后端线上服务监控与报警方案
后端线上服务监控与报警方案_阿烈叔随笔 https://www.baidufe.com/item/31bf1bb1eb562535c961.html
一、背景
1、上线期间服务稳定性观察较困难
一个功能上线后,其实研发心里根本没底儿,不知道这个功能上线以后是不是真的没问题;有经验一些老同学还知道直接登录线上机器去tail -f php.error.log,但是对于新同学来说,基本就只能等着被通知服务故障。
退一步说,即便是能去线上去tail -f查看错误日志,但是线上是多集群部署的,服务器都特别多,研发不可能在每一台机器上都能看到日志;即便是有日志收集机器,也得在各个集群下分别tail -f,定位问题很不方便!
再退一步说,即便是在线上机器看到了php错误日志,也并没有足够多的信息辅助信息能够迅速定位出来,怎样的一次访问请求,导致了这个错误。因为php记录的日志一般都是这个格式:
[22-Oct-2015 18:39:04 Asia/Shanghai] PHP Fatal error: Call to a member function prepare() on null in /home/work/phplib/db/Database.class.php on line 2382、平时线上服务稳定性无法察觉
真正线上出问题较多的,其实还是系统运行过程中;比如流量突然增加导致接口处理出错、所依赖的第三方服务宕掉导致的程序错误、网络原因导致接口不能正常工作,等等。因为平时系统运行中,大家不会有专门的人去线上日志机器一直tail -f进行观察,效率低,且不现实。
3、接口性能问题无人关注
一个接口,可能因为产品上的各种原因,研发会不停地往上面打补丁进行实现,很多情况下,会因为功能上线比较紧张,所以实现过程中忽略了接口性能。在一段时间内,一个接口的响应时间从100ms上升到300ms,接口可用性从99.99下降到90.00;也许在正常情况下,我们不会感知到逐渐改造后的接口对线上造成了什么影响,但其实不然,接口SLA非常重要!可是,这些信息我们通过什么样的方式才能得知呢,真正能提供这些信息的同学,并不多!
4、谁来跟进已发现的问题
还有一些情况是,线上出了问题,且其他组的同学帮助定位到大致的问题范围,抛到研发群以后,没人主动响应;大家都会觉得我没改过这个东西,所以忽略了;于是一个线上问题就只能等着Leader来安排跟进,否则就石沉大海,长期影响用户使用。
综上,我们必须要有一套自动化的线上服务监控和预警方案,主动发现,及时跟进!
二、监控范围
为了能对线上服务状况了如指掌,我们需要监控的内容一定得是很全的,但一开始得有一个重点监控的范围,也是平时最容易出问题的地方:
- 编码粗心导致的PHP Syntax/Parse Error
- 程序代码中的PHP Fatal Error
- 程序代码中的PHP Warning
- 数据库访问导致的DB Error/Timeout等
- 缓存系统Redis相关的错误
- 缓存系统Memcache相关的错误
- 线上接口的可用性监控
- 线上接口的响应时间监控
三、实现方案【如何:采】
1、PHP相关错误监控
包括语法错误、以及运行期间的Fatal、Warning等,都可以借助PHP提供的register_sutdown_function和set_error_handler组合的形式来实现:
/**
* 统一截获并处理错误
* @return bool
*/
public static function registErrorHandler() {
$e_types = array (
E_ERROR => 'PHP Fatal',
E_WARNING => 'PHP Warning',
E_PARSE => 'PHP Parse Error',
E_NOTICE => 'PHP Notice'
);
register_shutdown_function(function () use ($e_types) {
$error = error_get_last();
if ($error['type'] != E_NOTICE && !empty($error['message'])) {
$error['trace'] = self::getStackTrace();
self::error_handler($error);
}
});
set_error_handler(function ($type, $message, $file, $line) use ($e_types) {
if ($type != E_NOTICE && !empty($message)) {
$error = array (
'type' => $type,
'message' => $message,
'file' => $file,
'line' => $line,
'trace' => self::getStackTrace()
