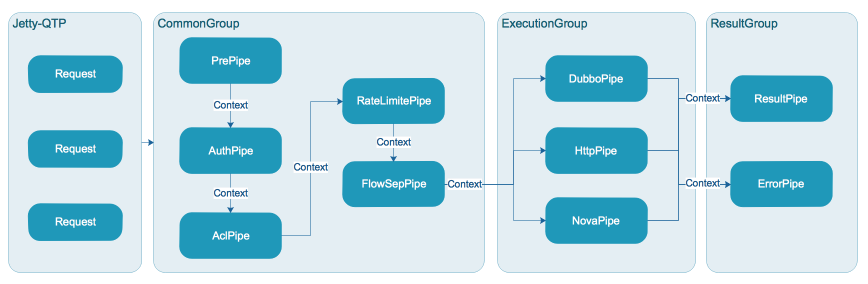
网关核心由Pipe链构成,每个Pipe负责一块功能,同时使用缓存、异步等特性提升并发及性能
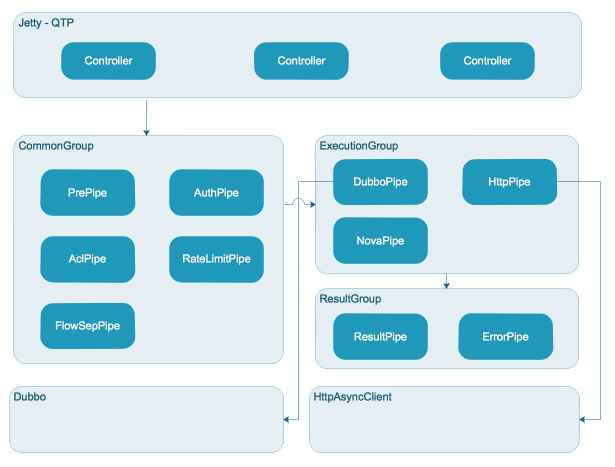
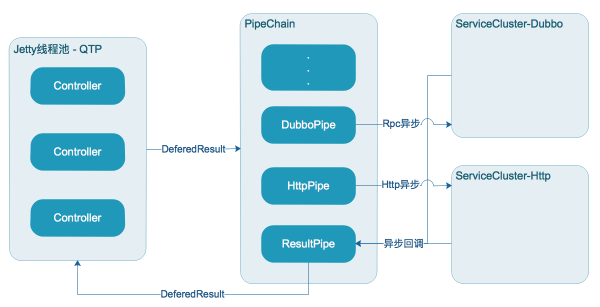
网关采用Jetty部署,调用采用Http协议,请求由容器线程池处理(容器开启了Servlet3.0异步,提升了较大的吞吐量),之后分发到应用线程池异步处理。应用线程池在设计之初考虑不同的任务执行可能会出现耗时不一的情况,所以将任务分别拆分到不同的线程池,以提高不同类型任务的并发度,如图分为CommonGroup, ExecutionGroup, ResultGroup
CommonGroup执行通用任务,ExecutionGroup执行多协议路由及调用任务,ResultGroup执行结果处理任务(包含异常)
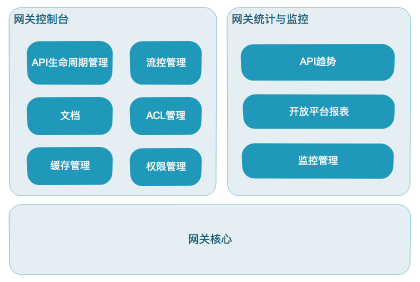
网关生态主要包含控制台、网关核心、网关统计与监控
控制台主要对API生命周期进行管理,以及ACL、流量管控等功能;
网关核心主要处理API调用,包含鉴权、限流、路由、协议转换等功能;
统计与监控模块主要完成API调用的统计以及对店铺、三方的一些报表统计,同时提供监控功能和报警功能
2. 网关核心设计
2.1 异步
我们使用Jetty容器来部署应用,并开启Servlet3.0的异步特性,由于网关业务本身就是调用大量业务接口,因此IO操作会比较频繁,使用该特性能较大提升网关整体并发能力及吞吐量。另外我们在内部处理开启多组线程池进行异步处理,以异步回调的方式通知任务完成,进一步提升并发量
2.2 二级缓存
