
mybatis是怎样炼成的
前言
一些个人感受:不管分析什么源码,如果我们能摸索出作者的心路历程,跟着他的脚步一步一步往前走,这样才能接近事实的真相,也能更平滑更有趣的学习到知识。跟福尔摩斯探案一样,作者都经历了些什么,为什么他要这样去设计这样去做,留给我们的只有无声的代码和那一段孤独的日子。
阅读顺序建议是从上往下阅读,如果直接跳转到某一节,没有基于上面的分析推理的话可能会不容易理解。
一切的一切要从JDBC开始说起
先来一段JDBC代码回忆预热一下,方便我们后面进入正题
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
String sql = "SELECT id, first, last, age FROM student where id=?";
Statement stmt = conn.prepareStatement(sql);
pre.setBigDecimal(1, 10000);
ResultSet rs = stmt.executeQuery();
while(rs.next()){
int id = rs.getBigDecimal("id");
int age = rs.getInt("age");
}
rs.close();
stmt.close();
conn.close();
关于jdbc为什么要这样去抽象我们先放到一边,简单提取出几个关键对象:
Connection
Statement
ResultSet
一、mybatis抽象出来的关键对象
mybatis是怎样一步一步演变出来的,其中设计思路是怎样的,mybatis关键对象又是怎么被抽象出来的?
1.Sql语句提取到xml文件
众所周知,mybatis的一大创新和亮点,是将sql语句写到xml文件
StringBuilder sql = new StringBuilder("SELECT * FROM BLOG WHERE state = 'ACTIVE'");
if (title != null) {
sql.append("AND title like ?");
}
if (author!=null&&author.name!=null){
sql.append("AND author_name like ?");
}
Mybatis将sql语句提出来放到xml里,比上面java代码看起来可读性操作性都强很多,而且sql会统一放在一个地方一起管理,等于将sql与代码进行了分离,后面从全局去看sql、分析优化sql确实也会带来便利。当然,也可以通过注解的形式把sql语句写到java代码里,这样的目的和写到xml一样,也是为了把sql单独提取出来。
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
然后配置文件我们分为哪些呢,除了要执行的sql,即sql mapper外,我们还需要配置一些全局的设置吧,例如数据源等等
所以配置文件我们分为两类:
Sql语句的配置
BlogMapper.xml
<mapper namespace="BlogMapper"> <select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE state = ‘ACTIVE’ <if test="title != null"> AND title like #{title} </if> <if test="author != null and author.name != null"> AND author_name like #{author.name} </if> </select> </mapper>
全局的配置
config.xml
<configuration> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> <environments default="development"> <environment id="development"> <transactionManager type="JDBC "> </transactionManager> <dataSource type="POOLED"> <property name="driver" value="123"/> <property name="url" value="456"/> <property name="username" value="789"/> <property name="password" value="10"/> </dataSource> </environment> </environments> </configuration>
当然,以上通过xml文件进行配置的都可用java代码进行配置
这里environments我们不做过多分析,主要是把多环境的配置都写在一起,但是不管配置多少个environment,最后也只会用 default属性的那个,即只有一个在运行时生效
如果有多个数据源,则需要多个config.xml配置文件去配置对应的数据源
那么问题来了,上面两类xml解析后放到哪里,抽象出了哪些对象?
2.Configuration
将配置文件统一解析到Configuration对象,从xml解析的内容先放在这,后面谁想用拿去用就行了,这里还是很好理解
Configuration对象如何生成呢?
可以通过读取config.xml文件:
XMLConfigBuilder parser = new XMLConfigBuilder(reader); Configuration configuration=parser.parse();
当然,也可以通过java代码来初始化:
TransactionFactory transactionFactory = new JdbcTransactionFactory(); Environment environment = new Environment("development", transactionFactory, dataSource); Configuration configuration = new Configuration(environment); configuration.setDatabaseId("mysql");
//基于java注解配置sql configuration.addMapper(IBlogMapper.class);
//基于mapper.xml配置sql Resource[] mapperLocations = new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*.xml"); if (!isEmpty(mapperLocations)) { for (Resource mapperLocation : mapperLocations) { if (mapperLocation == null) { continue; } try { XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(mapperLocation.getInputStream(), configuration, mapperLocation.toString(), configuration.getSqlFragments()); xmlMapperBuilder.parse(); } catch (Exception e) { throw new NestedIOException("Failed to parse mapping resource: '" + mapperLocation + "'", e); } finally { ErrorContext.instance().reset(); } } }
configuration对象为mybatis抽象出的第一个关键对象,configuration对象里面长什么样,我们接着往下分析
2.1 SqlNode
首先我们从java解析xml开始,直接通过org.w3c.dom 来解析如下一段xml(mybatis的xml映射语句格式已经深入人心,我们这里也先不去操心为什么mybatis设计出sql语句在xml中写成如下格式)
<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE state = ‘ACTIVE’ <if test="title != null"> AND title like #{title} </if> <if test="author != null and author.name != null"> AND author_name like #{author.name} </if> </select>
我们会得到父子关系如下的node集合(为了方便理解,我们忽略掉标签之间换行\n节点,后文同样也是省略掉):
<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE state = ‘ACTIVE’ =>Node(type:TEXT_NODE) <if test="title != null"> =>Node(type:Element) AND title like #{title} =>ChildNode(type:TEXT_NODE) </if> <if test="author != null and author.name != null"> =>Node(type:Element) AND author_name like #{author.name} =>ChildNode(type:TEXT_NODE) </if> </select>
我们得到父节点 <select>节点下一共有三个节点,然后两个Element节点里各有一个子节点
那么该xml node我们应该如何存到内存里呢,我们应该抽象成什么对象呢?
这里就引入了SqlNode对象,原始的org.w3c.dom 解析出来的Node对象已经满足不了我们的需求,就算能满足我们处理起来也很绕,所以我们要转变成我们个性化的Node对象,方便去做判断和sql的拼接等操作
所以在这里每个xml node都会转变成mybatis 的SqlNode,mybatis抽象出的SqlNode类型如下:
| SqlNode | 说明 |
| IfSqlNode | <if> 标签生成的node,其test属性需配合ognl使用 |
| ChooseSqlNode | <choose> <when> <otherwise> 标签生成的node |
| ForEachSqlNode | <foreach> 标签生成的node |
| StaticTextSqlNode |
静态文本内容,可以包含#{}占位符
|
| TextSqlNode |
也是动态的node,带有${}占位符的文本内容
|
| VarDeclSqlNode | <bind> 标签生成的node |
| TrimSqlNode | <trim> 标签生成的node |
| SetSqlNode | 继承自TrimSqlNode,<set> 标签生成的node |
| WhereSqlNode | 继承自TrimSqlNode,<where> 标签生成的node |
| MixedSqlNode |
一种特殊的节点,不是由具体的sql标签产生,相当于org.w3c.dom 的getChildNodes()返回的NodeList,即存放父节点的子节点集合 |
共 10 种,严格意义上来说只有 9 种, MixedSqlNode是一种特殊的节点,其本身并没有什么逻辑,只是在父节点存放其子节点的集合用
那么上面xml转换成mybatis SqlNode后长什么样呢?如下图(为了方便理解,我们忽略掉标签之间换行\n节点,后文同样也是省略掉)
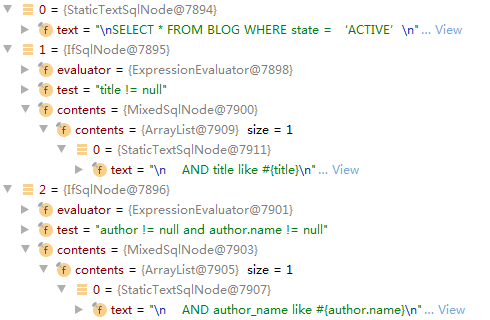
同org.w3c.dom 解析出来一样, 一共三个节点,然后两个Element节点里各有一个子节点(不管一个节点的子节点有多少个,其子节点都会以集合形式统一放在MixSqlNode节点下)
StaticTextSqlNode
IfSqlNode
--StaticTextSqlNode(由MixedSqlNode进行一层包装)
ifSqlNode
--StaticTextSqlNode(由MixedSqlNode进行一层包装)
有同学肯定会说不对啊,少了一层MixedSqlNode
是的,只要父节点包含子节点,不论子节点有多少个,那么子节点的集合统一都会放在MixedSqlNode节点下,是父子节点之间的媒介,为了方便理解我们这里先省略掉它
ognl
只在<if>和<foreach>标签的SqlNode中用到,例如if标签里常用到 test判断,我们如何判断对应的表达式呢,就是ognl的用武之地了
不清楚ognl的同学可以去搜索一下该关键字,如下下划线xml里面的条件判断都是通过ognl结合请求参数去执行出来结果
<if test="title != null">
<if test="author != null and author.name != null">
当把请求参数给到SqlNode时,通过参数和判断表达式,再结合ognl就能得到boolean结果,这样就可以去判断是否要append当前节点的子节点的sql语句了
伪代码如下:
if (Ognl.getValue("title != null", parameterObject)) { sql.append("AND title like #{title}"); }
2.2 BoundSql
我们上面将xml里的每段CRUD标签解析成了对应的一批SqlNode
那么运行时,通过请求参数我们需要提取出来最终到数据库执行的jdbc statement,才能继续将我们的流程往下走
#{} 占位符
我们在mybatis xml中写sql语句时,可以写 #{} 和 ${} 占位符,这是原始jdbc statment不支持的,这样的书写方式解决了我们之前sql语句参数要用 “?” 问号,然后statment赋值要注意顺序的问题,参数一多眼睛就花了
mybatis将这个问题帮我们简化了,可以在sql段里面写 #{} 占位符,项目运行时 #{} 会被替换成 "?" 和对应排好序的参数集合
然后再去执行statement,伪代码如下:
Connection connection = transaction.getConnection();//从事务管理获取connection PreparedStatement statement = connection.prepareStatement(sql);//准备statement for (int i = 0; i < parameterMappings.size(); i++) {//循环参数列表给statement赋值 Object value = requestObject.getValue(parameterMappings.get(i).getName());//通过反射拿到入参的属性值 preparedStatement.setBigDecimal(i, new BigDecimal(value));//给statement赋值 } preparedStatement.execute();
几个关键点:
1.prepareStatement 的 sql语句,即#{} 替换成 "?"的sql
2.#{} 替换成 "?" 后,排好序的参数列表
3.给statement赋值时,我们怎么知道是 setInt 还是 setBigDecimal
这3个点,就是接下来要关注的,让我们来看看mybatis是怎么做的
Sql
如何通过SqlNode、请求参数 得到最终执行的sql?