);
self::error_handler($error);
// 被截获的错误,重新输出到错误文件
error_log(($e_types[$type] ?: 'Unknown Problem') . ' : ' . $message . ' in ' . $file . ' on line ' . $line . "\n");
}
}, E_ALL);
}当然,这个需要在程序的入口处进行注册,保证每一次的程序执行,都能成功捕获错误:
// 全局异常捕获
MonitorManager::registErrorHandler();通过这个方式,我们在业务层就能完全捕获接口执行过程中的任意错误。
2、DB、Memcache、Redis相关错误的监控
在各个SDK内部,将执行过程中的异常都向上抛出(throw new Exception),内容尽可能详细,包括:
- DB错误
- 具体的SQL
- 具体的DB、Table
- 错误栈
- 对应的接口名称
- 服务器IP
- Memcache、Redis错误
- 具体错误号(内容)
- 出错的Memcache Key
- 错误栈
- 对应的接口名称
- 服务器IP
同时,我们通过一个统一工具方法进行收集错误日志,下面说如何收集。
四、实现方案【如何:集】
所有的错误不采取直接上报,因为这必然会直接影响当前接口的性能,所以采取队列方式进行收集,即:业务层或SDK中有错误产生时,统一通过一个工具方法进行收集,收集之后,将该错误内容直接入队列,另外开启一个队列实时消耗进程,将队列中的错误日志数据上报到服务器进行处理。
1、日志收集的工具方法
/**
* 添加监控日志,日志会被异步收集到日志平台进行展示
*
* @param $type
* @param $content
*/
public static function collect($type, $content) {
// 线上集群,并且开关处于打开状态,才进行收集
if (Utilities::isOnlineCluster() && SwitchManager::getSwitch('collect', SwitchManager::SWITCH_MONITOR)) {
// 检查当前这种监控类型是否支持
if (self::support($type) && !self::checkWhiteList($type, $content)) {
self::queueInstance()->enQueue(json_encode(array (
'type' => $type,
'data' => $content,
'cluster' => Utilities::getClusterName(),
'reqtime' => isset($_SERVER['REQUEST_TIME']) ? $_SERVER['REQUEST_TIME'] : time(),
'extinfo' => array (
'domain' => $_SERVER['SERVER_NAME'],
'path' => isset($_SERVER['QUERY_STRING']) ? str_replace('?' . $_SERVER['QUERY_STRING'], '', $_SERVER['REQUEST_URI']) : 'script',
'userAgent' => isset($_SERVER['HTTP_USER_AGENT']) ? $_SERVER['HTTP_USER_AGENT'] : '',
'referer' => isset($_SERVER['HTTP_REFERER']) ? $_SERVER['HTTP_REFERER'] : '',
'serverIp' => Utilities::getServerPhpIP(),
'reqData' => json_encode($_REQUEST, true)
)
), true));
}
}
}从上面的方法可看出,除了具体的错误日志,我们还一并收集了一些非常重要的辅助信息,比如当前集群、出问题的域名、对应接口、userAgent、请求参数、接口从哪儿来的等等。
2、队列实时消耗脚本
<?php
namespace Mlservice\Script\Monitor;
use Framework\Libs\Monitor\MonitorManager;
use Framework\Libs\Util\Utilities;
/**
* 从MC队列中,将各种错误日志上报到日志平台进行汇总监控、报警等
* Class Collect
* @package Mlservice\Script\Monitor
* @author xianliezhao
*/
class Collect extends \Framework\FrameworkScript {
private $limit = 5;
private $interval = 600;
