第十一章——训练深度神经网络
上一章我们训练了一个浅层神经网络,只要两个隐层。但如果处理复杂的问题,例如从高分辨率图像中识别上百种类的物品,这就需要训练一个深度DNN。也行包含十层,每层上百个神经元,几十万个连接。这绝不是闹着玩的:
- 首先,需要面对梯度消失(或者相对的梯度爆炸)问题,这会导致浅层很难被训练。
- 其次,这么大一个网络,训练速度很慢。
- 最后,一个包含上百万参数的模型,存在很大过拟合的风险。
11.1 梯度消失(爆炸)问题
反向传播算法会计算损失函数关于每一个参数的偏导数,然后使用梯度下降更新参数。不幸的是,反向传播时,梯度经常会逐层越来越小,导致底层权重基本保持不变,从而不能得到好的训练结果。这就是所谓的梯度消失问题。而有时候还可能发生相反的情况:很多层的权重每次修改量很大,导致不能收敛。这就是梯度爆炸问题,主要发生在RNN。更普遍的问题是,深度神经网络往往梯度不稳定,不同的层学习速度差别很大。
这一问题知道2010才有了突破性的进展。在Xavier Glorot和Yoshua Bengio的论文Understanding the Difficulty of Training Deep Feedforward Neural Networks中,作者发现了一些造成这一问题的可能因素,包括logistic sigmoid激活函数和当时流行的随机初始化方式(使用使用均值为0标准差为1的正态分布进行初始化)。他们表明,这一激活函数加上这种初始化方式,使得每一层输出的方差远大于输入。这一情况在使用均值是0.5的logistic函数时变得更为糟糕(双曲正切函数的均值是0,从而在深度网络中表现优于logistic函数)。
观察图11-1的激活函数,随着输入值的绝对值变大,函数值趋近于1和0,此时导数趋近于0。因此在方向传播时,几乎没有导数传回去。
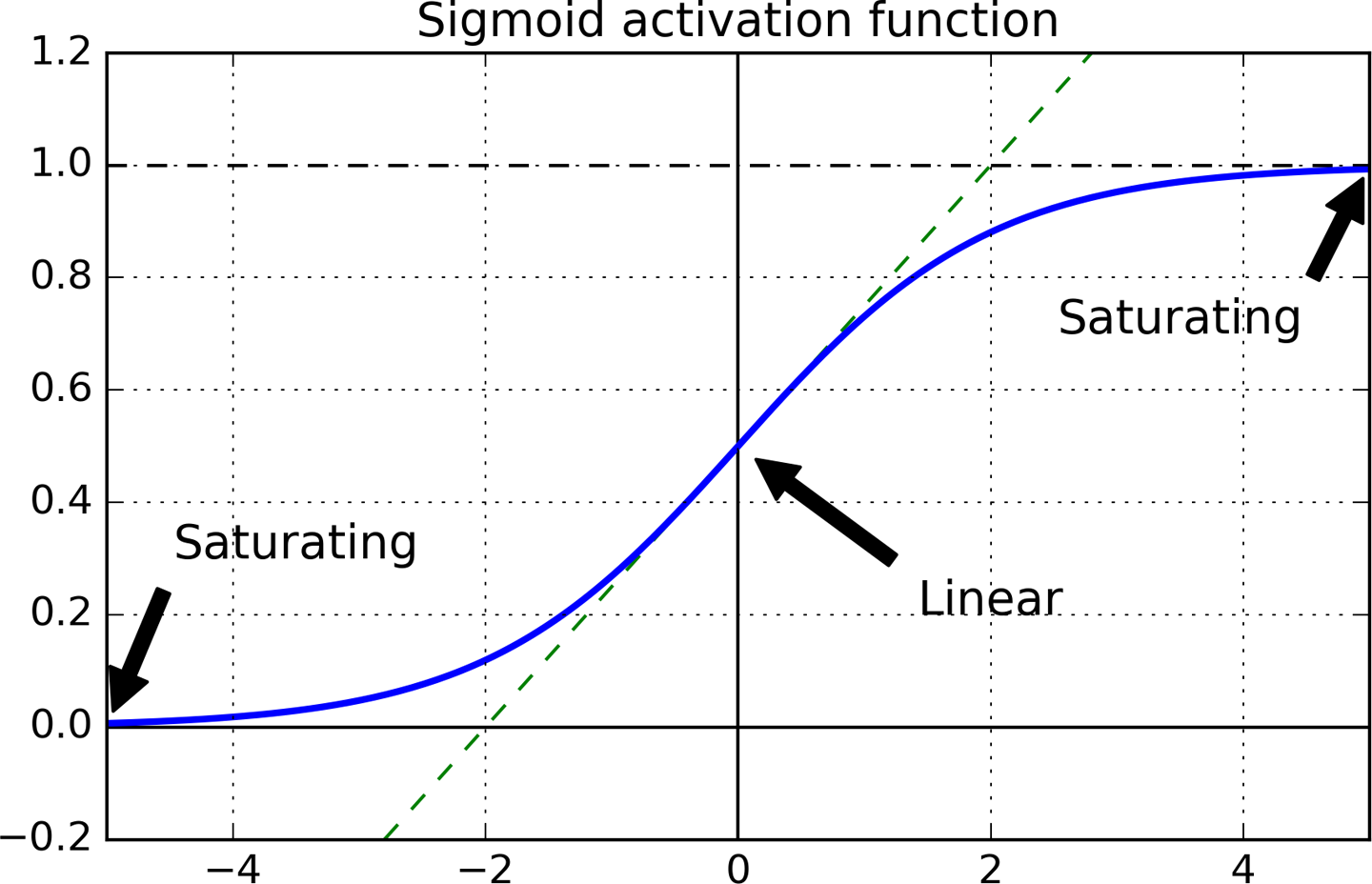
图11-1 Logistic激活函数
