
在Python中使用XGBoost
在Python中使用XGBoost
众所周知,XGBoost提供比其他机器学习算法更好的解决方案。事实上,自成立以来,它已成为处理结构化数据的“最先进”的机器学习算法。
在本教程中,您将学习如何在python中使用XGBoost构建机器学习模型。更具体地说,您将学到:
- Boosting是什么以及XGBoost如何运作。
- 如何在数据集上应用XGBoost并验证结果。
- 关于可以在XGBoost中调整的各种超参数,以提高模型的性能。
- 如何可视化Boosted树和功能重要性
但是什么让XGBoost如此受欢迎?
-
速度和性能:最初用C ++编写,比其他集成分类器要快。
-
核心算法是可并行化的:因为核心XGBoost算法是可并行化的,所以它可以利用多核计算机的强大功能。它还可以并行化到GPU和计算机网络上,因此也可以在非常大的数据集上进行训练。
-
始终如一地优于其他算法方法:它在各种机器学习基准数据集上表现出更好的性能。
-
各种调整参数:XGBoost内部具有交叉验证,正则化,用户定义的目标函数,缺失值,树参数,scikit-learn兼容API等参数。
XGBoost(Extreme Gradient Boosting)属于一系列增强算法,并在其核心使用梯度增强(GBM)框架。它是一个优化的分布式梯度增强库。但等等,是什么促进?好吧,继续阅读。
推进
Boosting是一种按照集合原理工作的顺序技术。它结合了一组弱学习者并提高了预测准确性。在任何时刻t,基于先前时刻t-1的结果对模型结果进行加权。正确预测的结果具有较低的权重,而错过分类的结果具有较高的权重。请注意,弱学习者是比随机猜测略好的学习者。例如,决策树的预测略好于50%。让我们通过一个简单的例子来理解提升。
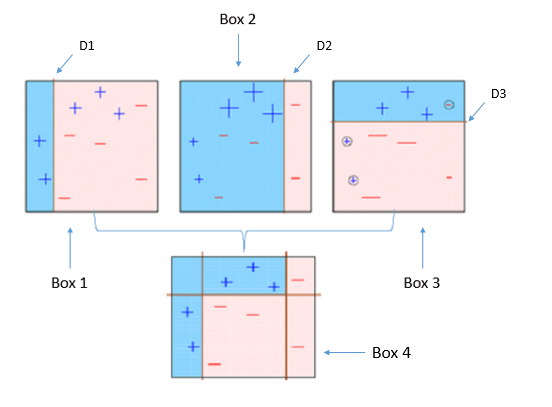
如上所示,四个分类器(在4个方框中)试图尽可能均匀地对+和-类进行分类。
1.方框1:第一个分类器(通常是决策树桩)在D1处创建一条垂直线(分割)。它说D1左边的任何东西都是+,而D1右边的任何东西都是-。但是,此分类器错误分类了三个+点。
请注意,决策树桩是一种决策树模型,仅在一个级别分割,因此最终预测仅基于一个特征。
2.方框2:第二个分类器给三个+误分类点赋予更多权重(参见更大的+大小)并在D2处创建一条垂直线。再说它,D2右边的任何东西都是-而左边是+。尽管如此,它由不正确分类三个等于错误-点。
3.框3:同样,第三分类器提供了更多的重量的三-错误分类点,并创建在D3的水平线。但是,此分类器无法正确地对点(在圆圈中)进行分类。
4.方框4:这是弱分类器的加权组合(方框1,2和3)。正如您所看到的,它在正确分类所有点方面做得很好。
这是推动算法背后的基本思想是建立一个弱模型,对各种特征重要性和参数做出结论,然后利用这些结论建立一个新的,更强大的模型,并利用先前模型的错误分类错误并尝试减少它。现在,让我们来看看XGBoost。首先,您应该了解XGBoost的默认基础学习者:树集合。树集合模型是一组分类和回归树(CART)。树木一个接一个地生长,并且在随后的迭代中尝试降低错误分类率。这是一个简单的CART示例,它根据XGBoost的文档对某人是否喜欢计算机游戏进行分类。
如果您在“树组合”部分中检查图像,您会注意到每棵树根据它看到的数据给出不同的预测分数,并将每棵树的分数相加以得到最终分数。
在本教程中,您将使用XGBoost来解决回归问题。数据集取自UCI机器学习库,也存在于sklearn的datasets模块中。它有14个解释变量描述波士顿住宅的各个方面,挑战是预测每1000美元的自住房屋的中位数。
在Python中使用XGBoost
首先,就像您对任何其他数据集所做的那样,您将导入Boston Housing数据集并将其存储在名为boston的变量中。要从scikit-learn导入它,您需要运行此代码段。
from sklearn.datasets import load_boston
boston = load_boston()
波士顿变量本身是一个字典,因此您可以使用该.keys()方法检查其键。
print(boston.keys())
dict_keys(['data', 'target', 'feature_names', 'DESCR'])
您可以使用boston.data.shape属性轻松检查其形状,该属性将返回数据集的大小。
print(boston.data.shape)
(506, 13)
正如您所看到的那样(506,13),这意味着有506行数据,包含13列。现在,如果您想知道13列是什么,您可以简单地使用该.feature_names属性,它将返回功能名称。
print(boston.feature_names)
