数据库html 数据的分句
Python 中文分句 - CSDN博客 https://blog.csdn.net/laoyaotask/article/details/9260263
# 设置分句的标志符号;可以根据实际需要进行修改
#cutlist = "。!?".decode('utf-8')
cutlist = ['\n', '\t', '。', ';', '?', '.', ';', '?', '...', '、、、',':']
cutlist = [ '。', ';', '?', '.', ';', '?', '...', '、、、',':',':',',']
# 检查某字符是否分句标志符号的函数;如果是,返回True,否则返回False
def FindToken(cutlist, char):
if char in cutlist:
return True
else:
return False
# 进行分句的核心函数
def Cut(cutlist, lines): # 参数1:引用分句标志符;参数2:被分句的文本,为一行中文字符
l = [] # 句子列表,用于存储单个分句成功后的整句内容,为函数的返回值
line = [] # 临时列表,用于存储捕获到分句标志符之前的每个字符,一旦发现分句符号后,就会将其内容全部赋给l,然后就会被清空
for i in lines: # 对函数参数2中的每一字符逐个进行检查 (本函数中,如果将if和else对换一下位置,会更好懂)
if FindToken(cutlist, i): # 如果当前字符是分句符号
line.append(i) # 将此字符放入临时列表中
l.append(''.join(line)) # 并把当前临时列表的内容加入到句子列表中
line = [] # 将符号列表清空,以便下次分句使用
else: # 如果当前字符不是分句符号,则将该字符直接放入临时列表中
line.append(i)
return l
r_s=[]
# 以下为调用上述函数实现从文本文件中读取内容并进行分句。
with open('tmp.txt','r',encoding='utf-8') as fr :
for lines in fr:
l = Cut(list(cutlist), list(lines))
for line in l:
if line.strip() != "":
line=line.strip()
r_s.append(line)
# li = line.strip().split()
# for sentence in li:
# r_s.append(sentence)
dd=9
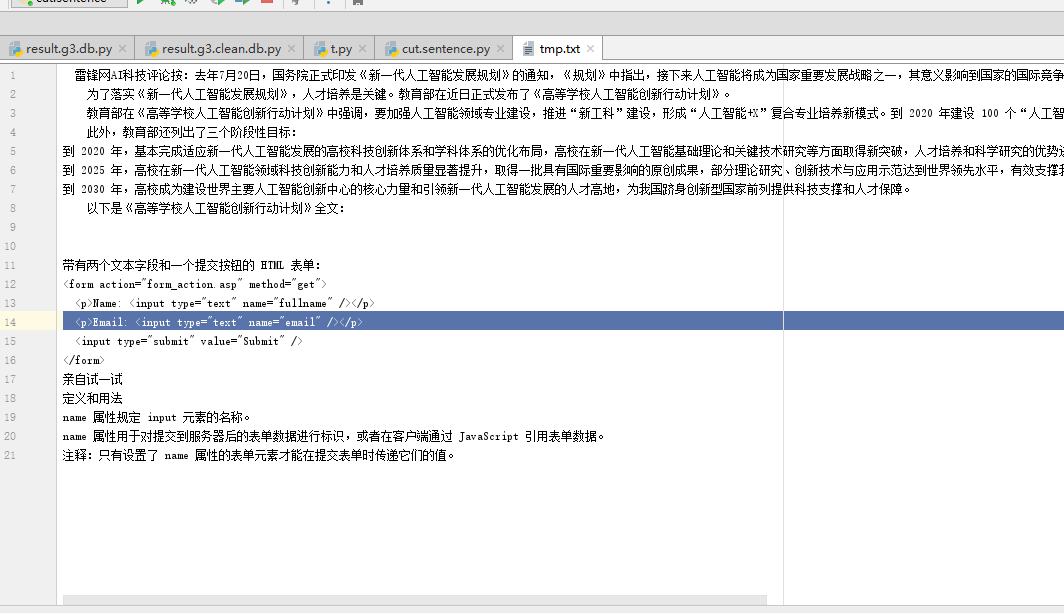
雷锋网AI科技评论按:去年7月20日,国务院正式印发《新一代人工智能发展规划》的通知,《规划》中指出,接下来人工智能将成为国家重要发展战略之一,其意义影响到国家的国际竞争力、经济发展、社会建设等等大方向。 为了落实《新一代人工智能发展规划》,人才培养是关键。教育部在近日正式发布了《高等学校人工智能创新行动计划》。 教育部在《高等学校人工智能创新行动计划》中强调,要加强人工智能领域专业建设,推进“新工科”建设,形成“人工智能+X”复合专业培养新模式。到 2020 年建设 100 个“人工智能+X”复合特色专业,推动重要方向的教材和在线开放课程建设。到 2020 年编写 50 本具有国际一流水平的本科生和研究生教材、建设 50 门人工智能领域国家级精品在线开放课程、建立 50 家人工智能学院、研究院或交叉研究中心,并引导高校通过增量支持和存量调整,加大人工智能领域人才培养力度。在职业院校大数据、信息管理相关专业中增加人工智能相关内容,培养人工智能应用领域技术技能人才。 此外,教育部还列出了三个阶段性目标: 到 2020 年,基本完成适应新一代人工智能发展的高校科技创新体系和学科体系的优化布局,高校在新一代人工智能基础理论和关键技术研究等方面取得新突破,人才培养和科学研究的优势进一步提升,并推动人工智能技术广泛应用。 到 2025 年,高校在新一代人工智能领域科技创新能力和人才培养质量显著提升,取得一批具有国际重要影响的原创成果,部分理论研究、创新技术与应用示范达到世界领先水平,有效支撑我国产业升级、经济转型和智能社会建设。 到 2030 年,高校成为建设世界主要人工智能创新中心的核心力量和引领新一代人工智能发展的人才高地,为我国跻身创新型国家前列提供科技支撑和人才保障。 