11.1.1 Xavier and He Initialization
在其论文中,Glorot and Bengio提供了一种可以显著改善该问题的建议。我们需要信号在两个方向都可以正常的流动:在前向做出预测和反向传播梯度时。我们不希望信号消失,也不希望它保障或者饱和(也就是趋近于某一个值)。为了使信号正常流动,作者主张每一层输入和输出的方差相等,并且在反向传播时梯度的方差保持不变(如果对其中的数学细节感兴趣,可以研究一下论文)。我们无法同时满足这连个条件,不过作者提供了更为宽松的约束条件,并且在实践中表现还不错,各个连接的权重必须按照如下方式初始化:
正态分布均值0,标准差$\sigma = \sqrt{\frac{2}{n_{\mbox{input}} + n_{\mbox{output}}}}$
或者,$-r$到$+r$之间的均匀分布,并且$r = \sqrt{\frac{6}{n_{\mbox{input}} + n_{\mbox{output}}}}$
其中,$n_{\mbox{input}}$和$n_{\mbox{output}}$是改成输入和输出数量。这一初始化策略称为Xavier初始化,或者Glorot初始化。
如果输入和输出数量大致相等,公式可以简化为$\sigma = 1/\sqrt{n_{\mbox{input}}}$,$\sigma = \sqrt{3} / \sqrt{n_{\mbox{input}}}$,这正是我们在第十章使用的。
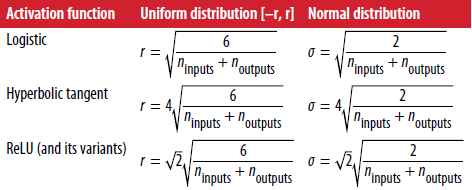
使用Xavier初始化策略可以使训练速度得到显著提升,这正是为当今深度学习带来成果的一个技术手段。一些不久前的论文提供了类似的,针对其他激活函数的初始化策略,如表11-1所示。所有这些初始化策略有时被称作He(这是中国姓氏,但不知道是何,贺,还是和)初始化。
表11-1. 针对不同激活函数的初始化策略
11.1.2 不饱和(Nonsaturating)激活函数