public function run() {
// 检查脚本可执行
$this->checkCluster();
$start = time();
while (true) {
$index = 0;
$params = array ();
while (true) {
$index++;
$item = MonitorManager::queueInstance()->deQueue();
if (!empty($item)) {
$params[] = $item;
} else {
// 如果数据为空,则10分钟清理一次队列,做一次初始化,且自杀进程
if (time() - $start > $this->interval) {
MonitorManager::queueInstance()->makeEmpty();
exit(0);
}
break;
}
if ($index >= $this->limit) {
break;
}
}
// 发送到服务器,统一收集
if (!empty($params)) {
Utilities::apiRequest('bizfe', 'feapi/monitor/mon/collect', $params);
} else {
sleep(1);
}
}
}
}队列消耗机制做的很简单,不需要采集到所有的错误,只要保证线上有错误了,我们能第一时间得知,即可。 日志每最多收集满5条就上报一次,通过HTTP请求方式,上报到bizfe::/feapi/monitor/mon/collect 。
五、实现方案【如何:处理】
1、数据采用MongoDB存储
对于这种内容和结构灵活多变的数据,采用MongoDB存储再合适不过了,只需要定义一个简单的一级表结构即可:
/**
* 错误日志采集的表结构
* @type {*|Model}
*/
var monModel = connection.model('monitor', new Schema({
type: String,
cluster: String,
product: String,
data: Object,
extinfo: Object,
reqtime: Number
}, {
autoIndex: true
}));2、数据保存策略
/**
* 对数据进行加工,然后保存日志到db,批量保存成功以后再进行报警检测
* @param messageModel
*/
function save(messageModel) {
return function (reqParams, callback) {
var params = [];
for (var i in reqParams) {
var item = JSON.parse(reqParams[i]);
// 忽略来自标准环境的任何错误
if (item.extinfo.domain.indexOf('rdlab') > 0) {
continue;
}
// 从域名中记录下出问题的模块名称
item.product = item.extinfo.domain.split('\.')[0];
item = cleanParams(messageModel, item);
params.push(item);
}
var count = params.length;
if (count == 0) {
callback();
}
var saveData = [];
var done = 0;
// 批量保存
params.forEach(function (item) {
new messageModel(item).save(function (err, product, effectRows) {
!err && (item._id = product._id);
saveData.push(item);
if (++done == count) {
// 当所有的错误日志都进入db成功以后,开始进行报警检测(内存中会维护一个错误池)
alarm.addAndCheckPool(saveData);
if (err) {
callback(err, null);
} else {
callback(null, {error_code: 0, data: {}});
}
}
});
});
};
}3、报警检测机制
通过alarm.addAndCheckPool会在内存中维护一个日志错误池,只需要开启一个子进程每秒检测错误池中的数据,进行阈值检测即可。
/**
* 每秒检测一次,各个错误类型只要达到邮件或者短信的最大阈值,则进行报警
*/
var doAlarm = function () {
var INTERVAL_TIME = 1000;
// 启用监控
if (!alarmListenIng) {
alarmListenIng = true;
} else {
return false;