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
数据集本身可以使用数据集的描述。您可以使用它来查看它.DESCR。
print(boston.DESCR)
Boston House Prices dataset
===========================
Notes
------
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
http://archive.ics.uci.edu/ml/datasets/Housing
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
**References**
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
- many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)
现在让我们将其转换为pandas DataFrame!为此,您需要导入pandas库并调用DataFrame()传递参数的函数boston.data。要标记列的名称,请使用.columnnspandas DataFrame 的属性并将其分配给boston.feature_names。
import pandas as pd
data = pd.DataFrame(boston.data)
data.columns = boston.feature_names
使用head()pandas DataFrame上的方法浏览数据集的前5行。
data.head()
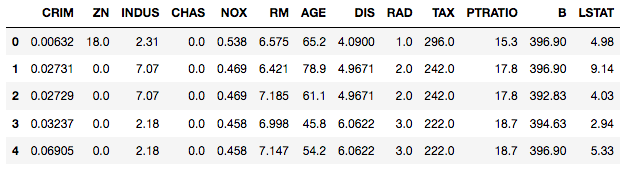
您会注意到PRICEDataFrame中没有调用任何列。这是因为目标列在另一个名为的属性中可用boston.target。附加boston.target到您的pandas DataFrame。
data['PRICE'] = boston.target
.info()在DataFrame上运行该方法以获取有关数据的有用信息。
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
CRIM 506 non-null float64
ZN 506 non-null float64
INDUS 506 non-null float64
CHAS 506 non-null float64
NOX 506 non-null float64
RM 506 non-null float64
AGE 506 non-null float64
DIS 506 non-null float64
RAD 506 non-null float64
TAX 506 non-null float64
PTRATIO 506 non-null float64
B 506 non-null float64
LSTAT 506 non-null float64
PRICE 506 non-null float64
dtypes: float64(14)
memory usage: 55.4 KB
原来这个数据集有14列(包括目标变量PRICE)和506行。请注意,列是float数据类型,表示只存在任何列中没有缺失值的连续要素。要获得数据集中不同功能的更多摘要统计信息,您将describe()在DataFrame上使用该方法。
请注意,describe()仅提供本质上连续且不具有分类的列的摘要统计信息。
data.describe()
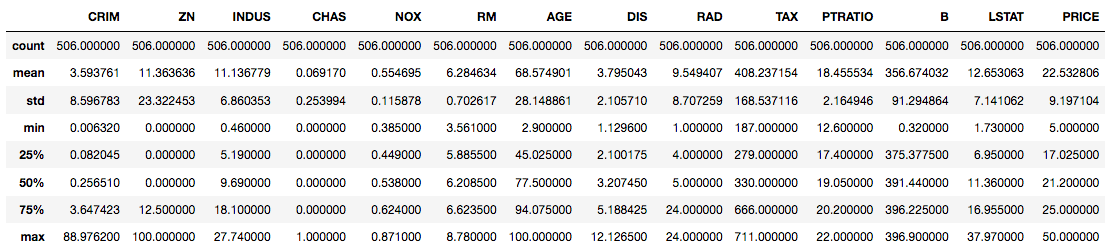
如果您计划在具有分类功能的数据集上使用XGBoost,则可能需要考虑在训练模型之前对这些功能应用某些编码(如单热编码)。此外,如果您有一些缺失值,例如NA在数据集中,您可能会或可能不会对它们进行单独处理,因为XGBoost能够在内部处理缺失值。如果您想了解更多信息,可以查看此链接。
如果不深入探索更多的探索性分析和特征工程,您现在将专注于应用算法来训练该数据的模型。
您将使用Trees作为基础学习者(这是默认的基础学习者)使用XGBoost的scikit-learn兼容API构建模型。在此过程中,您还将学习XGBoost提供的一些常用调整参数,以便提高模型的性能,并使用均方根误差(RMSE)性能指标来检查测试集上训练模型的性能。根均值平方误差是实际值和预测值之间的平方差的平均值的平方根。像往常一样,您首先导入库xgboost以及将用于构建模型的其他重要库。
请注意,您可以xgboost使用pip install xgboostcmd 在系统上安装python库。