其实上面说ognl的时候已经提到了,简单理解就是由请求参数和条件表达式结合拼接出来,然后再把 "#{}" 替换成 "?" 即可
ParameterMapping
排好序的参数列表,给statement赋值使用
xml使用示例:
#{property,javaType=int,jdbcType=NUMERIC}
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
有如下一些关键的属性:
property
即 #{xxx} 中的属性名,是字符串
javaType
通过 #{}占位符中定义,如果没有定义则找入参对象parameterType该属性的类型
优先级如下(由高到低):
1.xml配置文件中定义的类型
2.入参对象该property属性的java type
例如下面配置的 #{title},就是通过反射找 入参对象的title 属性的java type
<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE state = ‘ACTIVE’ <if test="title != null"> AND title like #{title} </if> <if test="author != null and author.name != null"> AND author_name like #{author.name} </if> </select>
如果传递进来的入参是Map,那么通过反射就找不到对应属性的java type,这种情况下该属性的 javaType 会设置成 Object.class
Map map=new HashMap();
map.put("title","123");
map.put("author",new Author(){{setName("tt");}});
session.select("com.tj.mybatis.IBlogMapper.findActiveBlogLike",map,null);
TypeHandler
#{property,javaType=int,jdbcType=NUMERIC}
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}
优先级如下(由高到低):
1.xml配置文件中定义的类型
2.通过javaType去找对应的TypeHandler
该对象的作用就是解决给statement赋值时,让我们知道是用ps.setInt(value) 还是 ps.setBigDecimal(value)
分为get 和 set:
给statement赋值时 通过java类型找jdbc类型
给java 对象赋值时 拿到数据库查询结果ResultSet后,是用哪个方法给java对象赋值rs.getInt("age"); 还是 rs.getBigDecimal("age");通过jdbc类型找java类型
UnknownTypeHandler
上面java type为Object.class时,例如入参是Map 找不到对应的属性的java type,其对应的TypeHandler为UnknownTypeHandler
这种情况下,在给statement入参赋值时会再次根据获取到的入参的值的类型去找TypeHandler
例如 title 属性的值为 "123" 那么再通过值"123"去找其对应的 TypeHandler,即StringTypeHandler
${} 占位符
${} 和 #{} 这两种占位符的处理流程是不一样的:
${}占位符在执行时,会将sql替换成我们参数设置的sql段,有sql注入风险,且该sql段可能还包含#{}占位符
例如:
select * from blog ${where}
可能会被替换成如下sql
select * from blog where title like #{title}
即替换内容为 "where title like #{title}",所以替换完后会再走一遍#{}占位符的替换流程
如果xml中sql语句只包含 #{}占位符,那么通过请求参数,我们需要做的就是通过条件拼接sql(无sql注入风险),然后给statement参数赋值即可
如果xml中sql语句包含${}占位符,那么需要将${}占位符进行替换,然后再进行上面#{}的流程,因为 ${} 可能包含 带有#{}占位符的语句替换进去
所以mybatis流程上是统一先处理${}占位符,再处理#{}占位符(SqlSource.getBoundSql 方法的流程),然后一个有sql注入风险一个无sql注入风险。
所以执行过程中,sqlNode最后变成了 statement所需要的两大关键点:
1.sql(jdbc statement可直接使用的sql)
2.参数列表 ParameterMappings(排好序的,给statment赋值时直接按顺序遍历赋值),其又包含:属性名property和TypeHandler
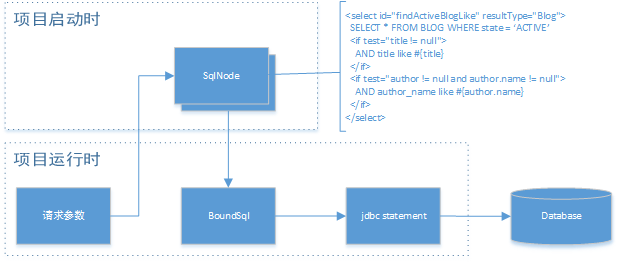
这就是我们的BoundSql对象,该对象包含上面两个关键属性
如下是大致的流程:
2.3 SqlSource
RawSqlSource 与 DynamicSqlSource
首先我们先分析一下如下两段sql,在运行时执行时有什么异同?
第一段sql:
<select id="selectBlog" resultType="Blog"> SELECT * FROM BLOG WHERE id = #{id} </select>
第二段sql:
<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE state = ‘ACTIVE’ <if test="title != null"> AND title like #{title} </if> <if test="author != null and author.name != null"> AND author_name like #{author.name} </if> </select>
第一段sql我们在执行时不需要根据传递进来的条件参数进行sql拼接,在项目启动时就可以直接得到BoundSql的两个关键属性:
1.sql
SELECT * FROM BLOG WHERE id=?
2.参数列表:
id
在执行时,也根本不需要再做#{}标签的替换,直接拿BoundSql和参数赋值给statment即可
而第二段sql我们在项目启动时没法提前得到BoundSql,只能在运行时通过传递进来的参数做判断才能得到BoundSql。
总结:
第一段sql,静态sql,执行时速度更快,项目加载时就能得到BoundSql
第二段sql,动态sql,执行时速度稍慢,运行时才能得到BoundSql
所以为了区分这两种类型的SqlNode集合
静态sql: RawSqlSource
当所有节点都是StaticTextSqlNode 或 MixedSqlNode ,就是RawSqlSource 静态sql源(不需要依据请求参数来做判断拼接sql,是固定的sql内容,如果有请求参数给statement赋值参数即可)
动态sql: DynamicSqlSource
只要包含除StaticTextSqlNode 和 MixedSqlNode 以外的其他8 种SqlNode类型 (sql中存在 ${}占位符的是TextSqlNode),则都是DynamicSqlSource 动态sql源(需要根据请求参数做动态sql拼接)
所以不同的SqlSource得到BoundSql的速度不一样,然后相同的是SqlSource下面都是放的SqlNode集合
有细心的同学看了肯定会说我漏了StaticSqlSource,其实StaticSqlSource是上面两种SqlSource生成BoundSql的一个过渡产物,所以不需要单独拎出来说明
2.4 LanguageDriver
mybatis除了可以通过xml写sql外,也可以通过如下java 注解来写sql,还可以通过freemarker、thymeleaf 等格式来写书写sql文件
@Update({"<script>",
"update Author",
" <set>",
" <if test='username != null'>username=#{username},</if>",
" <if test='password != null'>password=#{password},</if>",
" <if test='email != null'>email=#{email},</if>",
" <if test='bio != null'>bio=#{bio}</if>",
" </set>",
"where id=#{id}",
"</script>"})
void updateAuthorValues(Author author);
@Select("SELECT * FROM BLOG")
List<Blog> selectBlog();
所以顾名思义,语言驱动 LanguageDriver的作用就是干这个,将不同来源的sql解析成SqlSource对象,不过mybatis java注解的sql也是统一用的XmlLanguageDriver去解析的,这里mybatis是为了方便扩展
2.5 MappedStatement
除了子节点SqlNode集合以外,<select> <update> <delete> 标签也包含很多属性,放到哪里呢,新开一个父级的SqlNode吗?而且从面向对象设计来说,这个Node跟下面的sql语句node区别还挺大的,至少跟上文那10种SqlNode差别挺大的,这里新开一个对象用于存放父级标签的属性:MappedStatement
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
sql语句的配置,每一段curd都会被解析成一个MappedStatement对象,可以通过id去与dao接口方法进行对应
这里的中间产物我们就叫他MappedStatement,为什么叫MappedStatement?