以下是《高等学校人工智能创新行动计划》全文: 带有两个文本字段和一个提交按钮的 HTML 表单: <form action="form_action.asp" method="get"> <p>Name: <input type="text" name="fullname" /></p> <p>Email: <input type="text" name="email" /></p> <input type="submit" value="Submit" /> </form> 亲自试一试 定义和用法 name 属性规定 input 元素的名称。 name 属性用于对提交到服务器后的表单数据进行标识,或者在客户端通过 JavaScript 引用表单数据。 注释:只有设置了 name 属性的表单元素才能在提交表单时传递它们的值。
# 设置分句的标志符号;可以根据实际需要进行修改
#cutlist = "。!?".decode('utf-8')
cutlist = ['\n', '\t', '。', ';', '?', '.', ';', '?', '...', '、、、',':']
cutlist = [ '。', ';', '?', '.', ';', '?', '...', '、、、',':',':',',']
# 检查某字符是否分句标志符号的函数;如果是,返回True,否则返回False
def FindToken(cutlist, char):
if char in cutlist:
return True
else:
return False
# 进行分句的核心函数
def Cut(cutlist, lines): # 参数1:引用分句标志符;参数2:被分句的文本,为一行中文字符
l = [] # 句子列表,用于存储单个分句成功后的整句内容,为函数的返回值
line = [] # 临时列表,用于存储捕获到分句标志符之前的每个字符,一旦发现分句符号后,就会将其内容全部赋给l,然后就会被清空
for i in lines: # 对函数参数2中的每一字符逐个进行检查 (本函数中,如果将if和else对换一下位置,会更好懂)
if FindToken(cutlist, i): # 如果当前字符是分句符号
line.append(i) # 将此字符放入临时列表中
l.append(''.join(line)) # 并把当前临时列表的内容加入到句子列表中
line = [] # 将符号列表清空,以便下次分句使用
else: # 如果当前字符不是分句符号,则将该字符直接放入临时列表中
line.append(i)
return l
r_s=[]
# 以下为调用上述函数实现从文本文件中读取内容并进行分句。
with open('tmp.txt','r',encoding='utf-8') as fr :
for lines in fr:
l = Cut(list(cutlist), list(lines))
for line in l:
if line.strip() != "":
line=line.strip()
r_s.append(line)
# li = line.strip().split()
# for sentence in li:
# r_s.append(sentence)
str_=''
# cutlist = [ '。', ';', '?', '.', ';', '?', '...', '、、、',':',':',',','\n']
with open('tmp.txt','r',encoding='utf-8') as fr :
for lines in fr:
str_='{}{}'.format(str_,lines.replace('\n',''))
# l = Cut(list(cutlist), list(lines))
# for line in l:
# if line.strip() != "":
# line=line.strip()
# r_s.append(line)
dd=9
数据库html 数据的分句

'''
SELECT * FROM Info_Roles WHERE Flag=1 LIMIT 2;
select top y * from 表 where 主键 not in(select top (x-1)*y 主键 from 表)
如果表中无主键,可以用临时表,加标识字段解决.这里的x,y可以用变量.
