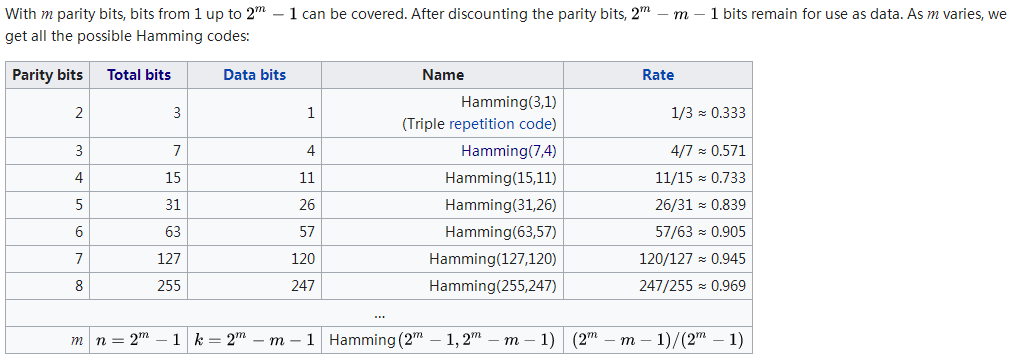
奇偶校验 汉明码 如果一条信息中包含更多用于纠错的位,且通过妥善安排这些纠错位使得不同的出错位产生不同的错误结果,那么我们就可以找出出错位了。 crc CRC 循环冗余校验
CRC(循环冗余校验)_百度百科 https://baike.baidu.com/item/CRC/1453359
循环冗余校验(Cyclic Redundancy Check, CRC)是一种根据网络数据包或计算机文件等数据产生简短固定位数校验码的一种信道编码技术,主要用来检测或校验数据传输或者保存后可能出现的错误。它是利用除法及余数的原理来作错误侦测的。
- 中文名
- 循环冗余校验
- 外文名
- Cyclic Redundancy Check
- 简 称
- CRC
- 原 理
- 除法及余数的原理来作错误侦测
- 目 的
- 确保传输的数据准确无误
- 有关术语
- 循环冗余校验码
在数据存储和数据通讯领域,为了保证数据的正确,就不得不采用检错的手段。在诸多检错手段中,CRC是最著名的一种。CRC的全称是循环冗余校验,其特点是:检错能力强,开销小,易于用编码器及检测电路实现。从其检错能力来看,它所不能发现的错误的几率仅为0.0047%以下。从性能上和开销上考虑,均远远优于奇偶校验及算术和校验等方式。因而,在数据存储和数据通讯领域,CRC无处不在:著名的通讯协议X.25的FCS(帧检错序列)采用的是CRC-CCITT,WinRAR、NERO、ARJ、LHA等压缩工具软件采用的是CRC32,磁盘驱动器的读写采用了CRC16,通用的图像存储格式GIF、TIFF等也都用CRC作为检错手段。下面介绍硬件生成与计算CRC的过程。
CRC(循环冗余校验)在线计算_ip33.com http://www.ip33.com/crc.html
zlib Home Site https://www.zlib.net/
zlib 1.2.11 Manual https://www.zlib.net/manual.html
rfc1952 https://datatracker.ietf.org/doc/html/rfc1952
parity bit
奇偶位 校验位
n 有效信息的位数
k 校验位的位数
2^k-1>=n+k
k=4 => n(Max)=11
n=4 => k(Min)=3
If a byte of data to be encoded is 10011010, then the data word (using _ to represent the parity bits) would be __1_001_1010, and the code word is 011100101010.