即mybatis最终生成jdbc statement的中间产物,mybatis做的事情就是 orm (object relational mapping),那么最终生成statement的中间物就是MappedStatement
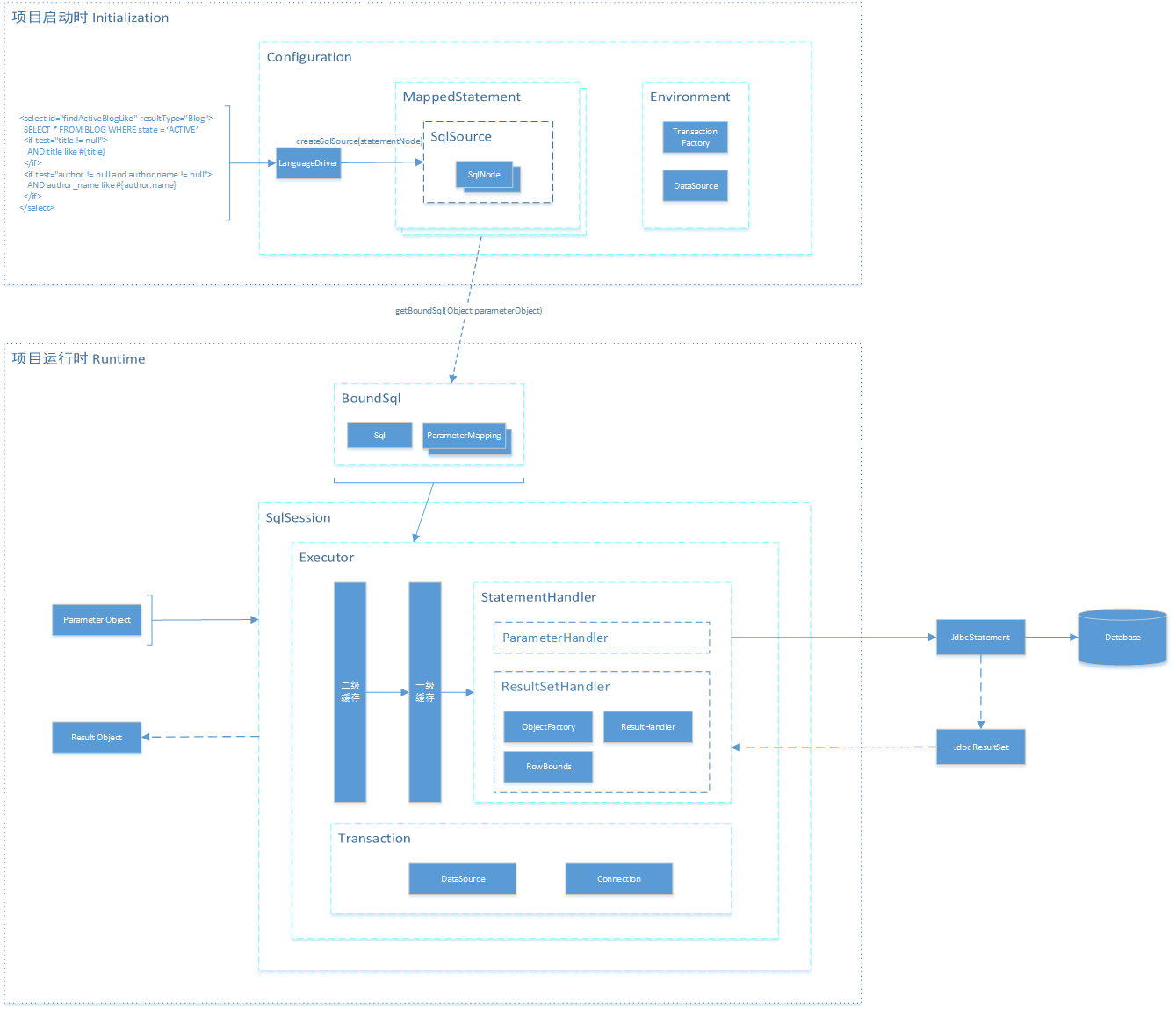
如下图所示(右键新标签页打开可查看大图)
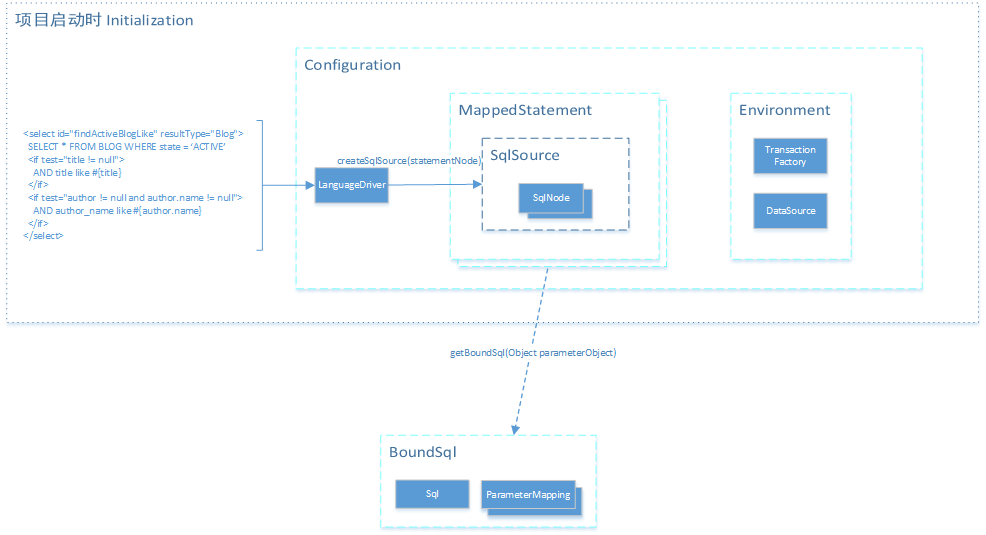
注: 虚线箭头表示此对象为通过某方法得到的返回值
例如:MappendStatement.getBoundSql(Object requestObject)得到的返回值为BoundSql对象
另外,每一段<select|insert|update|delete> 标签,对应生成一个SqlSource、MappedStatement,1对1的关系
ParameterType
用于说明请求参数的java type,非必须,xml的<select|insert|update|delete>标签中该属性可以不写,因为mybatis可以根据运行时传递进来的参数用反射判断其类型
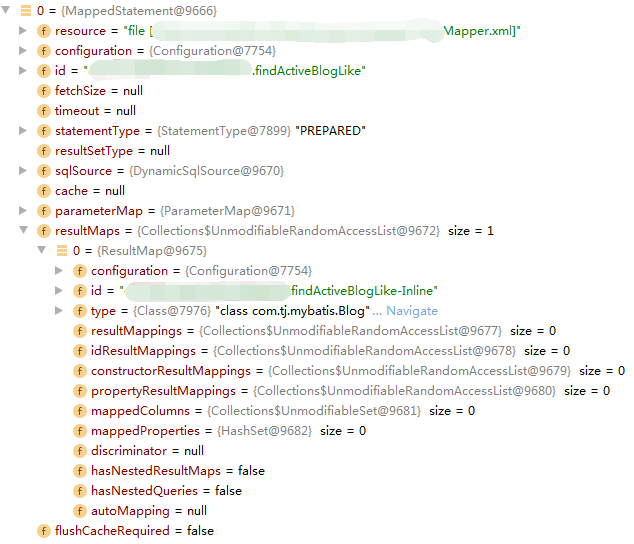
ResultMap ResultType
如官方文档所说,两者只能用其中一个,不过不管用哪个,最终都是将信息放在ResultMap,用于后面ResultSetHandler创建返回对象时使用
例如如下xml配置:
<select id="findActiveBlogLike" resultType="xxx.Blog">
生成的MappedStatement中,上面resultType会存放在ResultMap对象的type属性里
2.6 TransactionFactory
顾名思义其主要就是用于创建不同的Transaction对象,这里涉及到mybatis的事务管理,关于事务管理下面内容我们会提到
3.StatementHandler
我们已经知道上面Configuration对象里面有哪些内容,然后结合BoundSql就能够将statement prepare 和 execute
如下伪代码示例:
Transaction transaction = configuration.getEnvironment().getTransactionFactory().newTransaction(dataSource, TransactionIsolationLevel.READ_COMMITTED, false);
Connection connection = transaction.getConnection();
MappedStatement mappedStatement = configuration.getMappedStatement("findActiveBlogLike");
BoundSql boundSql = mappedStatement.getBoundSql(blog);
PreparedStatement statement = connection.prepareStatement(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
MetaObject metaObject = configuration.newMetaObject(parameterObject);//MetaObject是mybatis提供的能很方便使用反射的工具对象
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
Object value = metaObject.getValue(parameterMapping.getProperty());
statement.setBigDecimal(i, new BigDecimal(value));
}
}
statement.execute();
ResultSet rs=statement.getResultSet();
while(rs.next()){
BigDecimal id = rs.getBigDecimal("id");
String title = rs.getString("title");
}
rs.close();
statement.close();
connection.close();
我们知道,jdbc的statement有三种,每种执行起来有些区别:
Statement
Statement stm = conn.createStatement() return stm.execute(sql);
PreparedStatement
PreparedStatement pstm = conn.prepareStatement(sql); pstm.setString(1, "Hello"); return pstm.execute();
CallableStatement
CallableStatement cs = conn.prepareCall("{call xxx(?,?,?)}");
cs.setInt(1, 10);
cs.setString(2, "Hello");
cs.registerOutParameter(3, Types.INTEGER);
return cs.execute();
所以这里抽象出三个不同的Handler再部分结合模板方法去处理不同的statement,也挺好理解,最后不管什么Statement都按如下模板来构建:
stmt = handler.prepare(transaction.getConnection(), transaction.getTimeout());
handler.parameterize(stmt);
区别是不同的hanlder里的prepare()和parameterize()方法有些区别而已,例如StatementHandler的parameterize()方法里代码为空,因为不支持参数设置
有了StatementHandler之后,我们的伪代码变成下面这样:
StatementHandler handler = configuration.newStatementHandler(mappedStatement, parameterObject, boundSql); Statement stmt = handler.prepare(transaction.getConnection(), transaction.getTimeout()); handler.parameterize(stmt); handler.update(stmt); StatementHandler handler1 = configuration.newStatementHandler(mappedStatement, parameterObject, boundSql);