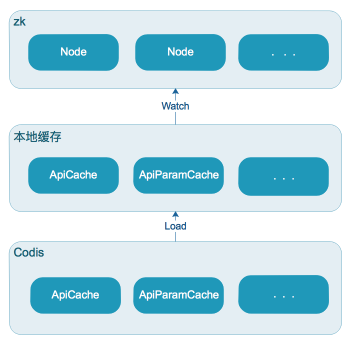
为了进一步提升网关的性能,我们增加了一层分布式缓存(借用Codis实现),将一些不经常变更的API元数据缓存下来,这样不仅减少了应用和DB的交互次数,还加快了读取效率。我们同时考虑到Codis在极端情况下存在不稳定因素,因此我们在本地再次做了本地缓存,这样的读取可以从ms级别降低到ns级别。为了实现多台机器的本地缓存一致性,我们使用了ZK监听节点变化来更新各机器本地缓存
2.3 链式处理
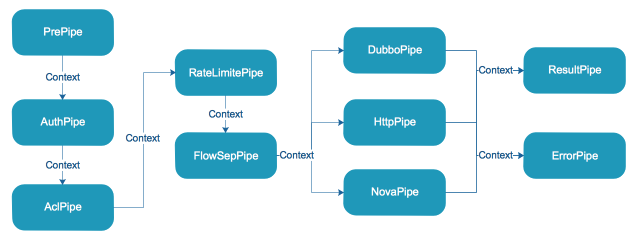
在设计网关的时候,我们采用责任链模式来实现网关的核心处理流程,将每个处理逻辑看成一个Pipe,每个Pipe按照预先设定的顺序先后执行,与开源的Zuul 1.x类似,我们也采用了PRPE模式(Pre、Routing、Post、Error),在我们这里Pre分为PrePipe、RateLimitPipe、AuthPipe、AclPipe、FlowSepPipe,这些Pipe对数据进行预处理、限流、鉴权、访问控制、分流,并将过滤后的Context向下传递;Routing分为DubboPipe、HttpPipe,这些Pipe分别处理Dubbo协议、Http协议路由及调用;Post为ResultPipe,处理正常返回值以及统计打点,Error为ErrorPipe,处理异常场景
2.4 线程池隔离
Jetty容器线程池(QTP)负责接收Http请求,之后交由应用线程池CommonGroup,ExecutionGroup, ResultGroup,通用的操作将会被放到CommonGroup线程池执行,执行真实调用的被放到ExecutionGroup,结果处理放到ResultGroup。这样部分Pipe之间线程隔离,通常前置Pipe处理都比较快,所以共享线程池即可,真实调用通常比较耗时,因此我们放到独立的线程池,同时结果处理也存在一些运算,因此也放到独立线程池
