Base64原理 bits 3->4 8bits/byte-->6bits/byte
实践:
window.btoa('a')
a YQ==
abcdef YWJjZGVm
abc YWJj
ab YWI=
https://en.wikipedia.org/wiki/Base64
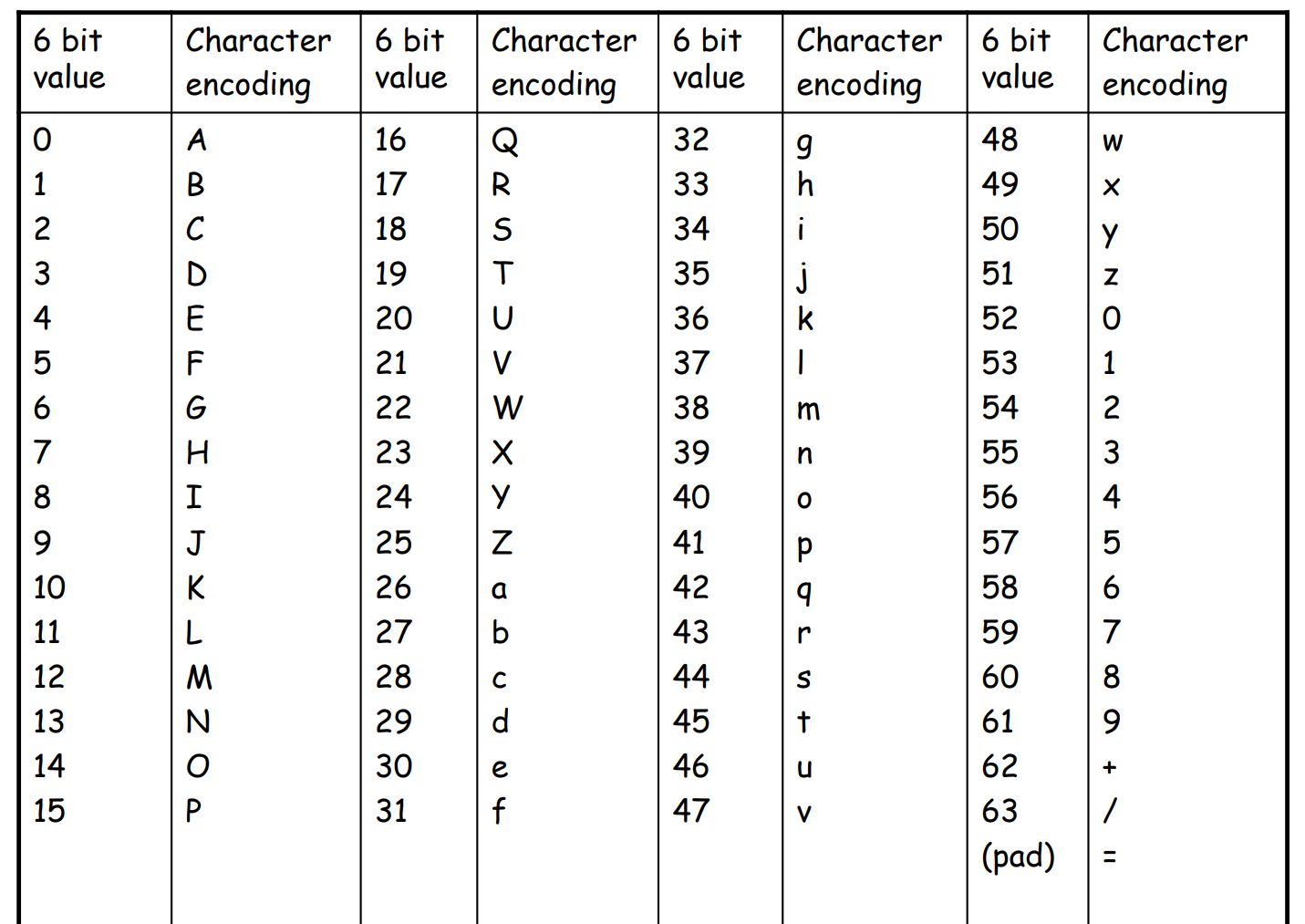
The Base64 index table:
| Value | Char | Value | Char | Value | Char | Value | Char | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A |
16 | Q |
32 | g |
48 | w |
|||
| 1 | B |
17 | R |
33 | h |
49 | x |
|||
| 2 | C |
18 | S |
34 | i |
50 | y |
|||
| 3 | D |
19 | T |
35 | j |
51 | z |
|||
| 4 | E |
20 | U |
36 | k |
52 | 0 |
|||
| 5 | F |
21 | V |
37 | l |
53 | 1 |
|||
| 6 | G |
22 | W |
38 | m |
54 | 2 |
|||
| 7 | H |
23 | X |
39 | n |
55 | 3 |
|||
| 8 | I |
24 | Y |
40 | o |
56 | 4 |
|||
| 9 | J |
25 | Z |
41 | p |
57 | 5 |
|||
| 10 | K |
26 | a |
42 | q |
58 | 6 |
|||
| 11 | L |
27 | b |
43 | r |
59 | 7 |
|||
| 12 | M |
28 | c |
44 | s |
60 | 8 |
|||
| 13 | N |
29 | d |
45 | t |
61 | 9 |
|||
| 14 | O |
30 | e |
46 | u |
62 | + |
|||
| 15 | P |
31 | f |
47 | v |
63 | / |
A quote from Thomas Hobbes' Leviathan (be aware of spaces between lines):
Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure.