select id=identity(int,1,1),* into #tb from 表
select * from #tb where id between (x-1)*y and x*y-1
select top 1000 Info_ID from Info_Roles
select top 2000 Info_ID,',xiaole20180410SPLIT,',content from Info_Content where Info_ID not in( select top 1000 Info_ID from Info_Roles ) ;
select top 399 Info_ID,',xiaole20180410SPLIT,',UPPER(content) from Info_Content ;
select top 399 CHARINDEX('IMG',UPPER(content)) from Info_Content ;
select top 15 Info_ID,',xiaole20180410SPLIT,',content from Info_Content where CHARINDEX('IMG',UPPER(content))>0;
select top 15 Info_ID,',xiaole20180410SPLIT,',content from Info_Content where
Info_ID in( select top 1000 Info_ID from Info_Roles ) and
CHARINDEX('IMG',UPPER(content))>0
;
SELECT
TOP 15 Info_ID,
',xiaole20180410SPLIT,',
content
FROM
Info_Content
WHERE
Info_ID IN (
SELECT
TOP 1000 Info_ID
FROM
Info_Roles
WHERE
Flag = 1
)
AND CHARINDEX('IMG', UPPER(content)) > 0;
SELECT
TOP 200 Info_ID,
',xiaole20180410SPLIT,',
content
FROM
Info_Content
WHERE
Info_ID IN (
SELECT
TOP 90000 Info_ID
FROM
Info_Roles
)
AND CHARINDEX('<IMG', UPPER(content)) > 0;
'''
from bs4 import BeautifulSoup
from selenium import webdriver
xlsplit_str = ',xiaole20180410SPLIT,'
f_db_txt, uid_d = 'db.uid.para.txt', {}
with open(f_db_txt, 'r', encoding='utf-8') as fr:
for i in fr:
i = i.replace('\t', '').replace('\n', '')
if xlsplit_str in i:
l = i.split(xlsplit_str)
uid = l[0].replace(' ', '')
uid_d[uid] = {}
uid_d[uid]['html'] = []
uid_d[uid]['html'].append(l[1])
else:
uid_d[uid]['html'].append(i)
r_d = {}
'''
中文分句
'''
cutlist = [ '。', ';', '?', '.', ';', '?', '...', '、、、',':',':',',',',']
# 检查某字符是否分句标志符号的函数;如果是,返回True,否则返回False
def FindToken(cutlist, char):
if char in cutlist:
return True
else:
return False
# 进行分句的核心函数
def Cut(cutlist, lines): # 参数1:引用分句标志符;参数2:被分句的文本,为一行中文字符
l = [] # 句子列表,用于存储单个分句成功后的整句内容,为函数的返回值
line = [] # 临时列表,用于存储捕获到分句标志符之前的每个字符,一旦发现分句符号后,就会将其内容全部赋给l,然后就会被清空
for i in lines: # 对函数参数2中的每一字符逐个进行检查 (本函数中,如果将if和else对换一下位置,会更好懂)
if FindToken(cutlist, i): # 如果当前字符是分句符号
line.append(i) # 将此字符放入临时列表中
l.append(''.join(line)) # 并把当前临时列表的内容加入到句子列表中
line = [] # 将符号列表清空,以便下次分句使用
else: # 如果当前字符不是分句符号,则将该字符直接放入临时列表中
line.append(i)
return l
'''
'''
def paragraph_to_sentence(paragraph, sentence_l):
paragraph = paragraph.replace(' ', '')
sentence_split_l = ['\n', '\t', '。', ';', '?', '.', ';', '?', '...', '、、、', ',', ',']
for i in sentence_split_l:
ll = paragraph.split(i)
sentence_l.append(ll[0])
if len(ll) > 1:
paragraph_to_sentence(ll[1], sentence_l)
else:
break
return sentence_l