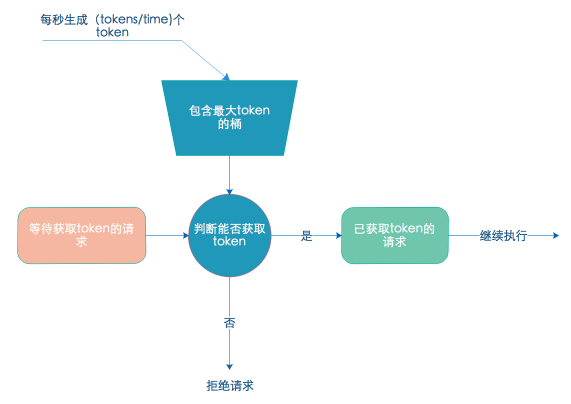
2.5 平滑限流
最早我们采用了简单的分布式缓存(Codis)计数实现限流,以IP、API维度构建Key进行累加,这种限流方式实现简单,但是不能做到连续时间段内平滑限流。例如针对某个API每分钟限流100次,第1秒发起20次,第二秒发起30次,第3秒发起40次,这样的限流波动比较大,因此我们决定将其改进。经过调研我们最终选择了令牌桶限流,令牌桶限流相比于漏桶限流能适应闲置较长时段后的尖峰调用,同时消除了简单计数器限流带来的短时间内流量不均的问题。目前网关支持IP、店铺、API、应用ID和三方ID等多个维度的限流,也支持各维度的自由组合限流,可以很容易扩展出新的维度
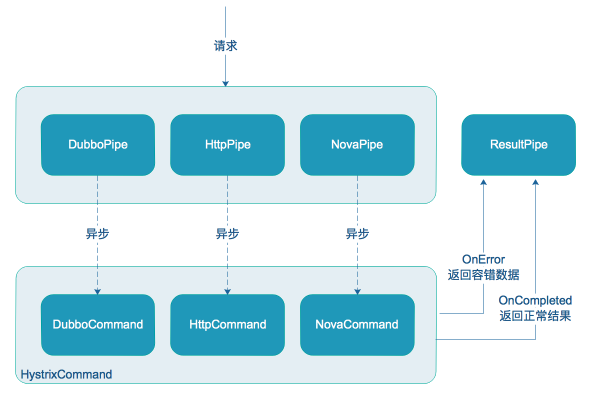
2.6 熔断降级
由于我们经常遇到调用后端接口超时,或者异常的情况,后端服务无法立即恢复,这种情况下再将请求发到后端已没有意义。于是我们使用Hystrix进行熔断降级处理。Hystrix支持线程池和信号量2种模式的隔离方案,网关的业务场景是多API和API分组,每个API都可能路由到不同后端服务,如果我们对API或者API分组做线程池隔离,就会产生大量的线程,所以我们选择了信号量做隔离。我们为每个API提供一个降级配置,用户可以选择自己配置的API在达到多少错误率时进行熔断降级。
引入Hystrix后,Hystrix会对每个API做统计,包括总量、正确率、QPS等指标,同时会产生大量事件,当API很多的时候,这些指标和事件会占用大量内存,导致更加频繁的YoungGC,这对应用性能产生了一定的影响,不过整体的收益还是不错的