is represented as a byte sequence of 8-bit-padded ASCII characters encoded in MIME's Base64 scheme as follows:
TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0aGlz IHNpbmd1bGFyIHBhc3Npb24gZnJvbSBvdGhlciBhbmltYWxzLCB3aGljaCBpcyBhIGx1c3Qgb2Yg dGhlIG1pbmQsIHRoYXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2YgZGVsaWdodCBpbiB0aGUgY29udGlu dWVkIGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVyYXRpb24gb2Yga25vd2xlZGdlLCBleGNlZWRzIHRo ZSBzaG9ydCB2ZWhlbWVuY2Ugb2YgYW55IGNhcm5hbCBwbGVhc3VyZS4=
In the above quote, the encoded value of Man is TWFu. Encoded in ASCII, the characters M, a, and n are stored as the bytes 77, 97, and 110, which are the 8-bit binary values 01001101, 01100001, and 01101110. These three values are joined together into a 24-bit string, producing 010011010110000101101110. Groups of 6 bits (6 bits have a maximum of 26 = 64 different binary values) are converted into individual numbers from left to right (in this case, there are four numbers in a 24-bit string), which are then converted into their corresponding Base64 character values.
| Text content | M | a | n | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASCII | 77 (0x4d) | 97 (0x61) | 110 (0x6e) | |||||||||||||||||||||
| Bit pattern | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| Index | 19 | 22 | 5 | 46 | ||||||||||||||||||||
| Base64-encoded | T | W | F | u | ||||||||||||||||||||
As this example illustrates, Base64 encoding converts three octets into four encoded characters.
https://en.wikipedia.org/wiki/MIME#Content-Transfer-Encoding
http://php.net/manual/en/function.base64-encode.php
base64_encode
(PHP 4, PHP 5, PHP 7)
base64_encode — Encodes data with MIME base64
Description ¶
$data )Encodes the given data with base64.
This encoding is designed to make binary data survive transport through transport layers that are not 8-bit clean, such as mail bodies.
Base64-encoded data takes about 33% more space than the original data.
https://zh.wikipedia.org/wiki/Base64
在MIME格式的电子邮件中,base64可以用来将binary的字节序列数据编码成ASCII字符序列构成的文本。使用时,在传输编码方式中指定base64。使用的字符包括大小写字母各26个,加上10个数字,和加号“+”,斜杠“/”,一共64个字符,等号“=”用来作为后缀用途。
完整的base64定义可见RFC 1421和RFC 2045。编码后的数据比原始数据略长,为原来的43。在电子邮件中,根据RFC 822规定,每76个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的135.1%。
转换的时候,将三个byte的数据,先后放入一个24bit的缓冲区中,先来的byte占高位。数据不足3byte的话,于缓冲器中剩下的bit用0补足。然后,每次取出6(因为26=64)个bit,按照其值选择ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字符作为编码后的输出。不断进行,直到全部输入数据转换完成。
当原数据长度不是3的整数倍时, 如果最后剩下一个输入数据,在编码结果后加2个“=”;如果最后剩下两个输入数据,编码结果后加1个“=”;如果没有剩下任何数据,就什么都不要加,这样才可以保证数据还原的正确性。
https://en.wikipedia.org/wiki/ASCII
American Standard Code for Information Interchange
Originally based on the English alphabet, ASCII encodes 128 specified characters into seven-bit integers as shown by the ASCII chart on the right.[8] The characters encoded are numbers 0 to 9, lowercase letters a to z, uppercase letters A to Z, basic punctuation symbols, control codes that originated with Teletype machines, and a space. For example, lowercase j would become binary 1101010 and decimal 106. ASCII includes definitions for 128 characters: 33 are non-printing control characters (many now obsolete)[9] that affect how text and space are processed[10] and 95 printable characters, including the space (which is considered an invisible graphic[1]:223[11]).