Statement stmt1 = handler.prepare(transaction.getConnection(), transaction.getTimeout());
handler1.parameterize(stmt);
handler1.query(stmt1, resultHandler);
transaction.getConnection().commit();
newStatementHandler() 创建的StatementHandler默认是PreparedStatementHandler,也可以在xml的<select|insert|update|delete>标签中自己声明类型
3.1 ParameterHandler
StatementHandler.parameterize()方法中的逻辑,交由ParameterHandler去执行,即循环BoundSql的ParameterMapping集合,结合TypeHandler给statement赋值
3.2 ResultSetHandler
顾名思义,StatementHandler执行完statement后,交由ResultSetHandler处理成xml中CRUD标签ResultType ResultMap所声明的对象
关于xml标签中的ResultMap和ResultType,先回顾一下我们上面MappedStatement的内容:
不管是用ResultMap还是ResultType,最终都是将信息放在ResultMap里,ResultType会存放在ResultMap对象的type属性里
关于返回结果:
如果是 <select>标签,这里统一返回List<ResultType> 集合,如果结果只有一条,则直接list.get(0)就可以了
如果是 <insert|update|delete>标签,则不会经过ResultSetHandler处理,statementHandler直接通过statement.getUpdateCount() 返回int值
1.创建返回ResultMap 、ResultType的对象 (ObjectFactory)
2.循环ResultSet每行,再循环每列,给对象属性进行赋值 (TypeHandler)
3.如果是集合添加到集合再返回 (ResultHandler)
伪代码如下:
ResultSet rs = statement.getResultSet(); List<Object> list = objectFactory.create(List.class); while (rs.next()) { ResultSetMetaData metaData = rs.getMetaData(); final int columnCount = metaData.getColumnCount(); Object resultObject = objectFactory.create(resultMap.getType());//使用ObjectFactory实例化对象 MetaObject metaObject = configuration.newMetaObject(resultObject);//MetaObject是mybatis提供的能很方便使用反射的工具对象 for (int i = 1; i <= columnCount; i++) { String columnName = configuration.isUseColumnLabel() ? metaData.getColumnLabel(i) : metaData.getColumnName(i); String property = metaObject.findProperty(columnName, configuration.isMapUnderscoreToCamelCase()); if (property != null && metaObject.hasSetter(property)) { Class<?> propertyType = metaObject.getSetterType(property); TypeHandler<?> typeHandler = getTypeHandler(propertyType, metaData.getColumnType(i));//通过属性类型找对应的jdbc TypeHandler Object value = typeHandler.getResult(rs, columnName); metaObject.setValue(property, value); } } list.add(resultObject); }
ResultSetHandler配合ResultMap也支持嵌套查询、子查询,返回多结果集等,我们这里就不细化了
ObjectFactory
顾名思义,对象工厂,产出对象用的,什么对象呢,当然是查询数据库将结果映射到的java对象
用来创建ResultType(等同于ResultMap中的Type)等对象时使用,用反射创建对象(这里可以做一些加工,比如创建完对象后给属性赋值,但是这种情况不常见),
然后后面ResultSetHandler用TypeHandler去给新创建的对象属性赋值
最后再用ResultHandler添加到返回集合里
什么场景适合我们自定义实现呢?
这里的职责就是通过反射创建对象,一般情况下使用默认的DefaultObjectFactory就可以了;
如果想创建完对象给一些属性初始化值,这里可以做,但是可能会被后面数据库查到的结果值覆盖,使用下面的ResultHandler就可以实现
ResultHandler
为什么需要ResultHandler?
区别于ResultSetHandler,ResultSet是jdbc返回的结果集,Result则理解为经过mybatis加工的结果
默认ResultSetHandler都会循环ResultSet然后通过DefaultResultHandler添加到集合,最后从ResultHandler取结果返回给调用方法(调用方法无返回类型限制)
上面伪代码中,如下几句就是在DefaultResultHandler中执行:
List<Object> list = objectFactory.create(List.class);
list.add(resultObject);
只不过最后ResultSetHandler返回结果时自己调用了 defaultResultHandler.getResultList() 来进行返回。
如果想用自定义的ResultHandler:查询方法必须是void类型,且入参有ResultHandler对象,然后结果集自己通过resultHandler来获取,例如DefaultResultHandler.getResultList()
什么场景适合我们自定义实现呢?