}
setInterval(function () {
// 遍历所有类型,判断是否进行报警
Object.keys(cachePool).forEach(function (type) {
// 当前时间
var nowTime = (new Date()).getTime();
// 控制每分钟最多只能报警N次
var alarmCount = cachePool[type]['alarmCount'];
if (alarmCount === undefined) {
initCacheByType(type, 1);
} else {
var lastMtime = cachePool[type]['lastMtime'];
if ((nowTime - lastMtime) / 1000 > 60) {
// 超过1分钟,直接进行数据重新初始化
initCacheByType(type, 1);
} else if (alarmCount >= cachePool[type]['alarmCpm']) {
// 如果每分钟的报警次数超过阈值,就不报警了
return false;
}
}
// 控制每N秒内报警一次
var lastAlarmTime = cachePool[type]['lastAlarmTime'];
if (lastAlarmTime === undefined) {
cachePool[type]['lastAlarmTime'] = nowTime;
} else if (Math.ceil((nowTime - lastAlarmTime) / 1000) >= cachePool[type]['timeInterval']) {
cachePool[type]['lastAlarmTime'] = nowTime;
// 这种情况下,才表明需要报警
if (cachePool[type]['alarms'] && cachePool[type]['alarms']['total'] >= cachePool[type]['maxNumForMail']) {
cachePool[type]['type'] = type;
cachePool[type]['alarmCount'] += 1;
var theAlarmData = cachePool[type];
theAlarmData.theTime = Math.ceil((nowTime - lastAlarmTime) / 1000) || 1;
// 邮件报警
sendEmail(buildEmailAlarmContent(theAlarmData));
// 如果是出错量比设定的短信阈值还大,则短信报警
if (cachePool[type]['maxNumForSms'] <= cachePool[type]['alarms']['total']) {
sendSmsMessage(buildSmsAlarmContent(theAlarmData));
}
// 清空
initCacheByType(type, 0);
}
}
});
}, INTERVAL_TIME);
};当然,各种错误的不同阈值为了日后的维护,也抽离成配置单独管理,更为合适:
/**
* 报警阈值设定
*/
alarmLimits: {
db_log: {
timeInterval: 3, // 每隔3s监控一次
maxNumForMail: 10, // 邮件报警阈值
maxNumForSms: 50, // 短信报警阈值
alarmCpm: 5 // 表示每分钟最多报警5次
},
redis_log: {
timeInterval: 3,
maxNumForMail: 10,
maxNumForSms: 50,
alarmCpm: 5
},
mc_log: {
timeInterval: 3,
maxNumForMail: 5,
maxNumForSms: 20,
alarmCpm: 5
},
mq_error: {
timeInterval: 3,
maxNumForMail: 10,
maxNumForSms: 30,
alarmCpm: 5
},
php_error: {
timeInterval: 3,
maxNumForMail: 5,
maxNumForSms: 20,
alarmCpm: 5
},
php_warning: {
timeInterval: 3,
maxNumForMail: 10,
maxNumForSms: 50,
alarmCpm: 5
}
}六、接收报警
按照这套流程下来,线上只要出任何错误,都会被实时上报到日志服务器,以php_error为例,每隔3秒检测一次,如果累积出现5次错误,则采取邮件方式进行报警,如果累积出现20次错误,则可理解为错误较严重,进行短信报警!