def paragraph_to_sentence_no_recursion(paragraph, sentence_l):
paragraph = paragraph.replace(' ', '')
sentence_split_l = ['\n', '\t', '。', ';', '?', '.', ';', '?', '...', '、、、', ',', ',']
for i in sentence_split_l:
ll = paragraph.split(i)
sentence_l.append(ll[0])
if len(ll) > 1:
paragraph_to_sentence(ll[1], sentence_l)
else:
break
return sentence_l
paragraph=''
sentence_l=[]
paragraph = paragraph.replace(' ', '')
sentence_split_l = ['\n', '\t', '。', ';', '?', '.', ';', '?', '...', '、、、', ',', ',']
for i in sentence_split_l:
ll = paragraph.split(i)
sentence_l.append(ll[0])
if len(ll) > 1:
paragraph_to_sentence(ll[1], sentence_l)
else:
break
def sentence_l_to_sentence_l_l(sentence_l):
sentence_l_l = []
sentence_split_l = ['\n', '\t', '。', ';', '?', '.', ';', '?', '...', '、、、', ',', ',']
for i in sentence_l:
for ii in sentence_split_l:
ll = i.split(ii)
if len(ll) > 1:
sentence_l_l += ll
else:
sentence_l_l.append(i)
continue
return sentence_l_l
import requests, time, threading
img_dir = 'C:\\Users\\sas\\PycharmProjects\\py_win_to_unix\\crontab_chk_url\\personas\\trunk\\plugins\\spider\\dl_img_tmp\\'
img_dir = 'C:\\Users\\sas\\PycharmProjects\\produce_video\\mypng\\'
# http://www.lky365.com/editor/uploadfile/20090508144220411.jpg
# C:\Users\sas\PycharmProjects\produce_video\mypng
def spider_webimg_dl_return_local_img_path(img_dir, img_url, uid, local_default='default.DONOT_REMOVE.png'):
r = '%s%s' % (img_dir, local_default)
try:
bytes = requests.get(img_url)._content
# r = '{}{}{}{}{}'.format(img_dir, time.strftime('%Y%m%d%H%M%S', time.localtime(time.time())), 'g3dbuid', uid, '.png')
r = '{}{}{}{}{}{}'.format(img_dir, 'g3db', uid, 'g3uid', img_url.split('.')[0].split('/')[-1], '.png')
# if bytes != 0:
if bytes != 0 and requests.get(img_url).status_code == 200:
with open(r, 'wb')as f:
f.write(bytes)
else:
print(img_url)
except Exception as e:
print(img_url, ',,,', uid)
print(e)
return r
from aip import AipSpeech
bd_k_l = ['11059852', '5Kk01GtG2fjCwpzEkwdn0mjw', 'bp6Wyx377Elq7RsCQZzTBgGUFzLm8G2A']
APP_ID, API_KEY, SECRET_KEY = bd_k_l
f_p, str_ = 'mybaidu.parp.b.txt', ''
with open(f_p, 'r', encoding='utf-8') as fr:
for i in fr:
ii = i.replace('\n', '')
str_ = '{}{}'.format(str_, ii)
def gen_bd_mp3(uid, str_):
mp3_dir = 'C:\\Users\\sas\\PycharmProjects\\produce_video\\mymp3\\'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis(str_, 'zh', 1, {
'vol': 5,
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
# f_w = '{}{}{}{}'.format(mp3_dir, 'g3uid', uid, '.mp3')
f_w = '{}{}{}{}{}'.format(mp3_dir, 'g3db', uid, 'g3uid', '.mp3')