因为这里的职责是创建返回集合List<ResultType>,并添加记录行;所以我们可以对集合里创建的对象进行一些统一的操作,例如给集合里的对象某个字段设置默认值
RowBounds
mybatis的内存分页,在ResultSetHandler中使用,由外部方法层层传递进来,即通过RowBounds设置的参数对ResultSet进行 skip limit,只取想要页数的记录行
但是关键问题是基于内存的分页,而不是物理分页,所以基本上都不会用到
MetaObject
上面我们已经提到了,MetaObject是mybatis提供的方法使用反射的工具类,将对象Object扔进去,就可以很简单的使用反射;自己项目中如果有需要也可以直接使用,很方便
MetaObject metaObject = configuration.newMetaObject(parameterObject);
metaObject.getValue("name");
需要注意的是此对象并不属于我们StatementHandler,只是这里用到比较多,所以我们就放到这里一起讲一下
4.Executor
熟悉mysql、mssql等关系型数据库隔离级别的同学都知道,数据库的隔离级别分为4类,由低到高:
1.Read Uncommitted 读未提交
2.Read Committed 读已提交
3.Repeatable Read 可重复读
4.Serializable 串行
隔离级别越高则处理速度越慢,隔离级别越低则处理速度越快。
mysql默认隔离级别是Repeatable Read 可重复读;即在同一个事务范围内,同样的查询语句得到的结果一致。
mybatis的又一大亮点:同一个事务范围内,基于内存实现可重复读。直接在mybatis这里就处理好了,都不用到数据库,这样减轻了数据库压力,且速度更快。
所以mybatis在这里引入了缓存和一些其他操作,而它的媒介就是Executor,是对StatementHandler再做一层封装
Executor executor = configuration.newExecutor(transaction); executor.query(configuration.getMappedStatement("findActiveBlogLike"), parameterObject, rowBounds, Executor.NO_RESULT_HANDLER);
executor.commit()
Executor里的伪代码:
List<E> list; CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);//通过关键对象创建唯一的缓存key list = localCache.getObject(key);//通过缓存key查缓存 if (list == null) { StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); list = handler.<E>query(stmt, resultHandler); localCache.putObject(key, list);//存至缓存 } return list;
就是我们上面所说的,对StatementHandler进行包装,做一些逻辑封装
然后Executor有哪几种呢?主要还是知道这些对象是如何演变过来的,剩下的其实代码里都能看的很明确了
| Executor | 说明 |
| BaseExecutor | 下面三种Executor的父类,基础方法都在这里,查询方法实现了基于内存的一级缓存 |
| SimpleExecutor | 继承自BaseExecutor,默认的Executor |
| ResuseExecutor | 继承自BaseExecutor,重用Statement,即同一个Executor内Statement不释放重复使用 |
| BatchExecutor | 继承自BaseExecutor,针对增删改的批处理,调用增删改方法时,只是statement.addBatch(),最终还要通过调用commit方法触发批处理 |
| CachingExecutor | 在一级缓存的基础上增加二级缓存,二级缓存查不到的情况再去上面几种Executor中进行查询 |
Transaction
为什么mybatis要抽象出Transaction事务对象,其实一方面是为了集中connection的管理,另一方面也是为了能够适应趋势解决事物发展过程中的问题,后面mybatis-spring中我们会详细介绍。
spring关于事务的管理有:
DataSourceTransactionManager、PlatformTransactionManager等
mybatis这里同样也有自己的事务管理 Transaction接口的实现:JdbcTransaction 、SpringManagedTransaction等
相比spring表面看起来只是后缀少了个单词 Manager而已
简单点去理解,就是connection都是放在Transaction对象这里进行管理,要操作数据库连接都统一从这里操作;
例如非托管的Transaction伪代码如下:
protected Connection connection;
public Connection getConnection(){
if (connection == null) {
connection = dataSource.getConnection();
}
return connection;
}
如果是受spring 托管的事务,则上面dataSource.getConnection() 变成 DataSourceUtils.getConnection();
一级缓存
一级缓存:默认开启,且不能关闭,同一个Executor内(同一个事务)相同参数、sql语句读到的结果是一样的,都不用到数据库,这样减轻了数据库压力,且速度更快。
二级缓存
CacheExecutor,可基于内存或第三方缓存实现
要注意的是二级缓存的key 是通过 mapper.xml 里的namespace进行分组,例如:
<mapper namespace="UserMapper"> <cache eviction="FIFO" size="512" readOnly="true"/>
这样所有该mapper <select>产生的cacheKey,都统一放在"UserMapper"这个namespace下汇总
mapper.xml里面的<select|insert|update|delete> flushCache属性设置为true时,会清空该namespace下所有cacheKey的缓存
flushCache属性在<select> 标签中默认值为 false,在<insert|update|delete>标签中默认值为 true。
然后如果其他mapper想共用同一个缓存namespace,如下声明就可以了
<mapper namespace="BlogMapper"> <cache-ref namespace="UserMapper"/>
5.SqlSession
mybatis为什么要有session的概念? 上面使用Executor进行crud已经可以满足我们绝大部分业务需求了,为什么还要弄出个session的概念?
这里主要还是为了强调会话的概念,由会话来控制事务的范围,类似web 的session更方便使用者理解
那既然这样,把上面Executor名字改成SqlSession不就行了?这样其实也不好,因为对应的BatchExecutor、CachingExecutor改成BatchSqlSession、CachingSqlSession的话感觉有点混乱了,不符合session干的事情
使用SqlSession后代码如下:
SqlSession session = sqlSessionFactory.openSession();//内部构造executor等对象 session.selectList("findActiveBlogLike",parameterObject);//内部使用Executor进行执行 session.commit();
session.close();
其实跟上面Executor的代码相比,也差不多,只不过SqlSessoin是通过factory工厂来创建,但是原理还是通过configuration创建transaction、executor等对象
Executor executor = configuration.newExecutor(transaction); executor.query(configuration.getMappedStatement("findActiveBlogLike"), parameterObject, rowBounds, Executor.NO_RESULT_HANDLER); executor.commit();
executor.close();
到这里可以这样理解,SqlSession就是为了更方便理解和使用而产生的对象,其方法本质还是交由Executor去执行。
到目前为止整体的架构如下(右键新标签页打开可查看大图)
SqlSessionFactory
SqlSession的工厂类,需要的参数主要就是Configuration对象,其实意思很明确了,就是SqlSession需要使用Configuration对象,创建SqlSession代码如下
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
SqlSession session = sqlSessionFactory.openSession();
不过configuration的构建其实还是挺麻烦的,上面Configuration已经提到,然后后面mybatis-spring有提供SqlSessionFactoryBean(包含Configuration的构建)方便我们更快捷的构建SqlSessionFactory
6.MapperProxy
熟悉mybatis的朋友都知道xml中每段<select|insert|update|delete>与dao接口方法是一对一的,其实早在ibatis的年代是没有将两者关联起来的

java.lang.reflect.Proxy
那么实现这一功能的核心是什么呢,就是java的Proxy,通过session.getMapper(xxx.class)方法每次都会给接口生成一个代理Proxy的实现
实现后的效果:
try (SqlSession session = sqlSessionFactory.openSession()) {
IBlogMapper mapper = session.getMapper(IBlogMapper.class);
Blog blog = mapper.selectBlog(101);
}
这里我们就不分析Proxy的原理了,还是不明白的同学可以百度搜索了解一下,如下是mybatis中使用proxy的代码:
DefaultSqlSession:
public <T> T getMapper(Class<T> type) { return configuration.<T>getMapper(type, this); }
经由Configuration和MapperRegistry、MapperProxyFactory,最终执行返回:
protected T newInstance(MapperProxy<T> mapperProxy) { MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache); return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy); }
不过需要注意的是getMapper(xxx.class)的使用前提的addMapper(xxx.class);否则不会生成代理;
addMapper可以由如下两种形式触发:
1.configuration.addMapper(xxx.Class);//基于java注解形式
2.xmlMapperBuilder.parse();//基于mapper.xml配置,详细代码如下
Configuration configuration = new Configuration(environment);
Resource[] mapperLocations = new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*.xml"); if (!isEmpty(mapperLocations)) { for (Resource mapperLocation : mapperLocations) { ... try { XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(mapperLocation.getInputStream(), configuration, mapperLocation.toString(), configuration.getSqlFragments()); xmlMapperBuilder.parse(); ... } }
后面结合mybatis-spring时使用SqlSessionFactoryBean时就有帮我们实现了我们上面这段代码
MapperMethod
MapperProxy最后执行方法时,都会交给MapperMethod去执行,接口的每个方法method都会生成一个对应的MapperMethod去执行
@Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { ... final MapperMethod mapperMethod = cachedMapperMethod(method); return mapperMethod.execute(sqlSession, args); }
然后只要在MapperMethod里调用SqlSession对应的方法就算完成了:
public Object execute(SqlSession sqlSession, Object[] args) { Object result; //通过接口方法名找到对应的MappedStatement,判断MappedStatement的标签类型是其中哪种<select|insert|update|delete> switch (command.getType()) { case INSERT: { Object param = method.convertArgsToSqlCommandParam(args); //调用对应的sqlSesion方法,传递MappedStatement id和请求参数,这里的command.getName即MappedStatement的id(前缀会自动加命名空间来区分唯一) result = rowCountResult(sqlSession.insert(command.getName(), param)); break; } case UPDATE: { Object param = method.convertArgsToSqlCommandParam(args); result = rowCountResult(sqlSession.update(command.getName(), param)); break; } case DELETE: { Object param = method.convertArgsToSqlCommandParam(args); result = rowCountResult(sqlSession.delete(command.getName(), param)); break; } case SELECT: if (method.returnsVoid() && method.hasResultHandler()) { executeWithResultHandler(sqlSession, args); result = null; } else if (method.returnsMany()) { result = executeForMany(sqlSession, args); } else if (method.returnsMap()) { result = executeForMap(sqlSession, args); } else if (method.returnsCursor()) { result = executeForCursor(sqlSession, args); } else { Object param = method.convertArgsToSqlCommandParam(args); result = sqlSession.selectOne(command.getName(), param); } break; case FLUSH: result = sqlSession.flushStatements(); break; default: throw new BindingException("Unknown execution method for: " + command.getName()); } if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) { throw new BindingException("Mapper method '" + command.getName() + " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ")."); } return result; }
其中就是select类型的方法复杂些,需要判断接口里的参数来去调用对应的SqlSession方法。
简单点理解,就是调用mapper接口的方法,最后会被代理实现为调用对应的 sqlSession.select() 或 sqlSession.insert() 等对应的方法。
流程图如下(右键新标签页打开可查看大图)
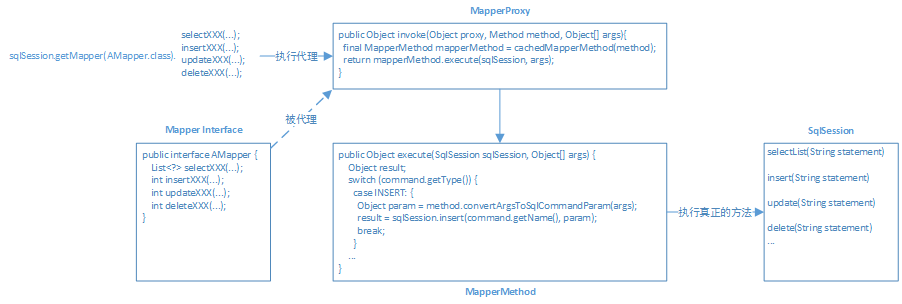
最后调用的这个sqlSession从哪来?