对于不同类型的错误报警,会发送给不同的接收人,抄送给大组,保证该次报警一定不会被忽略。同时提供一个Web平台,对日志进行分析展现,可查询某个错误的详细信息,快速分析出问题出现在什么地方;一般情况下,通过该平台的日志详情页,可以一眼就判断出来该错误应该采取什么方式去修复。
七、接口可用性与响应时间监控
1、数据来源分析
这部分的数据,可以直接从Nginx日志中进行提取,首先,我们可以来看看一条完整的Nginx日志包含的内容:
[x.x.x.x] [-] [23/Oct/2015:14:59:59 +0800] [GET /goods/goods_info?goods_id=276096349&fields=platform_type%2Cgoods_id%2Cgoods_param%2Cgoods_detail%2Cshop_id%2Cfirst_sort_id%2Csize%2Cgoods_desc HTTP/1.1] [200] [1957] [xxx.com/share/goods_details] [Snake Connect] [-] [0.010] [y.y.y.y:9999] [0.010] [-] [uid:0;ip:0.0.0.0;v:0;master:0;is_mob:0]基本就是这个格式:
[$remote_addr] [$remote_user] [$time_local] [$request] [$status] [$body_bytes_sent] [$http_referer] [$http_user_agent] [$http_user_agent] [$http_x_forwarded_for] [$request_time] [$upstream_addr] [$upstream_response_time] [$request_body]当然,Nginx日志收集的格式,是可以在Nginx配置文件中进行自定义的,具体看业务层需要怎么分析。
基于上面已经产生的这个日志,我们可以通过这几个数据来做接口性能监控:
$request具体的接口名称$status该请求对应的执行状态(200:成功;499:超时;502:服务挂了;500:可能是有Fatal...),通过这个信息来衡量接口的可用性$request_time一个接口的完整执行时间,通过这个值来衡量接口的响应时间
2、监控对象以及数据采集
对于需要监控的对象,可以通过白名单的方式,指定对某些接口进行监控,但是这样不够灵活,尤其是一个服务下的接口在不断增加,经常更新监控的接口列表,维护成本较高。
还有比较智能的方法,就是根据某个接口的访问量,取前N个进行监控,比如可以通过这样的方式来获取监控接口列表:
# 日期
date_time=$(date -d "-1 hours" "+%Y%m%d%H")
# 文件位置
file_name="/home/service/nginx/log/xxx.mlservice.access.${date_time}.log"
# 获取监控列表
api_list=$(awk '{print $6}' ${file_name} | grep -v 'your_filter_api_here' | sed -e "s/\?.*//" -e "s/^\///" | tr '[A-Z]' '[a-z]' | sort | uniq -c | sort -nr | head -n 20 | awk '{print $2}') ;这里的api_list就是是动态获取到的监控对象了,结果形如:
goods/goods_info
goods/campaign_info
inventory/get_skuinfo
inventory/set_inventory
campaign/update_campaign
campaign/goods_info
inventory/spu_set
inventory/inventory_decr
...对于数据的采集,就可以直接通过上面的监控对象,利用grep提取所有相关的数据,然后通过awk逐条进行分析,最终得出平均值,输出结果。而对数据结果的上报,直接通过curl方式发送到bizfe平台进行统一存储以及集中展现。
3、几张效果图片
1)、报警邮件

2)、平台中展现所有监控日志
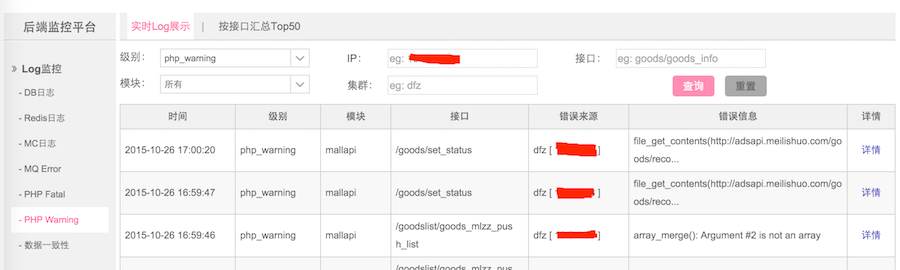
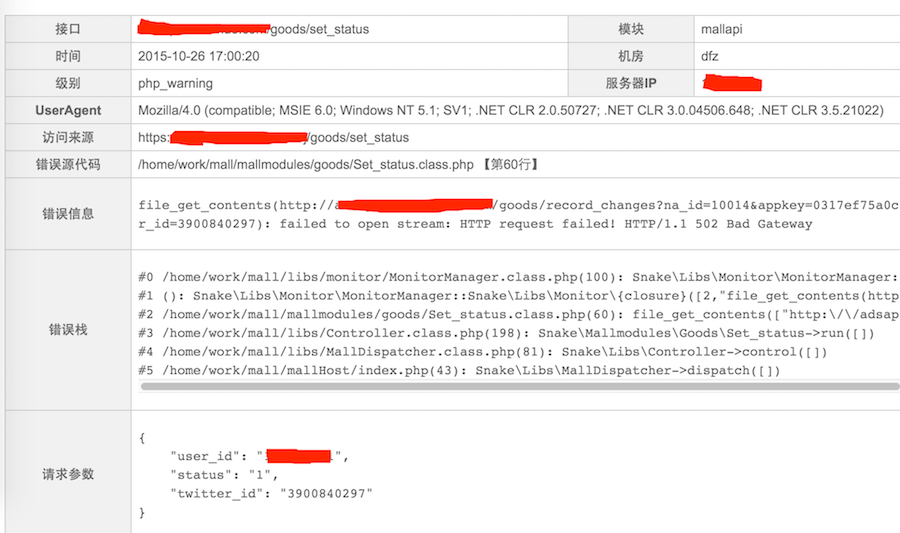
3)、错误详情
4)、平台中展现接口性能

八、结语
线上服务出现任何问题,作为一线研发,都应该第一时间知道出了什么问题、问题出在哪儿、大致的影响范围是什么、大致如何修复等。绝对不是等着用户来反馈了,我们才被动的去找用户报的问题,如何复现?!
当然,我们也不能成为监控报警的重度患者,凡事也得有个度,如果线上不管是什么样的log都通过报警的方式发出来,就真成了扰民了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号