另外有赞内部也开发了一个基于Hystrix的服务熔断平台(Tesla),平台在可视化、易用性、扩展性上面均有较大程度的提升;后续网关会考虑熔断模块的实现基于服务熔断平台,以提供更好的服务
2.7 分流
有赞内部存在多种协议类型的后端服务,最原始的服务是PHP开发,后面逐渐迁移到Java,很早一部分API是由PHP暴露的,后续为了能做灰度迁移到Java,我们做了分流,将老的PHP接口的流量按照一定的比例分发到新的Java接口上
3. 控制台
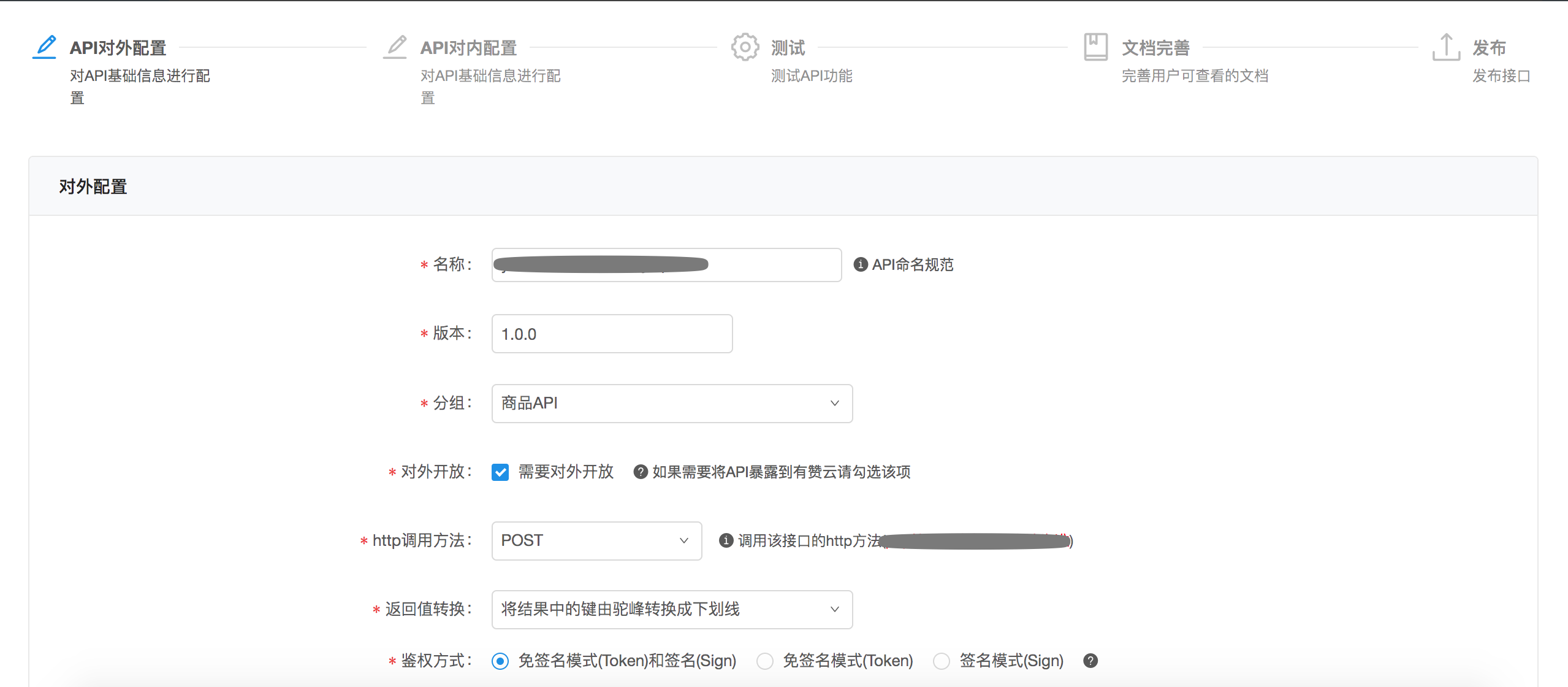
除了核心功能的调用外,网关还需要支持内部用户(下称业务方)快速配置接口暴露给开发者。 控制台主要职责包括:快速配置API、一站式测试API、一键发布API,自动化文档生成,自动化SDK生成
- 快速配置API:这块我们主要是按照对外、对内来进行配置,业务方将自己要对外公开的名称、参数编辑好,再通过对内映射将对外参数映射到内部服务的接口里面
- 一站式测试API:API配置完成后,为了能让业务方快速测试,我们做了一站式获取鉴权值,参数值自动保存,做到一站式测试
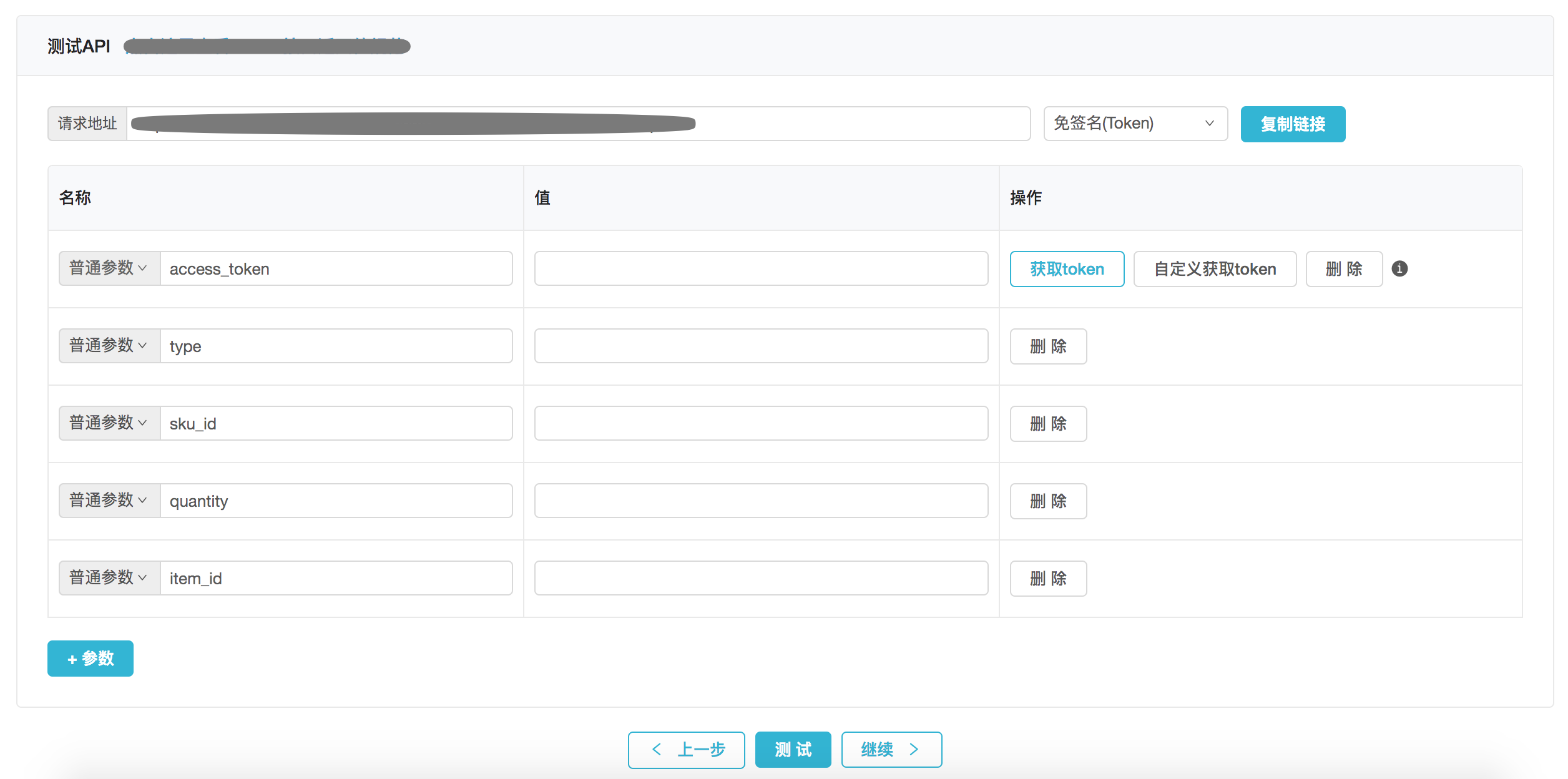
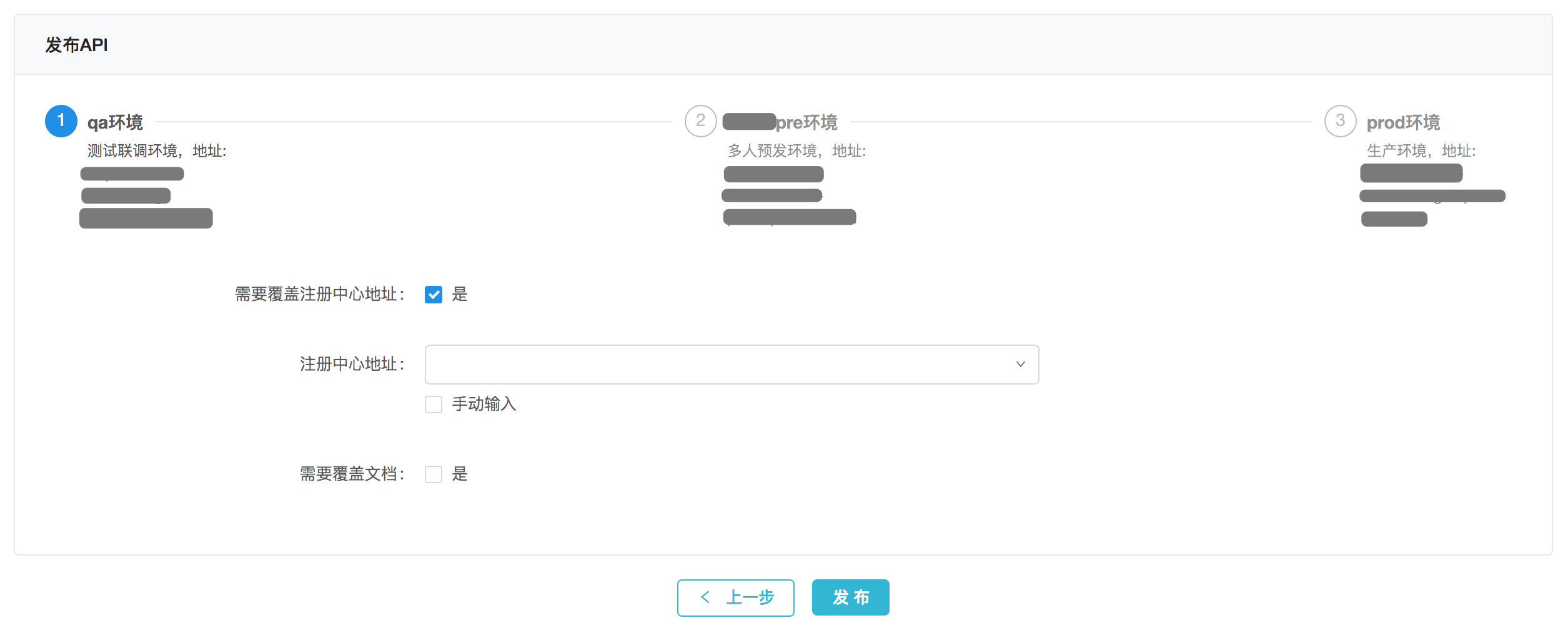
- 一键发布API:在完成配置和测试后,API就可以直接发布,这个时候选择对应环境的注册中心或者服务域名即可
- 自动化文档生成:我们针对文档这块做了文档中心,对内部用户,他们只需要到平台来搜索即可,对外部用户,可以在有赞云官网查看或者在控制台直接导出pdf文件给用户
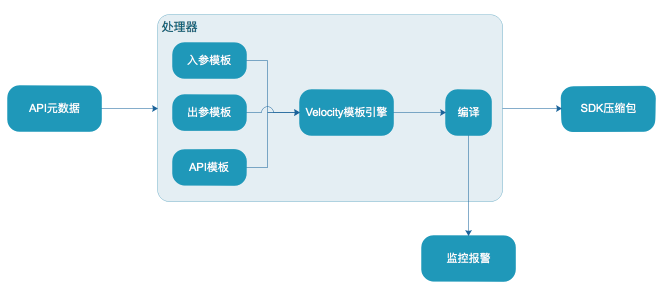