import xgboost as xgb
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
使用.iloc对数据进行子集来分离目标变量和其余变量。
X, y = data.iloc[:,:-1],data.iloc[:,-1]
现在,您将数据集转换为DmatrixXGBoost支持的优化数据结构,并为其提供广受好评的性能和效率提升。您将在本教程的后面部分使用它。
data_dmatrix = xgb.DMatrix(data=X,label=y)
XGBoost的超参数
此时,在构建模型之前,您应该了解XGBoost提供的调整参数。嗯,XGBoost中基于树的学习者有很多调整参数,你可以在这里阅读所有关于它们的内容。但你应该知道的最常见的是:
learning_rate:步长缩小用于防止过度拟合。范围是[0,1]max_depth:确定在任何一轮助推期间允许每棵树生长的深度。subsample:每棵树使用的样本百分比。低值可能导致不合适。colsample_bytree:每棵树使用的功能百分比。高价值可能导致过度拟合。n_estimators:您要构建的树的数量。objective:确定要用于reg:linear回归问题的损失函数,reg:logistic对于仅有决策binary:logistic的分类问题,对于具有概率的分类问题。
XGBoost还支持正则化参数,以便在模型变得更加复杂时对其进行惩罚,并将模型简化为简单(简约)模型。
gamma:控制给定节点是否将根据拆分后预期的损失减少进行拆分。值越高,分割越少。仅支持基于树的学习者。alpha:叶片重量的L1正则化。较大的价值导致更多的正规化。lambda:叶子权重的L2正则化,比L1正则化更平滑。
值得一提的是,虽然您使用树木作为基础学习者,但您也可以使用XGBoost相对不太受欢迎的线性基础学习者和另一个称为dart的树形学习者。您所要做的就是将booster参数设置为gbtree(默认)gblinear或dart。
现在,您将使用train_test_splitsklearn model_selection模块中的函数创建用于交叉验证结果的训练和测试集,其test_size大小等于数据的20%。另外,为了保持结果的再现性,random_state还指定了a。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
下一步是通过XGBRegressor()从XGBoost库调用类并将超参数作为参数传递来实例化XGBoost回归对象。对于分类问题,您可以使用XGBClassifier()该类。
xg_reg = xgb.XGBRegressor(objective ='reg:linear', colsample_bytree = 0.3, learning_rate = 0.1,
max_depth = 5, alpha = 10, n_estimators = 10)
适合回归训练集,并使用熟悉的测试集的预测.fit()和.predict()方法。
xg_reg.fit(X_train,y_train)
preds = xg_reg.predict(X_test)
通过调用mean_sqaured_errorsklearn metrics模块中的函数来计算rmse 。
rmse = np.sqrt(mean_squared_error(y_test, preds))
print("RMSE: %f" % (rmse))
RMSE: 10.569356
好吧,你可以看到你的价格预测RMSE大约是每1000美元10.8。
使用XGBoost进行k-fold交叉验证
为了构建更健壮的模型,通常进行k折交叉验证,其中原始训练数据集中的所有条目都用于训练和验证。此外,每个条目仅用于验证一次。XGBoost通过该cv()方法支持k折交叉验证。您所要做的就是指定nfolds参数,该参数是您要构建的交叉验证集的数量。此外,它支持许多其他参数(请查看此链接),如:
num_boost_round:表示您构建的树的数量(类似于n_estimators)metrics:告诉在CV期间要评估的评估指标as_pandas:在pandas DataFrame中返回结果。early_stopping_rounds:如果保持度量(在我们的例子中为“rmse”)在给定数量的回合中没有改善,则提前完成对模型的训练。seed:为了重现结果。
这次您将创建一个超参数字典params,它将所有超参数及其值保存为键值对,但会n_estimators从超参数字典中排除,因为您将使用它num_boost_rounds。
您将使用这些参数通过调用XGBoost的cv()方法构建3倍交叉验证模型,并将结果存储在cv_resultsDataFrame中。请注意,您在此处使用之前创建的Dmatrix对象。