1、8bits->6bits ,bit长度为之前的4/3, 8bits/byte-->6bits/byte
https://www.cse.ust.hk/faculty/cding/CSIT571/SLIDES/Radix-64.pdf
WindowOrWorkerGlobalScope.btoa() - Web APIs | MDN https://developer.mozilla.org/en-US/docs/Web/API/WindowOrWorkerGlobalScope/btoa
WindowOrWorkerGlobalScope.btoa() - Web API 接口参考 | MDN https://developer.mozilla.org/zh-CN/docs/Web/API/WindowBase64/btoa
WindowOrWorkerGlobalScope.btoa() 从 String 对象中创建一个 base-64 编码的 ASCII 字符串,其中字符串中的每个字符都被视为一个二进制数据字节。
Note: 由于这个函数将每个字符视为二进制数据的字节,而不管实际组成字符的字节数是多少,所以如果任何字符的码位超出 0x00 ~ 0xFF 这个范围,则会引发 InvalidCharacterError 异常。请参阅 Unicode_字符串 ,该示例演示如何编码含有码位超出 0x00 ~ 0xFF 范围的字符的字符串。
语法
let encodedData = window.btoa(stringToEncode);
参数
stringToEncode- 一个字符串, 其字符分别表示要编码为 ASCII 的二进制数据的单个字节。
返回值
一个包含 stringToEncode 的 Base64 表示的字符串。
示例
let encodedData = window.btoa("Hello, world"); // 编码
let decodedData = window.atob(encodedData); // 解码
备注
你可以使用此方法对可能导致通信问题的数据进行编码,传输,然后使用 atob()
在用 JavaScript 编写 XPCOM 组件时,btoa() 方法也是可用的,虽然全局对象已经不是 Window 了。
Unicode 字符串
在多数浏览器中,使用 btoa() 对 Unicode 字符串进行编码都会触发 InvalidCharacterError 异常。
一种选择是转义任何扩展字符,以便实际编码的字符串是原始字符的 ASCII 表示形式。考虑这个例子,代码来自 Johan Sundström:
// ucs-2 string to base64 encoded ascii
function utoa(str) {
return window.btoa(unescape(encodeURIComponent(str)));
}
// base64 encoded ascii to ucs-2 string
function atou(str) {
return decodeURIComponent(escape(window.atob(str)));
}
// Usage:
utoa('✓ à la mode'); // 4pyTIMOgIGxhIG1vZGU=
atou('4pyTIMOgIGxhIG1vZGU='); // "✓ à la mode"
utoa('I \u2661 Unicode!'); // SSDimaEgVW5pY29kZSE=
atou('SSDimaEgVW5pY29kZSE='); // "I ♡ Unicode!"
更好、更可靠、性能更优异的解决方案是使用类型化数组进行转换。
规范
| 规范 | 状态 | 备注 |
|---|---|---|
| HTML Living Standard WindowOrWorkerGlobalScope.btoa() |
Living Standard | Method moved to the WindowOrWorkerGlobalScope mixin in the latest spec. |
| HTML 5.1 WindowBase64.btoa() |
Recommendation | Snapshot of HTML Living Standard. No change. |
| HTML5 WindowBase64.btoa() |
Recommendation | Snapshot of HTML Living Standard. Creation of WindowBase64 (properties where on the target before it). |
Polyfill
// Polyfill from https://github.com/MaxArt2501/base64-js/blob/master/base64.js (function() { // base64 character set, plus padding character (=) var b64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=", // Regular expression to check formal correctness of base64 encoded strings b64re = /^(?:[A-Za-z\d+\/]{4})*?(?:[A-Za-z\d+\/]{2}(?:==)?|[A-Za-z\d+\/]{3}=?)?$/; window.btoa = window.btoa || function(string) { string = String(string); var bitmap, a, b, c, result = "", i = 0, rest = string.length % 3; // To determine the final padding for (; i < string.length;) { if ((a = string.charCodeAt(i++)) > 255 || (b = string.charCodeAt(i++)) > 255 || (c = string.charCodeAt(i++)) > 255) throw new TypeError("Failed to execute 'btoa' on 'Window': The string to be encoded contains characters outside of the Latin1 range."); bitmap = (a << 16) | (b << 8) | c; result += b64.charAt(bitmap >> 18 & 63) + b64.charAt(bitmap >> 12 & 63) + b64.charAt(bitmap >> 6 & 63) + b64.charAt(bitmap & 63); } // If there's need of padding, replace the last 'A's with equal signs return rest ? result.slice(0, rest - 3) + "===".substring(rest) : result; }; window.atob = window.atob || function(string) { // atob can work with strings with whitespaces, even inside the encoded part, // but only \t, \n, \f, \r and ' ', which can be stripped. string = String(string).replace(/[\t\n\f\r ]+/g, ""); if (!b64re.test(string)) throw new TypeError("Failed to execute 'atob' on 'Window': The string to be decoded is not correctly encoded."); // Adding the padding if missing, for