$f$是不饱和函数当且仅当$\mathop{\lim}\limits_{z \to \infty} |f(z)| = +\infty$
Glorot和Bengio在其2010年的论文中认为,带来梯度消失(爆炸)问题的重要原因是可供选择的激活函数太少。最初人们倾向于选择sigmoid激活函数,但事实上在神经网络中其他激活函数表现更好,尤其是ReLU。很重要的原因是ReLU对正值具有不饱和性(也就是没有上限)。
不过ReLU也并不完美,会遇到被称作dying ReLUs的问题:在训练期间,有些神经元事实上死掉了,除了0之外什么也不会输出(这里的输出,应该指的是反向传播时,高层对底层输出的梯度)。有时候一半的神经元都是死的,尤其是学习率较大的情况下。一旦出现这一情况,基本上就不能恢复过来了,因为当ReLU的输入是负数时,其梯度是0。
为了解决这一问题,可以使用ReLU的变体,比如leaky ReLU(如图11-2)。$\mbox{LeakyReLU}_{\alpha}(z) = max(\alpha z, z)$。其中,超参数$\alpha$定义了输入为负值时的倾斜度,一般设置为0.01。这个小斜坡保证了leaky ReLU不会死掉,不过也就可能进入长期的昏迷。毕竟还活着,长期昏迷后还是有可能苏醒过来的。
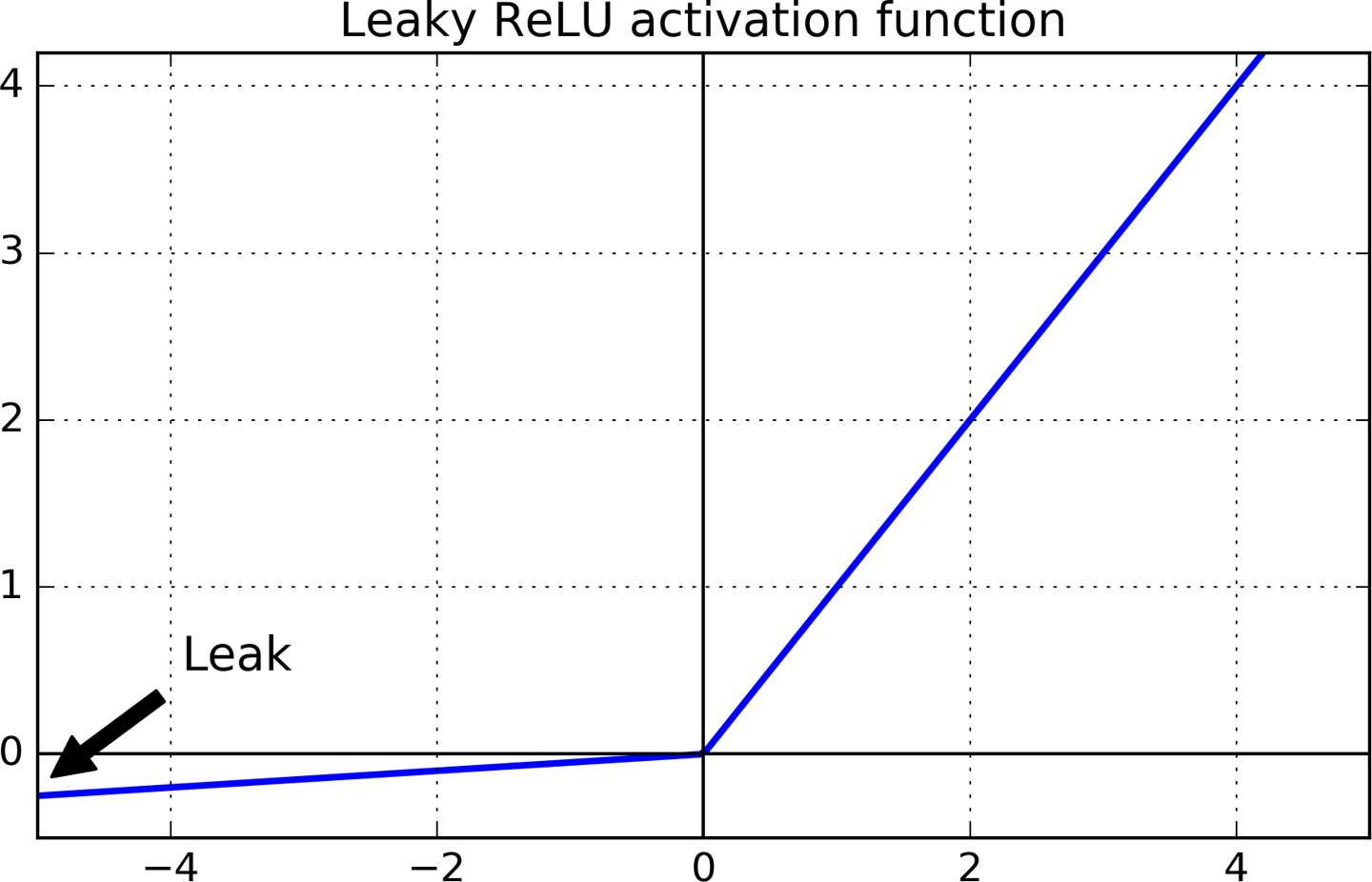
图11-2 Leaky ReLU
Djork-Arné Clevert等人在其2015年的一篇论文中提出了一种称为exponential linear unit (ELU)的新的激活函数,表现好过ReLU的所有变体。
\begin{align*}
\mbox{ELU}_{\alpha}(z) = \left\{\begin{matrix}
\alpha(\exp(z) - 1) &\mbox{if} &z < 0 \\
z &\mbox{if} & z \geq 0
\end{matrix}\right.
