Elasticsearch查询——布尔查询Bool Query
Bool查询现在包括四种子句,must,filter,should,must_not。
为什么filter会快?
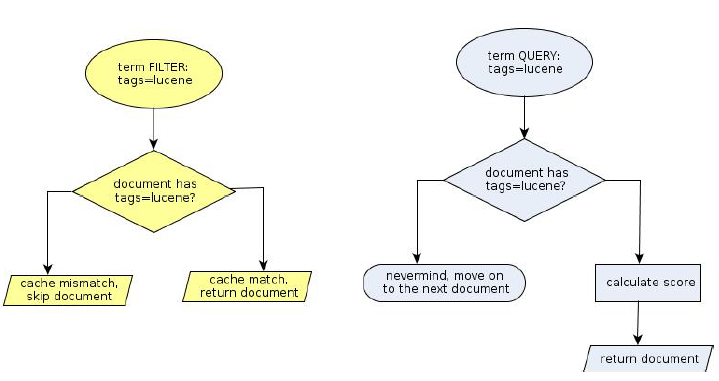
看上面的流程图就能很明显的看到,filter与query还是有很大的区别的。
比如,query的时候,会先比较查询条件,然后计算分值,最后返回文档结果;
而filter则是先判断是否满足查询条件,如果不满足,会缓存查询过程(记录该文档不满足结果);满足的话,就直接缓存结果。
综上所述,filter快在两个方面:
- 1 对结果进行缓存
- 2 避免计算分值
bool查询的使用
Bool查询对应Lucene中的BooleanQuery,它由一个或者多个子句组成,每个子句都有特定的类型。
must
返回的文档必须满足must子句的条件,并且参与计算分值
filter
返回的文档必须满足filter子句的条件。但是不会像Must一样,参与计算分值
should
返回的文档可能满足should子句的条件。在一个Bool查询中,如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回。minimum_should_match参数定义了至少满足几个子句。
must_nout
返回的文档必须不满足must_not定义的条件。
如果一个查询既有filter又有should,那么至少包含一个should子句。
bool查询也支持禁用协同计分选项disable_coord。一般计算分值的因素取决于所有的查询条件。
bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。
{
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "from" : 10, "to" : 20 }
}
},
"should" : [
{
"term" : { "tag" : "wow" }
},
{
"term" : { "tag" : "elasticsearch" }
}
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}bool.filter的分值计算
在filter子句查询中,分值将会都返回0。分值会受特定的查询影响。
比如,下面三个查询中都是返回所有status字段为active的文档
第一个查询,所有的文档都会返回0:
GET _search
{
"query": {
"bool": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}下面的bool查询中包含了一个match_all,因此所有的文档都会返回1
GET _search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"status": "active"
}
}
}
}
}constant_score与上面的查询结果相同,也会给每个文档返回1:
GET _search
{
"query": {
"constant_score": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}使用named query给子句添加标记
如果想知道到底是bool里面哪个条件匹配,可以使用named query查询:
{
"bool" : {
"should" : [
{"match" : { "name.first" : {"query" : "shay", "_name" : "first"} }},
{"match" : { "name.last" : {"query" : "banon", "_name" : "last"} }}
],
"filter" : {
"terms" : {
"name.last" : ["banon", "kimchy"],
"_name" : "test"
}
}
}
}
转载:https://www.cnblogs.com/xing901022/p/5994210.html
 浙公网安备 33010602011771号
浙公网安备 33010602011771号