# ,'g3db',uid,'g3uid'
# with open('auido.b.mp3', 'wb') as f:
with open(f_w, 'wb') as f:
f.write(result)
for uid in uid_d:
str_ = ''.join(uid_d[uid]['html'])
fhtml = 'qqzong.vedio.allinone.tmp.html'
with open(fhtml, 'w', encoding='utf-8') as fw:
fw.write(str_)
with open(fhtml, 'r', encoding='utf-8') as fo:
soup = BeautifulSoup(fo, 'html.parser')
img_l = soup.find_all('img')
if len(img_l) > 0:
l = soup.find_all('img')
uid_d[uid]['img'], uid_d[uid]['txt'] = [i.attrs['src'] for i in l], soup.text
r_d[uid] = {}
r_d[uid] = uid_d[uid]
# incr_l = ['http://www.51g3.net/templates/images/logo.jpg',
# 'http://www.51g3.net/attached/image/20171206104541_20247.jpg',
# 'http://www.51g3.net/attached/image/20171129183441_78749.png',
# 'http://www.51g3.net/templates/images/agentimg.jpg']
incr_l = []
r_d[uid]['img'] += incr_l
# r_d[uid]['sentence_l']=paragraph_to_sentence(uid_d[uid]['txt'],[])
sentence_l = paragraph_to_sentence(uid_d[uid]['txt'], [])
try:
str_ = uid_d[uid]['txt']
# gen_bd_mp3(uid, str_)
except Exception as e:
print(e)
for img_url in r_d[uid]['img']:
# spider_webimg_dl_return_local_img_path(img_dir, img_url, uid, local_default='default.DONOT_REMOVE.png')
pass
# r_d[uid]['sentence_l'] = sentence_l_to_sentence_l_l(sentence_l)
r_d[uid]['sentence_l'] = Cut(list(cutlist), list(uid_d[uid]['txt']))
else:
# print(uid)
pass
uid_l = [i for i in r_d]
import os
import os, time, glob
import cv2
os_sep = os.sep
this_file_abspath = os.path.abspath(__file__)
this_file_dirname, this_file_name = os.path.dirname(this_file_abspath), os.path.abspath(__file__).split(os_sep)[
-1]
f_img_d = '{}{}{}{}{}'.format(this_file_dirname, os_sep, 'mypng', os_sep, '*.png')
f_mp3_d = '{}{}{}{}{}'.format(this_file_dirname, os_sep, 'mymp3', os_sep, '*.mp3')
imgs, img_size_d = glob.glob(f_img_d), {}
mp3s, mp3_size_d = glob.glob(f_mp3_d), {}
for uid in r_d:
chk_str = '{}{}{}'.format('g3db', uid, 'g3uid')
r_d[uid]['img_n'],r_d[uid]['img_path'] = 0,[]
for img in imgs:
if chk_str in img:
r_d[uid]['img_n'] += 1
r_d[uid]['img_path'].append(img)
else:
pass
for mp3 in mp3s:
if chk_str in mp3:
r_d[uid]['mp3_path']=mp3
else:
pass
print('-----------------')
'''
>2
15796
16010
16065
16577
>1
15796
16010
16065
16577
16635
17923
>=1
15706
15766
15791
15796
16010
16065
16159
16509
16577
16635
16895
16915
16919
17206
17240
17622
17642
17923
18112
18207
18237
18239
18438
18701
18909
18934
18935
18937
18996
19135
19323
19589
19590
19592
'''
uid_r_l=[]
for uid in r_d:
if int(r_d[uid]['img_n'])>=1:
print(uid)
dddd = 9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号