- 自动化SDK生成:对于开发者来说,接入一个平台必然少不了SDK,我们针对多语言做了自动化SDK生成,当用户的接口发布成功后,我们会监听到有新的接口,这时会触发自动编译(Java)SDK的模块,将新接口打包成新版本的压缩包,供开发者使用;如果编译失败(Java)则不会替换老的压缩包,我们会发送报警给相应的开发者,让其调整不规范的地方
4. 数据统计
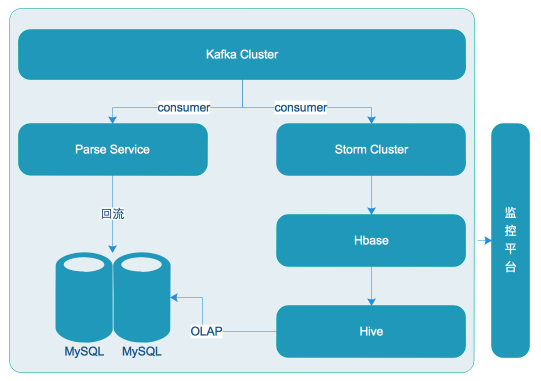
为了让业务方能在上线后了解自己的接口的运行状况,我们做了API相关的统计。我们通过在核心模块里面打日志,利用rsyslog采集数据到Kafka,然后从Kafka消费进行统计,之后回流到数据库供在线查询
除此之外,我们为每个商家做了他们授权的服务商调用接口的统计。这块功能的实现,我们通过Storm从Kafka实时消费,并实时统计落HBase,每天凌晨将前一天的数据同步到Hive进行统计并回流到数据库
5. 报警监控
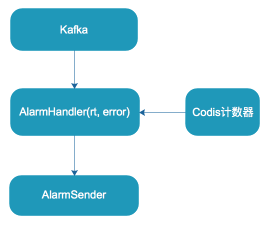
业务方API上线后,除了查看统计外,当API出问题时,还需要及时发现。我们针对这块做了API报警功能。用户在平台配置自己的API的报警,这里我们主要支持基于错误数或RT维度的报警。
我们实时地从Kafka消费API调用日志,如果发现某个API的RT或者错误次数超过配置的报警阈值,则会立即触发报警
四、实践总结
1. 规范
在网关上暴露的API很多,如何让这些API按照统一的标准对外暴露,让开发者能够低门槛快速接入是网关需要思考的问题
网关规范主要是对API的命名、入参(公用入参、业务入参)、内部服务返回值、错误码(公用错误码、业务错误码)、出参(公用出参、业务出参),进行规范
在我们的实践过程中,总结了以下规范:
- 命名规范:youzan.[业务线(可选)].[应用名].[动作].[版本],例如:youzan.item.create.3.0.0
- 入参规范:要求全部小写,组合单词以下划线分隔,例如:title, item_id;入参如果是一个结构体,要求以json字符串传入,并且json中的key必须小写并且以下划线分隔
- 出参规范:要求全部小写,组合单词以下划线分隔,例如:page_num, total_count;如果参数为结构体,结构体里面的key必须小写且以下划线分隔
- 错误码规范:我们做了统一的错误码,例如系统级错误码51xxx,业务错误码50000,详情信息由msg显示;业务级错误码由业务方自行定义,同时约束每个业务方的错误码范围
- 服务返回值规范:针对不同的业务方,每个API可能会有不同的业务错误,我们需要将这部分业务级错误展示给开发者,因此我们约定返回值需要按照一个POJO类型(包含code, msg, data)来返回,对于code为200,我们认为正常返回,否则认为是业务错误,将返回值包装为错误结果
2. 发布
- 我们将API划分到3个环境,分别为测试环境、预发环境、生产环境。API的创建、编辑必须在测试环境进行,测试完成后,可以将API发布到预发环境,之后再从预发环境发布到生产环境,这样可以保持三个环境的API数据一致。好处是:一方面可以让测试开发能在测试环境进行自动化验证,另一方面可以防止用户直接编辑线上接口引发故障
3. 工具化
- 对于内部用户经常可能需要排查问题,例如OAuth Token里面带的参数,需要经常查询,我们提供工具化的控制台,能让用户方便查询,从而减少答疑量
- 我们上线后也曾经出现过缓存不一致的情况,为了能快速排查问题,我们做了缓存管理工具,能在图形化界面上查看本地缓存以及Codis的缓存,可以进行对比找出差异