偶校验

海明码之编码原理和校验方法_夜风的博客-CSDN博客_海明码 https://blog.csdn.net/u014470361/article/details/79848824
The key thing about Hamming Codes that can be seen from visual inspection is that any given bit is included in a unique set of parity bits.
General algorithm[edit]
The following general algorithm generates a single-error correcting (SEC) code for any number of bits. The main idea is to choose the error-correcting bits such that the index-XOR (the XOR of all the bit positions containing a 1) is 0. We use positions 1, 10, 100, etc. (in binary) as the error-correcting bits, which guarantees it is possible to set the error-correcting bits so that the index-XOR of the whole message is 0. If the receiver receives a string with index-XOR 0, they can conclude there were no corruptions, and otherwise, the index-XOR indicates the index of the corrupted bit.
An algorithm can be deduced from the following description:
- Number the bits starting from 1: bit 1, 2, 3, 4, 5, 6, 7, etc.
- Write the bit numbers in binary: 1, 10, 11, 100, 101, 110, 111, etc.
- All bit positions that are powers of two (have a single 1 bit in the binary form of their position) are parity bits: 1, 2, 4, 8, etc. (1, 10, 100, 1000)
- All other bit positions, with two or more 1 bits in the binary form of their position, are data bits.
- Each data bit is included in a unique set of 2 or more parity bits, as determined by the binary form of its bit position.
- Parity bit 1 covers all bit positions which have the least significant bit set: bit 1 (the parity bit itself), 3, 5, 7, 9, etc.
- Parity bit 2 covers all bit positions which have the second least significant bit set: bits 2-3, 6-7, 10-11, etc.
- Parity bit 4 covers all bit positions which have the third least significant bit set: bits 4–7, 12–15, 20–23, etc.
- Parity bit 8 covers all bit positions which have the fourth least significant bit set: bits 8–15, 24–31, 40–47, etc.
- In general each parity bit covers all bits where the bitwise AND of the parity position and the bit position is non-zero.
If a byte of data to be encoded is 10011010, then the data word (using _ to represent the parity bits) would be __1_001_1010, and the code word is 011100101010.
The choice of the parity, even or odd, is irrelevant but the same choice must be used for both encoding and decoding.
This general rule can be shown visually:

Shown are only 20 encoded bits (5 parity, 15 data) but the pattern continues indefinitely. The key thing about Hamming Codes that can be seen from visual inspection is that any given bit is included in a unique set of parity bits. To check for errors, check all of the parity bits. The pattern of errors, called the error syndrome, identifies the bit in error. If all parity bits are correct, there is no error. Otherwise, the sum of the positions of the erroneous parity bits identifies the erroneous bit. For example, if the parity bits in positions 1, 2 and 8 indicate an error, then bit 1+2+8=11 is in error. If only one parity bit indicates an error, the parity bit itself is in error.
https://en.wikipedia.org/wiki/Block_code#The_block_length_n
https://zh.wikipedia.org/wiki/分組碼
分组码(block code),又名块码,是信道编码(channel coding)技术的一种。它在传送端发送的原始讯息中,以比特率不会超过信道容量为前提下,加入额外的比特(redundancy),使接收端能够以最小(理论值为0)的错误率解码。
分组码主要的特性为它的密码长度固定(有别于使用变长编码表的霍夫曼编码(Huffman Coding))。一般来说分组码会将包含了k位数的信息字符s,转换到包含n位数的编码字符C(s);即分组码长度(block length)为n。
分组编码是早期移动通信(mobile communication)系统中,使用的主要信道编码(channel coding)方式。
Block code - Wikipedia https://en.wikipedia.org/wiki/Block_code#The_block_length_n
In coding theory, block codes are a large and important family of error-correcting codes that encode data in blocks. There is a vast number of examples for block codes, many of which have a wide range of practical applications. The abstract definition of block codes is conceptually useful because it allows coding theorists, mathematicians, and computer scientists to study the limitations of all block codes in a unified way. Such limitations often take the form of bounds that relate different parameters of the block code to each other, such as its rate and its ability to detect and correct errors.
The message length k
The block length n
The rate R
The distance d
Hamming code - Wikipedia https://en.wikipedia.org/wiki/Hamming_code
st=>start: 开始
e=>end: 结束
ipt=>inputoutput: 输入一个x
op=>operation: 第i个检验位的第1个的检验位是第2^i-1位,从该位开始
cond1=>condition: 至少有(2^i-1)*2位
sub1=>subroutine: 先一共检验2^i-1位
sub2=>subroutine: 再一共跳过2^i-1位
st->ipt->op->cond1->sub1->sub2->cond1
sub2->cond1
cond1(yes,left)->sub1
cond1(no)->e