semplicity string += "==".slice(2 - (string.length & 3)); var bitmap, result = "", r1, r2, i = 0; for (; i < string.length;) { bitmap = b64.indexOf(string.charAt(i++)) << 18 | b64.indexOf(string.charAt(i++)) << 12 | (r1 = b64.indexOf(string.charAt(i++))) << 6 | (r2 = b64.indexOf(string.charAt(i++))); result += r1 === 64 ? String.fromCharCode(bitmap >> 16 & 255) : r2 === 64 ? String.fromCharCode(bitmap >> 16 & 255, bitmap >> 8 & 255) : String.fromCharCode(bitmap >> 16 & 255, bitmap >> 8 & 255, bitmap & 255); } return result; }; })()
The WindowOrWorkerGlobalScope.btoa() method creates a Base64-encoded ASCII string from a binary string (i.e., a String object in which each character in the string is treated as a byte of binary data).
You can use this method to encode data which may otherwise cause communication problems, transmit it, then use the atob() method to decode the data again. For example, you can encode control characters such as ASCII values 0 through 31.
Syntax
var encodedData = scope.btoa(stringToEncode);
Parameters
stringToEncode- The binary string to encode.
Return value
An ASCII string containing the Base64 representation of stringToEncode.
Exceptions
Example
const encodedData = window.btoa('Hello, world'); // encode a string
const decodedData = window.atob(encodedData); // decode the string
Unicode strings
The btoa() function takes a JavaScript string as a parameter. In JavaScript strings are represented using the UTF-16 character encoding: in this encoding, strings are represented as a sequence of 16-bit (2 byte) units. Every ASCII character fits into the first byte of one of these units, but many other characters don't.
Base64, by design, expects binary data as its input. In terms of JavaScript strings, this means strings in which each character occupies only one byte. So if you pass a string into btoa()containing characters that occupy more than one byte, you will get an error, because this is not considered binary data:
const ok = "a";
console.log(ok.codePointAt(0).toString(16)); // 61: occupies < 1 byte
const notOK = "✓"
console.log(ok.codePointAt(0).toString(16)); // 2713: occupies > 1 byte
console.log(btoa(ok)); // YQ==
console.log(btoa(notOK)); // errorIf you need to encode Unicode text as ASCII using btoa(), one option is to convert the string such that each 16-bit unit occupies only one byte. For example:
// convert a Unicode string to a string in which
// each 16-bit unit occupies only one byte
function toBinary(string) {
const codeUnits = new Uint16Array(string.length);
for (let i = 0; i < codeUnits.length; i++) {
codeUnits[i] = string.charCodeAt(i);
}
return String.fromCharCode(...new Uint8Array(codeUnits.buffer));
}
// a string that contains characters occupying > 1 byte
const myString = "☸☹☺☻☼☾☿";
const converted = toBinary(myString);
const encoded = btoa(converted);
console.log(encoded); // OCY5JjomOyY8Jj4mPyY=
If you do this, of course you'll have to reverse the conversion on the decoded string:
function fromBinary(binary) {
const bytes = new Uint8Array(binary.length);
for (let i = 0; i < bytes.length; i++) {
bytes[i] = binary.charCodeAt(i);
}
return String.fromCharCode(...new Uint16Array(bytes.buffer));
}
const decoded = atob(encoded);
const original = fromBinary(decoded);
console.log(original); // ☸☹☺☻☼☾☿
WindowOrWorkerGlobalScope - Web API 接口参考 | MDN https://developer.mozilla.org/zh-CN/docs/Web/API/WindowOrWorkerGlobalScope
WindowOrWorkerGlobalScope.atob()对 base-64加密的数据字符串进行解码。WindowOrWorkerGlobalScope.btoa()从二进制数据中创建 base-64 编码的 ASCII 字符串。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号