- 为了更好的排查线上问题,我们接入了有赞对比引擎(Replay)平台,该平台能将线上的流量引到预发,帮助开发者更快定位问题
五、踩过的坑
-
Meta区Full GC导致服务无法响应
现象:应用hung死,调用接口返回503,无法服务
排查过程:现场dump了内存,GC记录,以及线程运行快照。首先看了GC发现是Full GC,但是不清楚是哪里发生的,看线程运行快照也没发现什么问题。于是在本地用HeapAnalysis分析,堆区没看出什么问题,大对象都是应该占用的;于是查看方法区,通过ClassLoader Analysis发现Fastjson相关的类较多,因此怀疑是class泄露,进一步通过MAT的OQL语法分析,发现是Fastjson在序列化Jetty容器的HttpServletRequest时,为了加快速度于是创建新的类时抛了异常,导致动态创建的类在方法区堆积从而引发Full GC,后续我们也向Fastjson提了相关bug
解决方案:将序列化HttpServletRequest的代码移除
-
伪死循环导致CPU 100%
现象:在有赞双11全链路压测期间,某个业务调用API,导致我们的应用CPU几乎接近100%
排查过程:经过日志分析,发现该接口存在大量超时,但是从代码没看出特别有问题的地方。于是我们将接口在QA环境模拟调用,用VisualVM连上去,通过抽样器抽样CPU,发现某个方法消耗CPU较高,因此我们迅速定位到源码,发现这段代码主要是执行轮询任务是否完成,如果完成则调用完成回调,如果未完成继续放到队列。再结合之前的环境观察发现大量超时的任务被放到队列,导致任务被取出后,任务仍然是未完成状态,这样会将任务放回队列,这样其实构成了一个死循环
