1.2亿问答数据-问题去重 怎样对10亿个数字快速去重?——浅析位图数据结构及其应用
怎样对10亿个数字快速去重?——浅析位图数据结构及其应用 - 张海拔 - 博客园 https://www.cnblogs.com/zhanghaiba/p/3594559.html
怎样对10亿个数字快速去重?——浅析位图数据结构及其应用
最近有个朋友问我一个算法题——
给你几亿个QQ号,怎样快速去除重复的QQ号?
可以作如下假定:
QQ号数字范围从0到十亿,即[0, 1000000000),且最多给你10亿个QQ号,这些QQ号放在1或多个文本文件中,格式是每行一个QQ号。
请读者先独立思考一下该怎样解决。
————————————————————————————————————————————————————————
其实在一年前碰过类似的问题,当时的解决方案:借助hash算法思想,把一个大文件哈希分割到多个小文件中,而哈希冲突的数字
一定会在同一个小文件中,从而保证了子问题的独立性,然后就可以单独对小文件通过快速排序来去重。
这样就通过分而治之解决了几G数据进行内排序的问题。
虽然哈希分割文件是O(n)的时间复杂度,但总的效率仍是依从快速排序的时间复杂度O(n*logn)。
另外,分而治之有个好处就是借助子问题的独立性可以利用多核来做并行处理,甚至做分布式处理。
后来小菜在《编程珠玑》中看到了位图这个数据结构可以很方便地处理此类问题,时间复杂度可以达到了O(n)
那怎么实现这个数据结构呢?
位图的原理类似我们常用的标记数组map[]/vis[],比如map[i] = 1表示把第i个元素标记为1,按照这种思想来去重是很简单的。
现在假定QQ号数字范围是[0, 10亿),则要申请10亿个char元素用来做标记,那么进程就需要1G的运行内存。
那如果数字范围增大到100亿,一般的计算机可能就吃不消了。
位图数据结构只需要1/8的空间,节省7/8的内存是非常可观的。
因为标记只有1和0两个值,所以可以只用一个比特位来做标记。
设有char类型数x,1字节包括8个位,我们可以申请char bit_map[10亿/8+1]的空间,就足以给范围在[0,10亿)的数字去重了。
选择char类型而不是int等其它类型是考虑到,C标准规定任何实现都要保证char类型占1个字节。
+1,是考虑到C整型除法向下取整的特点,比如100/8结果为12,这样访问编号>=96的比特位(设从0开始编号),就会发生数组越界。
我们知道位图的数据结构就是一个数组,而位图的操作(算法)基本依赖于下面3个元操作
set_bit(char x, int n); //将x的第n位置1,可以通过x |= (1 << n)来实现
clr_bit(char x, int n); //将x的第n位清0,可以通过x &= ~(1 << n)来实现
get_bit(char x, int n); //取出x的第n位的值,可以通过(x >> n) & 1来实现
有了上面3个元操作,位图的具体操作就简单了——
比如,要对数字int x = 1848105做标记,就可以调用set_bit(bit_map[x/8], x%8);
除法看做求“组编号”,x/8即是 以8个位为一个小组,分组到编号为idx = x/8的bit_map元素中,然后在组内偏移lft = x%8个比特位。
考虑到这些操作是非常频繁的,所以把上述三个方法改写成宏减少函数调用的开销,并且把x/8改为x<<3,x%8改为x&7。
经过上面的分析,写代码就很不难了——
/*
*CopyRight (C) Zhang Haiba
*File: 1billon_remove_duplicate_not_sort.c
*Date: 2014.03.11
*/
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAP_LEN (1000000000/8 + 1)
#define BUF_SIZE 10
#define SET_BIT(x, n) ( (x) |= (1 << (n)) )
#define GET_BIT(x, n) ( ((x)>>(n)) & 1 )
char bit_map[MAP_LEN];
int main(int argc, const char *argv[])
{
FILE *ifp, *ofp;
int idx, lft, x;
char buf[BUF_SIZE]; //cut if number length > BUF_SIZE ex. range[0, 1000000000) then BUF_SIZE=10
if (argc == 1) {
fprintf(stderr, "usage: %s inputfile1 inputfile2 ...\n", argv[0]);
exit(1);
} else {
ofp = fopen("./output.txt", "w");
for (idx = 1; idx <= argc; ++idx) {
if ( (ifp = fopen(argv[idx], "r")) == NULL ) {
fprintf(stderr, "%s: can not open %s\n", argv[0], argv[idx]);
exit(1);
}
printf("processing the %dth file...\n", idx);
while ( fgets(buf, sizeof buf, ifp) != NULL ) {
sscanf(buf, "%d", &x);
idx = x >> 3;
lft = x & 7;
if (GET_BIT(bit_map[idx], lft) == 0) {
