chapter6.4 序列化和反序列化
序列化和反序列化
序列化保存到文件就是持久化,按照某种规则保存数据到文件,文件是个字节序列,把数据转换成字节序列,输出到文件或者发到网络,就是序列化,反之,从文件到内存,就是反序列化。
serializatoion
pickle库,python使用的序列化方式,效率较低,只有python使用。
dumps 对象序列化为bytes对象
dump 对象序列化到文件,就是存入文件
load bytes对象反序列化到内存
loads d对象反序列化,从文件读取数据
序列化就是按照一定格式,保存数据,反序列化就是找到可以恢复的对象
序列化对于每个对象都有其属性,每个对象不同,就需要序列化
序列化与反序列化要用同一套类的定义,否则会抛异常,类要用同一套,否则会发生不可预料的结果。
可以理解为:反序列化时,类是模子,二进制序列是铁水。
序列化应用大多用在网络传输中。本地序列化后通过网络传输到远程节点中,远程服务器上的服务接收后,反序列化就可以使用了。
要注意远程段接受后,反序列化要有对应的数据类型,否则报错,尤其自定义类型,必须要有一致的定义。
不同的协议,效率不同,学习曲线不同,适用不同场景,要根据不同的情况分析选型。
protocol Buffer :Google的协议,学习曲线陡峭。
XML:以前使用的网络传输协议标准,现在可以替代ini配置文件,或者使用Json
Json :JavaScript Object Notation
轻量级的数据交换格式,基于ECMAScript(w3c组织制定的Js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据
Json的数据类型
值,双引号引起的字符串,数值,true,false,null,对象,数组,都是值
字符串,由双引号包围的任意字符的组合,可以有转义字符
数值,有正负,整数,浮点数
对象 object:就是py的字典,
数组array:py的列表
可以到官网看图理解,官网的图是铁路图。
json模块
python支持少量内建数据类型的Json类型的转换。
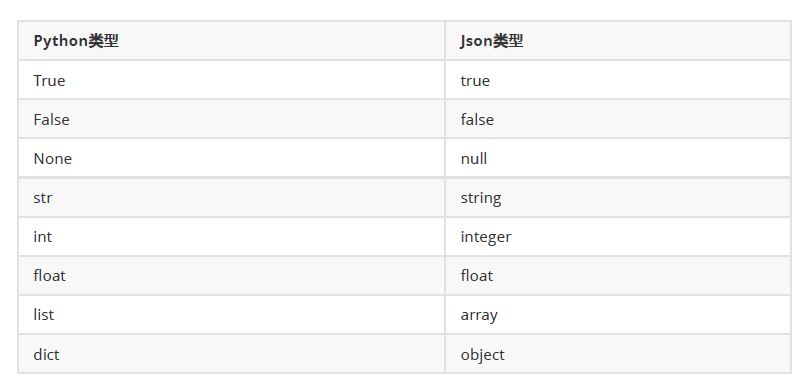
常用方法:dump;dumps;load;loads
一般json编码很少落地,数据都是通过网络传输,传输时要考率压缩
压缩,压缩字节,去除空格等,很少落地,网络传输
本质是文本,是一串字符串
json很简单,几乎所有编程语言都支持json,所以应用范围广泛。
MessagePack
是一个基于二进制的对象序列化类库,可以跨语言通信,可以在很多语言之间交换数据
比json更快速轻巧,支持语言众多,支持json和pickle
简单易用,高效压缩,支持语言丰富
安装
pip install msgpack-python
常用方法
packb序列化对象,提供了dumps来兼容json和pickle
unpack 反序列化对象,使用loads
pack 序列化对象保存到文件对象,使用dump
unpack 反序列化对象到保存的文件,使用load
import json d={'name':'Tom','age':23,'interest':['music',"movie"]} j = json.dumps(d) print(j,type(j)) print(len(j.replace(" ",""))) import msgpack m = msgpack.dumps(d) print(m,type(m)) print(len(m))
和json比较,json为52,msgpack为37
是序列化的很好的选择
官网https://msgpack.org


 浙公网安备 33010602011771号
浙公网安备 33010602011771号