\end{align*}
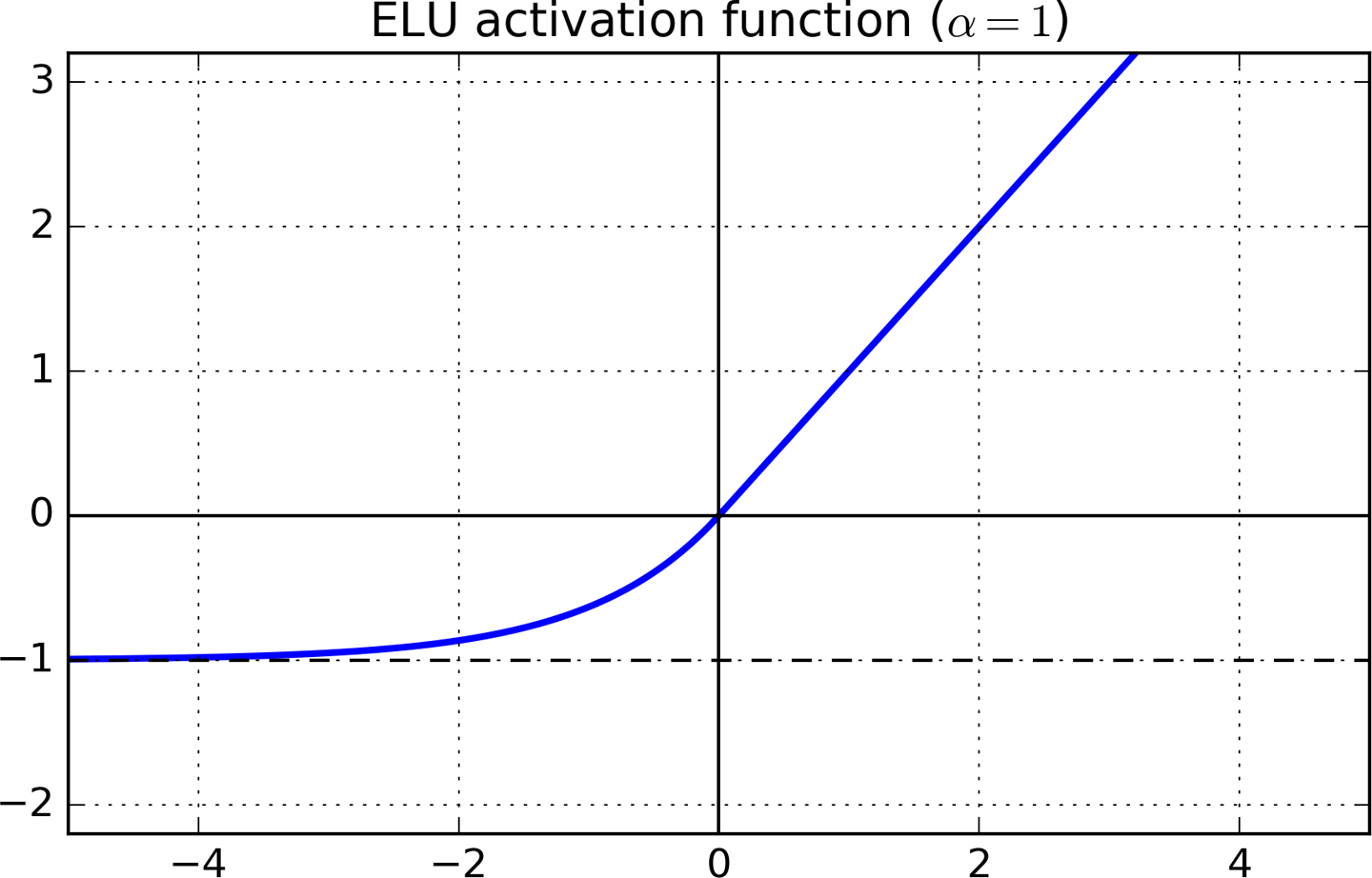
图11-3 ELU激活函数
选择激活函数时,一般ELU > leaky ReLU (及其变种) > ReLU > tanh > logistic。如果你更关心运行时表现,leaky ReLU要优于ELU。
11.1.3 Batch Normalization
尽管He initialization搭配ELU可以缓解训练初期的梯度消失(爆炸)问题,但是并不能保证在整个训练周期都不会出现这一问题。Sergey Ioffe和Christian Szegedy在其2015年的论文中提出了一种被称作Batch Normalization (BN)的解决方案。比梯度消失(爆炸)更一般的问题是,由于前层参数的变化,造成后层输入数据分布变化的问题(他们称为Internal Covariate Shift问题)。
该技术就是在每一层应用激活函数之前,增加一些操作。首先对数据进行简单的zero-centering和normalizing(其实就是转换成均值为0,标准差为1的数据),然后使用两个参数对数据进行scaling和shifting(缩放和平移)操作。换句话说,这两步就是让模型学习每层输入最优的scale(规模)和均值。
批规范化算法(Batch Normalization algorithm):
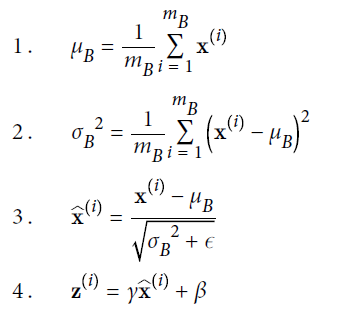
其中,
- $\mu_B$是经验均值,在整个mini-batch上进行评估。
- $\sigma_B$是经验标准差,也是在整个mini-batch上评估的。
- $m_B$是mini-batch的实例数。
- $\hat{X}^{(i)}$是zero-centered和normalized后的输入数据。
- $\gamma$是该层的scaling参数。
- $\beta$是该层的shifting参数。
- $\epsilon$是为了避免除零的,通常为$10^{-3}$,也被称为平滑系数。
- $Z^{(i)}$是BN操作的输出。
在测试阶段,不存在mini-batch来计算经验均值和标准差,简单地使用整个训练集的均值和标准差即可。 These are typically efficiently computed during training using a moving average.(这句话没看懂。moving average是一种快速计算均值和标准差的技术?)所以,每个batch-normalized层需要学习四个参数:$\gamma$(scale),$\beta$(offset),$\mu$(mean)和$\sigma_B$(standard deviation)。