bit_map[idx] = SET_BIT(bit_map[idx], lft);
fprintf(ofp, "%d\n", x);
}
}
fclose(ifp);
}
fclose(ofp);
}
return 0;
}
【测试用例1:】
ZhangHaiba-MacBook-Pro:KandR apple$ time ./a.out input2.txt processing the 1th file... real 0m0.028s user 0m0.001s sys 0m0.002s
输入输出文件对比:
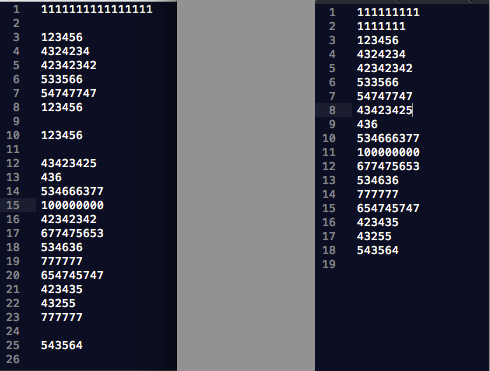
由于实现中故意使用了fgets(),可以防止输入文本中长度不合法的数据
对于长度超过限制,则进行截断处理(见上图左边第一行),同时可以达到滤空的效果。
【测试用例2:】
我们可以写一个小程序生成N个范围[0, 10亿)的数字,也就是最大的数是包含9个9的999999999。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 1000000000
int main(void)
{
srand((unsigned)time(NULL));
fprintf(stderr, "this prog output N random numbers to stdout.\nPlease enter the value of N:\n");
int n, i;
scanf("%d", &n);
for (i = 0; i < n; ++i)
printf("%d\n", rand()%MAX);
return 0;
}
通过这个程序生成1亿个随机数并重定向输出到input1.txt,则这个文本文件大概有970Mb,然后执行测试
ZhangHaiba-MacBook-Pro:KandR apple$ time ./a.out input1.txt processing the 1th file... real 1m12.263s user 1m0.716s sys 0m2.685s
耗时1分12秒,速度飞快!
如果需要输出的文本内容是有序的,稍作修改即可——
/*
*CopyRight (C) Zhang Haiba
*File: 1billon_remove_duplicate_sort.c
*Date: 2014.03.11
*/
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAP_LEN (1000000000/8 +1)
#define BUF_SIZE 10
#define CLR_BIT(x, n) ( (x) &= ~(1 << (n)) )
#define SET_BIT(x, n) ( (x) |= (1 << (n)) )
#define GET_BIT(x, n) ( ((x)>>(n)) & 1 )
char bit_map[MAP_LEN];
int main(int argc, const char *argv[])
{
FILE *fp;
int idx, lft, x;
char buf[BUF_SIZE]; //cut if number length > BUF_SIZE ex. range[0, 1000000000) then BUF_SIZE=10
if (argc == 1) {
fprintf(stderr, "usage: %s inputfile1 inputfile2 ...\n", argv[0]);
exit(1);
} else {
//memset(bit_map, 0, sizeof bit_mape);
for (idx = 1; idx <= argc; ++idx) {
if ( (fp = fopen(argv[idx], "r")) == NULL ) {
fprintf(stderr, "%s: can not open %s\n", argv[0], argv[idx]);
exit(1);
}
printf("processing the %dth file...\n", idx);
while ( fgets(buf, sizeof buf, fp) != NULL ) {
sscanf(buf, "%d", &x);
idx = x >> 3;
lft = x & 7;
bit_map[idx] = SET_BIT(bit_map[idx], lft);
}
fclose(fp);
}
fp = fopen("./output.txt", "w");
printf("output to file: output.txt...\n");
for (idx = 0; idx < MAP_LEN; ++idx) {
for (lft = 0; lft < 8; ++lft)
if (GET_BIT(bit_map[idx], lft) == 1)
fprintf(fp, "%d\n", (idx<<3)+lft);
}
fclose(fp);
}
return 0;
}
实际测试发现,对于很小的输入文本(例如空文本),这种方法也需要3~4秒的本机执行时间用于遍历输出。
但对于上面将近1G的输入文本文件,测试时间与不排序的实现方案相差无几,甚至略快一点。
@Author: 张海拔
@Update: 2014-3-11
@Link: http://www.cnblogs.com/zhanghaiba/p/3594559.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号