在sqlSession.getMapper(xxx.class)时,会将sqlSession存到代理MapperProxy的属性,然后MapperProxy调用MapperMethod时,会传递给MapperMethod去使用,即
//通过Proxy为接口生成并返回代理实现类MapperProxy,并将当前sqlSession存至代理实现类MapperProxy的属性 IBlogMapper mapper = session.getMapper(IBlogMapper.class); //调用具体方法时,MapperProxy会调用MapperMethod来判断执行对应的sqlSession.select 或 insert等方法,且此sqlSession就是上面生成代理类的sqlSession,是同一个 Blog blog = mapper.selectBlog(101);
如果是通过SqlSessionTemplate(后面mybatis-spring内容).getMapper(),则后面调用的sqlSession就是SqlSessionTemplate对象
然后这里还有一点小细节,我们可以在生成代理实现类MapperProxy时,就可以遍历接口的方法来提前生成好所有的MapperMethod【饿汉】,但是其实mybatis是在具体调用接口方法时,才生成对应的MapperMethod并缓存到内存【懒汉】 ;具体利弊我们这里就不做分析了。
7.Mybatis的插件
首先我们为什么需要插件,哪里需要用到插件?其本质也是通过Proxy做一层代理
public class InterceptorChain { private final List<Interceptor> interceptors = new ArrayList<Interceptor>(); public Object pluginAll(Object target) { for (Interceptor interceptor : interceptors) { target = interceptor.plugin(target); } return target; } public void addInterceptor(Interceptor interceptor) { interceptors.add(interceptor); } public List<Interceptor> getInterceptors() { return Collections.unmodifiableList(interceptors); } }
Interceptor示例:
public class XXXInterceptor implements Interceptor { public Object plugin(Object target) { return Plugin.wrap(target, this); } public Object intercept(Invocation invocation) { } }
Plugin代码:
public class Plugin implements InvocationHandler { public static Object wrap(Object target, Interceptor interceptor) { Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor); Class<?> type = target.getClass(); Class<?>[] interfaces = getAllInterfaces(type, signatureMap); if (interfaces.length > 0) { return Proxy.newProxyInstance( type.getClassLoader(), interfaces, new Plugin(target, interceptor, signatureMap)); } return target; } public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { try { Set<Method> methods = signatureMap.get(method.getDeclaringClass()); if (methods != null && methods.contains(method)) { return interceptor.intercept(new Invocation(target, method, args)); } return method.invoke(target, args); } catch (Exception e) { throw ExceptionUtil.unwrapThrowable(e); } } }
我们上面已经接触了很多使用Proxy的场景了,这里又是熟悉的配方,熟悉的味道。
一共有四个地方可以使用插件,即可以被代理,当然被代理对象的所有方法都可以被拦截:
Executor
StatementHandler
ParameterHandler
ResultSetHandler
mybatis比较经典的插件使用还是 pagehelper ,然后关于 插件拦截的使用规范 在 pagehelper官方文档 中也讲的很透彻很详细,我相信在弄懂了本文mybatis原理后再去看 pagehelper这类插件源码也会比较容易懂
8.Mybatis的扩展
由于我们基本上每个表都要用到一些增删改查方法,然后我们生成代码时,总是会生成一堆类似的代码,xml文件、mapper接口中存在大量相似代码,有没有办法把这些代码抽出来?
这时候mybatis-plus就出现了,其原理其实就是在mybatis 构建Configuration对象时做了加工,帮我们把增删改查的MappedStatement添加进去;当然mybatis-plus还包含很多其它便捷的功能,但是也是也是基于mybatis做扩展。
还是那句话,我们把mybatis原理分析清楚了,这块也就更容易去理解了,感兴趣的同学可以从mybatis-plus的MybatisSqlSessionFactoryBean为源头进去看
二、mybatis-spring抽象出来的关键对象
我们要知道mybatis 和 mybatis-spring是分开的两个项目,然后又可以无缝的结合起来进行使用,但是为了便于我们理解,所以我们是分开进行分析,这样更有利于吸收
与spring结合之前我们必须得熟悉一下spring的数据访问与实务管理
1.事务管理的发展史
其实spring关于数据访问、事务管理已经做得很好了,但是其中的发展史是怎样的,对于理解mybatis的事务管理非常重要
我们简单概括一下关于事务的发展过程中的几个典型问题,尽量能够让大家回顾一下发展过程:
1.局部事务的管理绑定了具体的数据访问方式
问题描述:即connection-passing问题,不同方法想要共用事务需要在方法间传递connection,如果使用jdbc则传递connection对象,如果使用hibernate则需要传递session或transaction对象,不同的数据访问形式要用不同的api来控制局部事务,这样我们的方法就业务层就没办法和数据访问解耦
解决方法:connection绑定到线程ThreadLocal,在业务开始方法获取连接,业务结束方法提交、释放连接
2.事务管理代码与业务逻辑代码相互混杂
问题描述:上面问题1虽然解决了方法间传递数据库连接的问题,但是事务的管理还是在业务代码里,且需要合理控制,否则也会有问题
解决方法:面向切面编程,事务的切面管理(spring @Transactional)
如果还是不是很理解的朋友, 推荐去看一下《spring 揭密》一书里的数据访问和事务管理相关章节,增加这一块的感知和认识,会有助于平滑的理解mybatis-spring的事务管理
2.Spring 之 DataSourceUtils、@Transactional
使用spring事务,注册相关的bean:
@Bean public DataSourceTransactionManager transactionManager() { DataSourceTransactionManager dstm = new DataSourceTransactionManager(); dstm.setDataSource(dataSource); return dstm; } @Bean public BasicDataSource dataSource() { BasicDataSource bds = new BasicDataSource(); bds.setDriverClassName(""); bds.setUrl(""); bds.setUsername(""); bds.setPassword(""); return bds; }
具体的使用,注意TransactionManager和DataSourceUtils里使用的dataSource是同一个,不然事务不生效:
@Transactional public void methodA(){ //简单理解就是从ThreadLocal获取数据库连接,如果没有就从DataSource获取后set到ThreadLocal Connection connection = DataSourceUtils.getConnection(dataSource); PreparedStatement statement = connection.prepareStatement("insert into blog xxx"); statement.executeUpdate(); methodB(); }//@Transactional切面after:当前ThreadLocal的connection自动commit,并release DataSourceUtils ThreadLocal中的connection public void methodB(){ Connection connection = DataSourceUtils.getConnection(dataSource); PreparedStatement statement = connection.prepareStatement("insert into log xxx"); statement.executeUpdate(); }
如果方法不在@Transactional事务控制范围内
需要注意的是如果方法不在@Transactional事务控制范围内,通过DataSourceUtils.getConnection还是会存在ThreadLocal,只不过ThreadLocal中的connection就需要我们手动去 commit和release,当然DataSourceUtils有方法供我们调用。
DataSourceUtils中的伪代码:
private final ThreadLocal<Connection> tlConnection = new ThreadLocal<Connection>(); public static Connection getConnection(DataSource dataSource){ if (tlConnection.get() == null) { tlConnection.set(dataSource.getConnection()); } return tlConnection.get(); } public static void releaseConnection(){ tlConnection.get().close(); tlConnection.set(null); }
@Transactional切面实现的伪代码,需要结合TransactionManager和DataSourceUtils来使用,这里简化如下:
@After public void after(JoinPoint joinPoint){ commitConnection(); DataSourceUtils.releaseConnection(); }
结合spring事务时,connection数据库连接在线程中的生命周期如下,即随着事务开始而开始,随时事务结束而结束
要注意ThreadLocal中set Connection是在@Transactional切面的before方法,提前就已经建立了connection

使用spring的数据访问和事务管理就解决了我们上面所提到的两个问题:
1.局部事务的管理绑定了具体的数据访问方式
2.事务管理代码与业务逻辑代码相互混杂
其实mybatis项目一直抽象到SqlSession,都没有解决事务管理发展的那两个问题
多个方法如果想要共用SqlSession需要通过参数传递,且事务的提交也要我们自己写在业务代码里,如下:
public void methodA(){ SqlSession session = sqlSessionFactory.openSession(); session.insert("insertBlog",xxx); methodB(session); } public void methodB(SqlSesion session){ session.insert("insertUser",xxx); session.commit(); session.close(); }
3.SpringManagedTransaction
我们上文已经知道mybatis的Transaction对象是用来获取、操作connection,但是也仅限于单个Executor、SqlSession内部,没有放到线程ThreadLocal里去,要想共用同一个connection事务,还是必须参数传递SqlSession或者Connection对象(即上面的问题1),如何解决?我们把Transaction里的connection放到ThreadLocal不就解决了吗?