作者宣称,该技术提升了他们实验所采用的所有深度学习网络。梯度消失问题得到了明显的环境,以至于可以使用饱和激活函数,比如tanh,甚至是logistic激活函数。网络对权重初始值的敏感度也明显降低。他们也可以提到学习率来加快训练速度。此外,Batch Normalization也充当了正则化的角色,减少其他正则化技术的使用(比如后面章节将会介绍的dropout)。
当然,该技术有利也有弊——其增加了模型复杂度,这是一种运行时惩罚:额外的计算导致预测缓慢。所以,如果更在意预测效率的话,最好还是选择ELU + He initialization。
然后是Batch Normalization的TensorFlow实现,代码可参考作者的GitHub。
11.1.4 Gradient Clipping
减轻梯度爆炸的一项技术是使反向传播的梯度不超过某个阈值(这在训练rnn时比较有用)。 这一技术称为Gradient Clipping。现在人们更喜欢Batch Normalization,不过了解一下Gradient Clipping还是有帮助的。
11.2 Reusing Pretrained Layers
如果训练一个大型的DNN,一般都不会从零开始,而是找到一个已经训练好的,与你的任务相似的模型。复用旧模型的底层,这称为transfer learning。这不仅会加快训练速度,而且需要更少的训练数据。
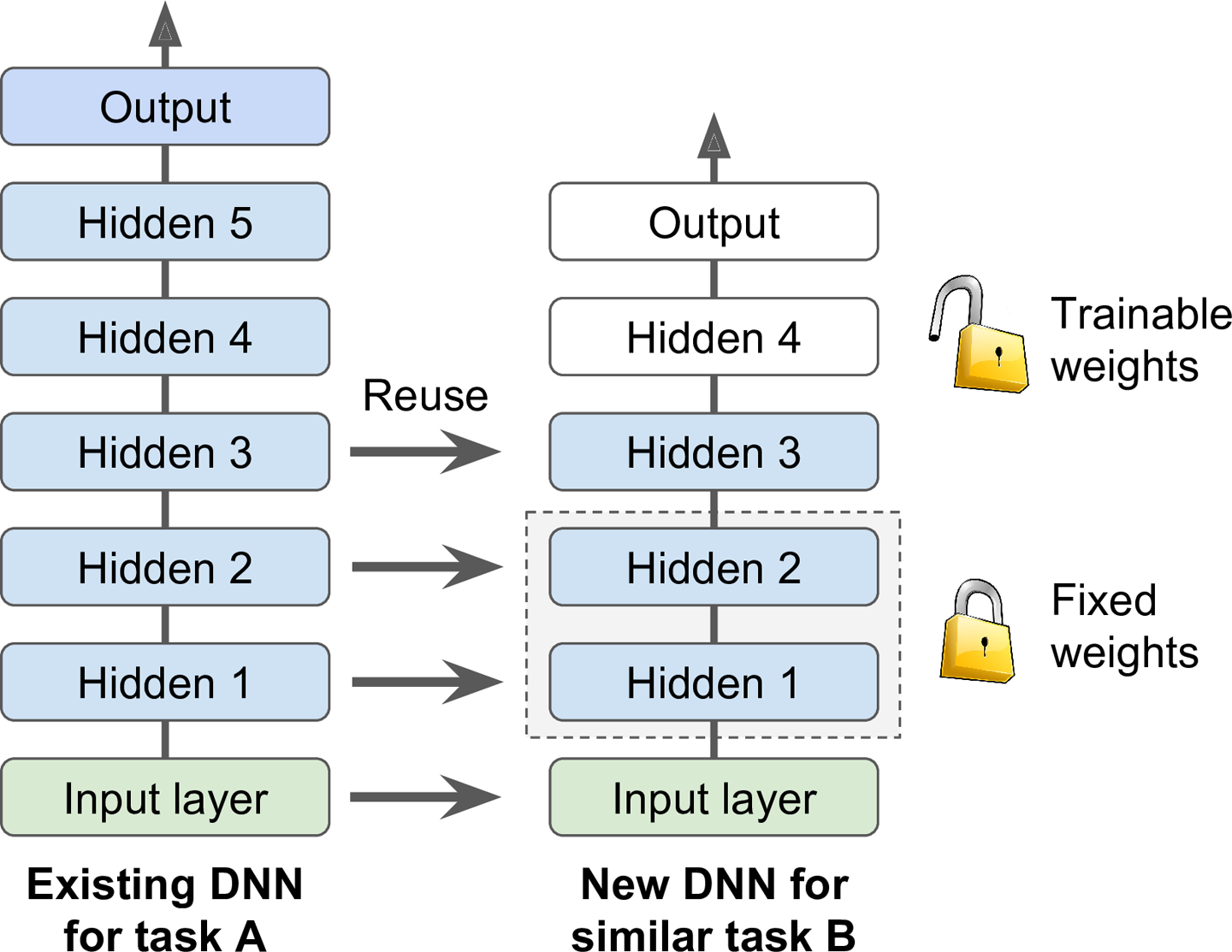
图11-4 Reusing pretrained layers
在上图中,如果新旧模型训练数据的结构不一致,那就需要增加一步预处理,将数据的格式转换为就模型需要的。一般情况下,transfer learning在输入值具有相似的低级别特征时表现良好。
11.2.1 Reusing a TensorFlow Model
讲解在原始模型使用TensorFlow时,新的模型如何复用。
11.2.2 Reusing Models from Other Frameworks
讲解如果模型是其他框架实现的,在TensorFlow中如何复用。
11.2.3 Freezing the Lower Layers
就是冷冻住低层级的参数,使其在反向传播时不被更新。
11.2.4 Caching the Frozen Layers