解决方案:将主动轮询改为异步通知,我们这里是Dubbo调用,Dubbo调用返回的Future实际是一个FutureAdapter,可以获取到里面的ResponseFuture(DefaultFuture),这个类型的Future支持设置Callback,任务完成时会通知到设置的回调
六、未来展望
- 业务级资源组隔离。随着业务的不断发展,当业务线较多时,可以将重要的业务分配到更优质的资源组(例如:机器性能、线程池的大小),将一般业务放到普通资源组,这样可以更好的服务不同的业务场景
- 更高并发的线程池/IO的优化。随着业务的发展,未来可能会出现更高的并发,需要更精良的线程及IO模型
- 更多的协议支持。以后技术的发展,Http2可能会蓬勃发展,这时需要接入Http2的协议
七、结语
有赞网关目前归属有赞共享技术-基础服务中心团队开发和维护;
该团队目前主要分为商品中心、库存中心、物流中心、消息沟通平台、云生态5个小组;
商品/库存/物流中心:通过不断抽象上层业务,完成通用的模型建设;为上层业务方提供高可用的服务,并快速响应多变的业务需求;针对秒杀、洪峰调用、及上层业务多变等需求,三个小组还齐力开发和持续完善着 对比引擎、服务熔断、热点探测等三个通用系统;
消息沟通平台:提供几乎一切消息沟通相关的能力及一套帮助商家与用户联系的多客服系统,每天承载着上亿次调用(短信、apppush、语音、微信、微博、多客服、邮件等通道);
云生态:承担着核心网关的建设和发展(上面的网关应用系统)、三方推送系统、有赞云后台、商业化订购以及App Engine的预研和开发;
目前该团队HC开放,期待有机会与各位共事;(内推邮箱:huangtao@youzan.com)
注,本文作者:有赞网关(黄涛、尹铁夫、叮咚)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号