params = {"objective":"reg:linear",'colsample_bytree': 0.3,'learning_rate': 0.1,
'max_depth': 5, 'alpha': 10}
cv_results = xgb.cv(dtrain=data_dmatrix, params=params, nfold=3,
num_boost_round=50,early_stopping_rounds=10,metrics="rmse", as_pandas=True, seed=123)
cv_results 包含每次助推一轮的训练和测试RMSE指标。
cv_results.head()
| 测试RMSE均值 | 测试RMSE-STD | 列车RMSE均值 | 列车RMSE-STD | |
|---|---|---|---|---|
| 0 | 21.746693 | 0.019311 | 21.749371 | 0.033853 |
| 1 | 19.891096 | 0.053295 | 19.859423 | 0.029633 |
| 2 | 18.168509 | 0.014465 | 18.072169 | 0.018803 |
| 3 | 16.687861 | 0.037342 | 16.570206 | 0.018556 |
| 4 | 15.365013 | 0.059400 | 15.206344 | 0.015451 |
提取并打印最终的提升轮度量标准。
print((cv_results["test-rmse-mean"]).tail(1))
49 4.031162
Name: test-rmse-mean, dtype: float64
您可以看到,您的价格预测RMSE与上次相比有所下降,大约为每1000美元4.03。对于不同的超参数集,您可以达到更低的RMSE。您可以考虑应用网格搜索,随机搜索和贝叶斯优化等技术来达到最佳的超参数集。
可视化提升树和特征重要性
您还可以使用整个外壳数据集从XGBoost创建的完全提升模型中可视化单个树。XGBoost具有plot_tree()使这种类型的可视化变得容易的功能。使用XGBoost学习API训练模型后,可以plot_tree()使用num_trees参数将其传递给函数以及要绘制的树的数量。
xg_reg = xgb.train(params=params, dtrain=data_dmatrix, num_boost_round=10)
使用matplotlib库绘制第一个树:
import matplotlib.pyplot as plt
xgb.plot_tree(xg_reg,num_trees=0)
plt.rcParams['figure.figsize'] = [50, 10]
plt.show()
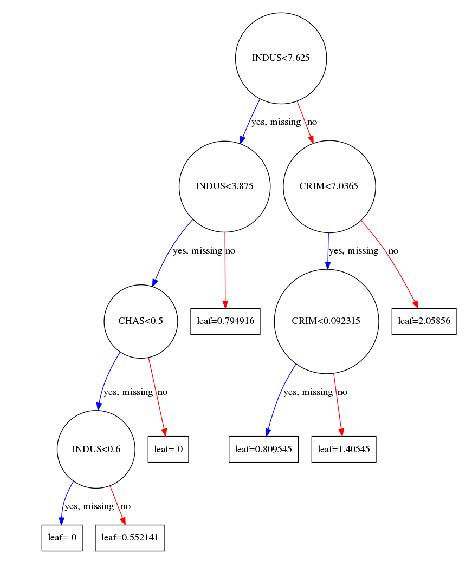
这些图提供了洞察模型如何达到最终决策以及为达到这些决策而做出的分裂。
请注意,如果上面的图表在您的系统上引发“graphviz”错误,请考虑pip install graphviz在cmd上安装graphviz包。您可能还需要sudo apt-get install graphviz在cmd 上运行。(链接)
可视化XGBoost模型的另一种方法是检查模型中原始数据集中每个要素列的重要性。
一种简单的方法是计算每个特征在模型中所有增强轮(树)上分割的次数,然后将结果可视化为条形图,其特征根据它们出现的次数排序。XGBoost有一个plot_importance()功能,可以让你做到这一点。
xgb.plot_importance(xg_reg)
plt.rcParams['figure.figsize'] = [5, 5]
plt.show()
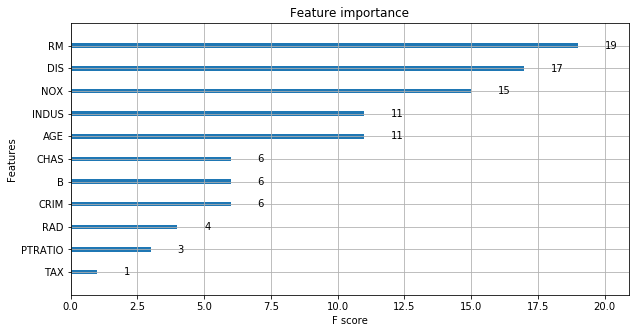
正如您所看到的,该功能RM在所有功能中得分最高。因此,XGBoost还为您提供了一种进行特征选择的方法。这不是很棒吗?
结论
您已经到了本教程的末尾。我希望这可能会或将会以某种方式帮助你。您开始了解Boosting的工作原理,然后专门缩小到XGBoost。您还练习在开源数据集上应用XGBoost,并了解其超参数,进行交叉验证,可视化树以及最终如何将其用作特征选择技术。哇!这对初学者来说很重要,但是在XGBoost中有很多值得探索的内容,它不能在单个教程中介绍。如果您想了解更多信息,请务必使用DataCamp上的XGBoost课程了解我们的Extreme Gradient Boosting。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号