如果使用了11.2.3的技术,由于前面几层的参数是不变的,可以将最高冷冻层的输出值缓存起来,不用每次前向传播都去计算。这可以提高训练速度。
11.2.5 Tweaking, Dropping, or Replacing the Upper Layers
原始模型的输出层会被替换掉,因为它一本对新任务来讲是没用的,甚至与新任务输出值的个数都不匹配。类似的,原始模型的高级隐层对新任务的用处较小。我们需要找到适合复用的层数。
首先复用所有层,训练模型并评估其表现。然后解冻一个或两个隐层,训练之后观察其表现是否提升。训练数据越多,就解冻越多的层。
11.2.6 Model Zoos
这就是模型仓库,可以找到别人训练好的模型。
TensorFlow的model zoo位于https://github.com/tensorflow/models。包含目前最先进的图像分类网络,比如VGG, Inception, and ResNet。
另一个是Caffe’s Model Zoo:https://github.com/BVLC/caffe/wiki/Model-Zoo。
11.2.7 Unsupervised Pretraining
假设你要处理一个复杂的任务,并且没有足够带标签的训练数据。并且的是,也找不到针对类似任务训练好的模型。不要绝望!首先,你当然应该收集更多的带标签数据,如果这很困难或者很昂贵,仍然可以使用unsupervised pretraining完成任务(如图11-5)。这就是说,如果你有大量的无标签数据,那就可以一层层地训练,使用无监督特征检测(feature detector)算法,比如Restricted Boltzmann Machines或者autoencoders。等到所有层都训练完成,就可以使用监督学习对网络进行微调。
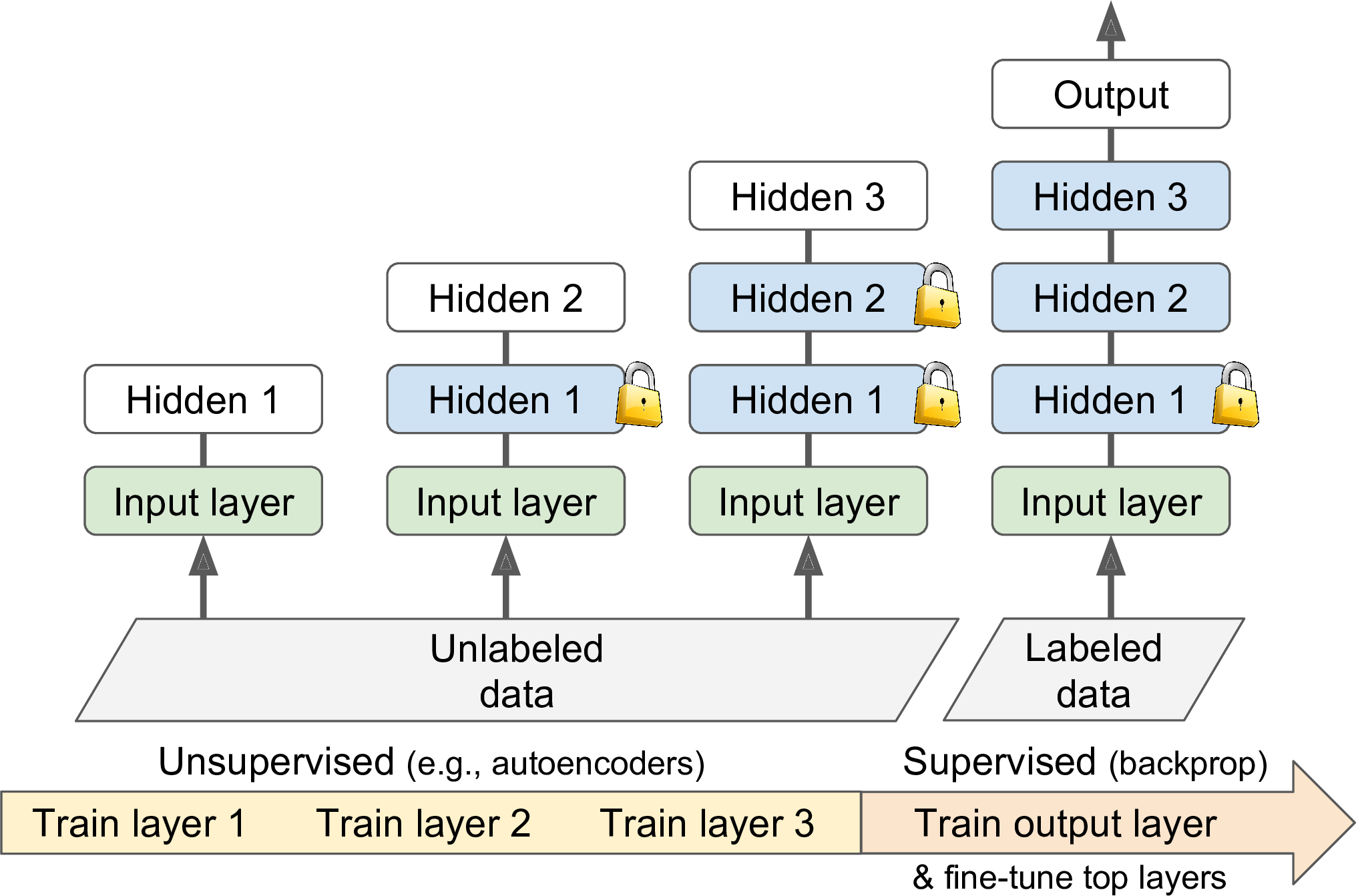
图11-5 Unsupervised pretraining
这是一个漫长乏味的过程,但是往往表现良好。事实上,这一技术正是Geoffrey Hinton及其团队在2016年使用并带来了神经网络的复兴以及深度学习的成功。
11.2.8 Pretraining on an Auxiliary Task
另外一个选择是,首先训练一个辅助的模型,该模型的标签数据可以轻易生成,然后复用底层来训练模型实现真正的任务。
比如,你想建立一个人脸识别系统,并且没有太多的带标签数据。不过你可以在网络随机搜集一些照片,并训练一个模型来识别不同的照片中是否是同一个人。第一个模型会学习到识别人脸的优秀特征,这可以在第二个模型中复用,并减少第二个模型所需的训练数据。