那我们直接把Transaction对象里的getConnection方法改一下不就行了
private final ThreadLocal<Connection> tlConnection = new ThreadLocal<Connection>(); public Connection getConnection(){ if (tlConnection.get() == null) { tlConnection.set(this.dataSource.getConnection()); } return tlConnection.get(); }
发现是不是跟DataSourceUtils的getConnection方法一模一样,所以结合spring的数据访问的话,可以精简成:
public Connection getConnection(){ return DataSourceUtils.getConnection(this.dataSource); }
上面这段伪代码其实就是SpringManagedTransaction所干的事情
4.SqlSessionUtils
然后我们结合@Transactional使用,我们来看看代码:
@Transactional public void methodA(){ TransactionFactory transactionFactory = new SpringManagedTransactionFactory();
Transaction transaction = transactionFactory.newTransaction(dataSource);
Connection connection = transaction.getConnection();
PreparedStatement statement = connection.prepareStatement("insert into blog xxx");
statement.executeUpdate();
methodB(transaction);
}
public void methodB(Transaction transaction){
Connection connection = transaction.getConnection();
PreparedStatement statement = connection.prepareStatement("insert into user xxx");
statement.executeUpdate();
}
上面代码解决了问题2,但是没解决问题1,是不用传递connection了,但是现在又要传递transaction。
类似connection,我们创建一个TransactionUtils工具类将transaction也绑定到ThreadLocal不就解决问题了?
@Transactional public void methodA(){ Connection connection = TransactionUtils.getTransaction().getConnection(); PreparedStatement statement = connection.prepareStatement("insert into blog xxx"); statement.executeUpdate(); methodB(); } public void methodB(){ Connection connection = TransactionUtils.getTransaction().getConnection(); PreparedStatement statement = connection.prepareStatement("insert into user xxx"); statement.executeUpdate(); }
TransactionUtils的伪代码:
private final ThreadLocal<Transaction> tlTransaction = new ThreadLocal<Transaction>(); public static Transaction getTransaction(){ if (tlTransaction.get() == null) { TransactionFactory transactionFactory = new SpringManagedTransactionFactory(); Transaction transaction = transactionFactory.newTransaction(dataSource); tlTransaction.set(transaction); } return tlTransaction.get(); } public static void releaseTransaction(){ tlTransaction.get().connection.close(); tlTransaction.set(null); }
问题并没有结束,我们要用的是mybatis的SqlSession,你这样不是又回到原始的jdbc了,行我们继续改,同样类似DataSourceUtils我们再建个SqlSessionUtils行了吧:
@Transactional public void methodA(){ SqlSession sqlSession = SqlSessionUtils.getSqlSession(sqlSessionFactory); sqlSession.insert("insertBlog",xxx); methodB(); } public void methodB(){ SqlSession sqlSession = SqlSessionUtils.getSqlSession(sqlSessionFactory); sqlSession.insert("insertUser",xxx); }
SqlSessionUtils里的伪代码:
private final ThreadLocal<SqlSession> tlSqlSession = new ThreadLocal<SqlSession>(); public static SqlSession getSqlSession(SqlSessionFactory factory){ if (tlSqlSession.get() == null) { SqlSession sqlSession = factory.openSession(); tlSqlSession.set(sqlSession); } return tlSqlSession.get(); }
现在SqlSession里的connection已经通过SpringManagedTransaction打通spring的DataSourceUtils存到ThreadLocal,且@Transactional注解切面after会自动connection.commit(); 且释放ThreadLocal资源(SqlSession)
但是还有一个问题:
同一个spring事务我们是使用相同的SqlSession了,但是我们想要的是@Transactional注解切面after自动实现sqlSession.commit() 而不是 connection.commit();其实SqlSession.commit()主要也是实现connection.commit(),这个确实是一点小瑕疵,但是确实是不影响使用。
这样SqlSession的生命周期就实现了类似spring事务里Connection的生命周期,且同connection一样,ThreadLocal中set SqlSession是在业务代码中第一次获取SqlSession时,而不是@Transactional切面的before方法,在必须时才去获取,而不是提前获取资源。
需要注意的是源码中SqlSessionUtils不是直接将SqlSession存在ThreadLocal,而是和spring的DataSourceUtils一样,通过spring的TransactionSynchronizationManager来存储到ThreadLocal,这里为了便于理解我们直接进行了简化。
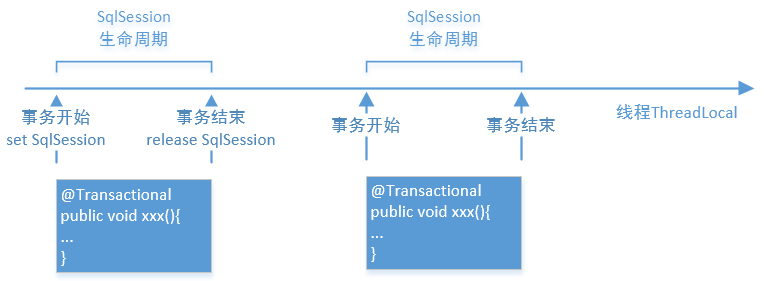
如果不使用@Transactional注解进行事务管理的话怎么使用SqlSessionUtils
SqlSession依然会帮我们存到ThreadLocal,不过同DataSourceUtils一样就需要我们手动commit和release;因为没人帮我们干这个事情了,需要我们自己处理。当然SqlSessionUtils有提供方法供我们自己调用。
例如下面代码,如果这样写是不是就有问题了?就没人帮我们commit和close connection了!
public void methodC(){ SqlSession sqlSession = SqlSessionUtils.getSqlSession(sqlSessionFactory); sqlSession.insert("insertXXX",xxx); }
需要改成如下格式:
public void methodC(){ SqlSession sqlSession = SqlSessionUtils.getSqlSession(sqlSessionFactory); sqlSession.insert("insertXXX",xxx); sqlSession.commit(); SqlSessionUtils.closeSqlSession(sqlSession,sqlSessionFactory); }
这下问题又麻烦了:
1.methodC可能会被其他方法受spring事务控制的方法调用,这样其也会被纳入spring事务范围管理,不需要自己提交connection。
例如如果被上面methodA方法内部调用,@Transactional切面after会在methodA的所有代码(当然包括methodC的代码)执行完后自动提交connection
2.如果直接调用methodC,其本身又不在spring事务管理范围,需要自己提交connection。
我们有没有办法判断当前方法是否在@Transactional事务范围内,如果在事务范围内,就不处理,交由事务去提交;如果不在事务范围内,就自己提交?