https://zh.wikipedia.org/wiki/汉明距离
在信息论中,两个等长字符串之间的汉明距离(英语:Hamming distance)是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。
汉明重量是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是1的个数,所以11101的汉明重量是4。
范例
例如:
- 1011101与1001001之间的汉明距离是2。
- 2143896与2233796之间的汉明距离是3。
- "toned"与"roses"之间的汉明距离是3。
特性
对于固定的长度n,汉明距离是该长度字符向量空间上的度量,很显然它满足非负、唯一及对称性,并且可以很容易地通过完全归纳法证明它满足三角不等式。
两个字a与b之间的汉明距离也可以看作是特定运算−的a−b的汉明重量。
对于二进制字符串a与b来说,它等于a 异或b以后所得二进制字符串中“1”的个数。另外二进制字符串的汉明距离也等于n维超正方体两个顶点之间的曼哈顿距离,其中n是两个字串的长度。
历史及应用
汉明距离是以理查德·卫斯里·汉明的名字命名的,汉明在误差检测与校正码的基础性论文中首次引入这个概念。在通信中累计定长二进制字中发生翻转的错误数据位,所以它也被称为信号距离。汉明重量分析在包括信息论、编码理论、密码学等领域都有应用。但是,如果要比较两个不同长度的字符串,不仅要进行替换,而且要进行插入与删除的运算,在这种场合下,通常使用更加复杂的编辑距离等算法。
汉明码 - 维基百科,自由的百科全书 https://zh.wikipedia.org/zh-cn/汉明码
notes1.pdf http://www.cs.cmu.edu/~venkatg/teaching/codingtheory/notes/notes1.pdf
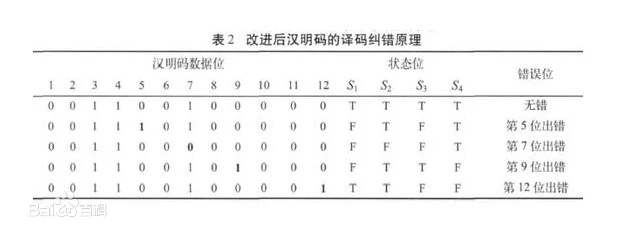
例子
对11000010进行汉明编码,求编码后的码字。
1.列出表格,从左往右(或从右往左)填入数字,但2的次方的位置不填。
| 位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 数据 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
2.把数据行有1的列的位置写为二进制。
| 位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 数据 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | ||||
| 二进制 | 0011 | 0101 | 1011 |
3.收集所有二进制数字,求异或。

4.把1101依次填入表格中2的次方的位置(低位在左)。
| 位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 数据 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | ||||
| 二进制 | 0011 | 0101 | 1011 | |||||||||
| 校验 | 1 | 0 | 1 | 1 |
5.所以编码后的码字是101110010010。
原始数据和奇偶位组成的新数据中,将总共包含偶数个1. 奇偶校验并不总是有效,如果数据中有偶数个位发生变化,则奇偶位仍将是正确的,因此不能检测出错误。
在一个7位的信息中,单个位出错有7种可能,因此3个错误控制位就足以确定是否出错及哪一位出错了。
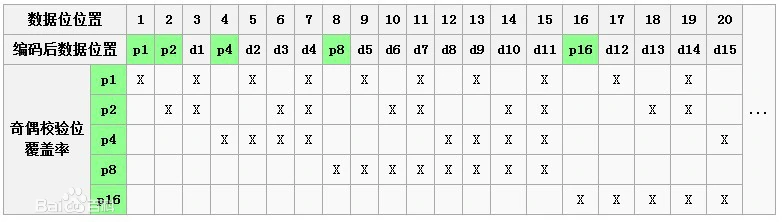
所有校验位覆盖了数据位置和该校验位位置的二进制与的值不为0的数。
奇偶校验位 汉明码 如果一条信息中包含更多用于纠错的位,且通过妥善安排这些纠错位使得不同的出错位产生不同的错误结果,那么我们就可以找出出错位了。
奇偶校验位 汉明码
奇偶校验位_百度百科 https://baike.baidu.com/item/奇偶校验位
汉明码_百度百科 https://baike.baidu.com/item/汉明码/3226749
- 中文名
- 汉明码
- 外文名
- Hamming Code

|
汉明码
|
编码用的数据码
|
|
P1
|
D8、D4、D1
|
|
P2
|
D8、D2、D1
|
|
P3
|
D4、D2、D1
|


 浙公网安备 33010602011771号
浙公网安备 33010602011771号