11.3 Faster Optimizers
这一小节的结论是,用AdamOptimizer替换掉GradientDescentOptimizer就行了。我先跳过了,后面有时间再补上这几个优化算法。
11.4 Avoiding Overfitting Through Regularization
神经网络往往参数很多,自由度很大,太容易过拟合,所以应该使用一些正则化技术防止过拟合。
11.4.1 Early Stopping
这在第四章介绍过,就是在校验集表现最好时终止训练。
11.4.2 $l_i$和$l_2$正则
这个也和第四章的意义,跟传统机器模型的方式一样。
11.4.3 Dropout
当前深度神经网络最受欢迎的正则化技术大概就是dropout了。它首先由G. E. Hinton在2012年提出,并由Nitish Srivastava在其论文中完善。该技术取得了巨大成功。
这是一个很简单的算法:在每一步训练,所有神经元(包括输入神经元但不包括输出神经元)都有一个可能“dropped out”的概率$p$,意味着本次训练它可能会被忽视,但在下次训练有可能会被激活。超参数$p$被称作dropout rate,一般被设置为50%。训练结束后,神经元不再被忽视。
起初可能觉得吃惊,这一蛮横的算法居然表现良好。我们现在假设,一家公司通过抛硬币决定每个员工是否上班。很明显这家公司要改编其组织架构。任何工作都不能依赖于单独一个人,所以专业技术需要传授给很多人。雇员必须学着与同事合作。如果某员工退出,影响不会太大。虽然不知道这一思想是否适用于公司运营,但其确实适用于神经网络的训练。神经元将对输入值的轻微变化不再敏感,最终会得到一个更加鲁棒,更容易一般化的神经网络。
理解dropout巨大威力的另一个途径就是理解,每一步训练其实都在生成一个不同的神经网络。由于每个神经元都可能出席或者缺席,总共有$2^N$(其中,$N$是可忽视神经元总数)种可能的网络。如果训练10000步,本质上就是训练了10000个神经元。最终的神经元可以看成是这些单独神经元的一个averaging ensemble。
还有一个技术细节。假设$p$ = 50%,在这种情况下测试阶段的神经元数量是训练阶段的两倍。为了弥补这一问题,我们需要在训练结束后对连接权重乘以0.5。更一般的,我们需要在训练结束后对连接权重乘以keep probability (1 – p)。
如果观察到模型过拟合,可以增大dropout rate。欠拟合就减小dropout rate。