5.SqlSessionTemplate
上述问题我们做一下判断,伪代码如下:
public void methodC(){ SqlSession sqlSession = SqlSessionUtils.getSqlSession(); sqlSession.insert("insertXXX",xxx); if(isSqlSessionTransactional(sqlSession,sqlSessionFactory)){//判断当前sqlSession是否在spring @Transactional事务管理范围内 //donothing }else{ sqlSession.commit(); sqlSession.close(); } }
如何判断当前sqlSession是否在spring @Transactional事务管理范围内呢?如果感兴趣的话可以直接去看一下源码,我们这里就不啰嗦了
然后上面这段判断代码我们不可能每个方法里都写一遍吧,有没有办法提取出来,我们就不绕弯子了,直接看优雅的SqlSessionTemplate:
public void methodC(){ SqlSessionTemplate sqlSessionTemplate=new SqlSessionTemplate(sqlSessionFactory); sqlSessionTemplate.insert("insertXXX",xxx); }
又是基于Proxy代理,在执行 SqlSession方法时,都交由代理去处理,SqlSessionTemplate的伪代码:
public class SqlSessionTemplate implements SqlSession, DisposableBean { public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory) { ... this.sqlSessionProxy = (SqlSession) newProxyInstance(SqlSessionFactory.class.getClassLoader(), new Class[] { SqlSession.class }, new SqlSessionInterceptor()); } public int insert(String statement, Object parameter) { return this.sqlSessionProxy.insert(statement, parameter); } private class SqlSessionInterceptor implements InvocationHandler { public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { SqlSession sqlSession = SqlSessionUtils.getSqlSession(sqlSessionFactory); Object result = method.invoke(sqlSession, args);//执行sqlSession对应的方法 if(isSqlSessionTransactional(sqlSession,sqlSessionFactory)){//判断当前sqlSession是否在spring @Transactional事务管理范围内 //donothing }else{ sqlSession.commit(); sqlSession.close(); } } } }

终于,经历了这么多,mybatis-spring终于能够与spring的事务管理比较完美的融合了?
问题仍然还没结束,我们目前的操作也仅限于SqlSession的方法操作,我们上面基于Mapper接口的操作呢,回顾我们上面MapperProxy、MapperMethod,MapperMethod是调用SqlSession相应的方法,怎么才能对接上SqlSessionTemplate
那还不简单:
SqlSessionTemplate sqlSessionTemplate =new SqlSessionTemplate(sqlSessionFactory); IBlogMapper blogMapper = sqlSessionTemplate.getMapper(IBlogMapper.class); blogMapper.selectBlog(101);
6.MapperScannerConfigurer
现在我们结合mybatis-spring来使用SqlSession已经优雅了很多,我们也可以基于MapperProxy来实现上面的MethodA、MethodB的代码,这样就省去了字符串硬编码,这种方式会更好:
@Transactional public void methodA(){ SqlSessionTemplate sqlSessionTemplate = new SqlSessionTemplate(sqlSessionFactory); IBlogMapper blogMapper = sqlSession.getMapper(IBlogMapper.class); blogMapper.insertBlog(xxx); methodB(); } public void methodB(){ SqlSessionTemplate sqlSessionTemplate = new SqlSessionTemplate(sqlSessionFactory); IUserMapper userMapper = sqlSession.getMapper(IUser.class); userMapper.insertUser(xxx); }
我们知道SqlSessionTemplate是基于proxy代理形式实现了对应的功能,那么我们在结合spring使用的时候,能否把这个代理注册成spring的bean呢,就是把sqlSession.getMapper(xxx.class)注册成spring的bean,这样我们就能够使用如下@Autowired这样更优雅的编码:
@Autowired IBlogMapper blogMapper; @Autowired IUserMapper userMapper; @Transactional public void methodA(){ blogMapper.insertBlog(xxx); methodB(); } public void methodB(){ userMapper.insertUser(xxx); }
怎样注册spring bean呢,我们以IBlogMapper接口举例:
public interface IBlogMapper { List<Blog> findActiveBlogLike(Map map); }
手动注册实现类:
public class BlogMapper implements IBlogMapper { @Autowired SqlSessionFactory sqlSessionFactory; @Override public List<Blog> findActiveBlogLike(Map map) { SqlSessionTemplate sqlSessionTemplate = new SqlSessionTemplate(sqlSessionFactory); List<Blog> list = sqlSessionTemplate.selectList("findActiveBlogLike",map); return list; } }
不对啊,这里没有用到MapperProxy代理实现啊,而是自己手动去判断和映射接口需要使用sqlsession的哪个方法了,完全没MapperProxy和MapperMethod的事情啊?这肯定不是我们想要的!
Spring 之 BeanFactoryPostProcessor、BeanDefinitionRegistryPostProcessor
要想给spring动态的注册bean,这就又到了spring bean的生命周期的知识了,我们这里就直接看mybatis-spring使用的什么了,就不啰嗦spring bean生命周期了
@Bean MapperScannerConfigurer mapperScannerConfigurer() { MapperScannerConfigurer msc = new MapperScannerConfigurer(); msc.setBasePackage("xxx"); msc.setAnnotationClass(Mapper.class);//可以设置只注册添加了mybatis @Mapper注解的接口 msc.setSqlSessionFactoryBeanName("sqlSessionFactory"); return msc; }
MapperScannerConfigurer的实现:
public class MapperScannerConfigurer implements BeanDefinitionRegistryPostProcessor ... { public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) { ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry); ... scanner.scan( StringUtils.tokenizeToStringArray(this.basePackage, ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS)); }
...
ClassPathMapperScanner的实现:
public class ClassPathMapperScanner extends ClassPathBeanDefinitionScanner { public Set<BeanDefinitionHolder> doScan(String... basePackages) { Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages); ... processBeanDefinitions(beanDefinitions); ... return beanDefinitions; } private Class<? extends MapperFactoryBean> mapperFactoryBeanClass = MapperFactoryBean.class; private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) { GenericBeanDefinition definition; for (BeanDefinitionHolder holder : beanDefinitions) { definition = (GenericBeanDefinition) holder.getBeanDefinition(); String beanClassName = definition.getBeanClassName(); definition.getConstructorArgumentValues().addGenericArgumentValue(beanClassName); // issue #59 definition.setBeanClass(this.mapperFactoryBeanClass); boolean explicitFactoryUsed = false; if (StringUtils.hasText(this.sqlSessionFactoryBeanName)) { definition.getPropertyValues().add("sqlSessionFactory", new RuntimeBeanReference(this.sqlSessionFactoryBeanName)); explicitFactoryUsed = true; } ... } }
即扫描我们设置的basepackage下的所有符合过滤器规则的接口(例如可以设置只扫描返回带有mybatis @Mapper注解的接口),然后注册成为spring bean,不过注册的bean并不是MapperProxy,而是MapperFactoryBean,好吧,继续往里面看
MapperFactoryBean
public class MapperFactoryBean<T> extends SqlSessionDaoSupport implements FactoryBean<T> { public T getObject() throws Exception { return getSqlSession().getMapper(this.mapperInterface); } public SqlSession getSqlSession() { return new SqlSessionTemplate(sqlSessionFactory); } }
MapperFactoryBean这里实现了FactoryBean接口,实际注册的bean会通过getObject方法返回最终的实现类,终于到了我们的MapperProxy了
@MapperScan @MapperScans
这两个mybatis-spring的注解其实就是用于自动帮我们注册MapperScannerConfigurer 的spring Bean
SqlSessionFactoryBean
我们之前声明SqlSessionFactory时要写一堆代码,现在这个工作交给SqlSessionFactoryBean,其也继承了spring FactoryBean接口,即通过getObject方法返回实际注册的对象:SqlSessionFactory
7.mybatis-spring-boot-starter
mybatis-spring-boot-starter其实就是帮我们做一些自动化的配置,和spring-boot-starter的初衷一样,这一块其实没有什么好讲的,所以我们就附属到mybatis-spring的一个小章节里
该项目pom里引用了mybatis-spring-boot-autoconfigure,其spring.factories如下
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.mybatis.spring.boot.autoconfigure.MybatisLanguageDriverAutoConfiguration,\
org.mybatis.spring.boot.autoconfigure.MybatisAutoConfiguration
MybatisLanguageDriverAutoConfiguration
就是帮我们自动设置LanguageDriver,例如FreeMarkerLanguageDriver、ThymeleafLanguageDriver等,mybatis默认是XMLLanguageDriver
MybatisAutoConfiguration
这里主要自动帮我们注册了SqlSessionFactory、SqlSessionTemplate、MapperScannerConfigurer的Bean
主要还是MapperScannerConfigurer的Bean,就省去了我们之前还要手动去注册MapperScannerConfigurer Bean,不过这里有设置MapperScannerConfigurer 只扫描带有mybatis @Mapper注解的接口。
到目前为止我们绝大多数场景只需要注册一个SqlSessionFactoryBean为 spring bean就可以了
读懂源码不难,讲出来通俗易懂很难,写出来通俗易懂是难上加难,文章写出来不易,还望各位点点推荐,也欢迎评论区交流,你的互动也是我更新和维护的动力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号