Dropout会显著地降低收敛速度,但通常会得到一个更好的模型。多花费一些训练时间也是值得的。
11.4.4 Max-Norm Regularization
另外一种比较受欢迎的神经网络正则化方法是max-norm正则。对于每一个连接权重$w$,都使其满足$\left \| w \right \|_2 \leq \gamma $,其中$\gamma$是max-norm超参数。
算法实现时,一般会先计算$\left \| w \right \|_2$,如果需要的话就对其进行修剪($w \leftarrow w\frac{r}{\left \| w \right \|_2}$)。
降低$\gamma$就可以减少过拟合的可能性。max-norm正则也可以缓解梯度消失(爆炸)问题(如果没使用Batch Normalization)。
TensorFlow并不提供现成的max-norm正则,不过作者自己实现了一个。
11.4.5 Data Augmentation
该正则化技术就是通过已经存在的训练集来生成新的训练实例。这一技巧就是生成逼真的训练数据。理想情况下,人无法区分该实例是否自动生成。简单的增加white noise并没有帮助,因为改变必须是可学习的(white noise不能被学习)。例如,根据一个图片,生成各种不同的图片,如下图所示:

图11-10 使用现有训练样本生成新的实例
11.5 实用的指导方针
DNN默认配置:
Initialization:He initialization
Activation function: ELU
Normalization: Batch Normalization
Regularization: Dropout
Optimizer: Adam
Learning rate schedule: None
默认的配置可能需要调整:
- 如果找不到一个合适的学习率(收敛太慢,增大学习率。然后收敛加快了,但是最终的模型不是最优的),那就可以尝试增加一个learning schedule,比如exponential decay。
- 如果训练集太小,可以实现data augmentation
- 如果想要一个稀疏的模型,可以增加$l_1$正则。需要更加稀疏的话,尝试使用FTRL代替Adam优化,并配合$l_1$正则。
- 如果需要一个能够快速预测的模型,那也许就需要放弃Batch Normalization,改为ELU激活函数。稀疏的模型也能加快预测时间。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号