Java开发者需要了解的硬件知识 (一)、CPU篇
前言:
深入学习JAVA前,程序猿需要了解一些相关的硬件底层知识,这一篇专门来讲一讲CPU和JAVA相关的知识
因为学习内容里有些不那么重要的知识点,往往就是截图或者少量文字带过,个人笔记不会记录那么多细节,详细资料请读者自己查询,见谅。
简易的计算机组成:
CPU从PC中拿到下一条指令的地址,从内存或别的IO设备中读取数据,把数据暂时存放在Registers中,根据指令要求,在ALU中对Registers中的数据进行运算,然后把结果返回到指定的内存区域。
CPU的基本组成:
- Registers -> 暂时存储CPU计算需要用到的数据
- ALU -> Arithmetic & Logic Unit 运算单元
- CU -> Control Unit 控制单元
- MMU -> Memory Management Unit 内存管理单元
- cache -> 多级缓存
CPU的多线程结构:
ALU可以快速切换Registers,以快速处理多个线程
多核CPU结构:
CPU缓存:
为了让CPU更快速的读取数据(比从内存读取还快),就在CPU中设计了多级缓存
读取速度参考值:
按块读取规则
根据程序局部性原理(一个程序存储的数据一般在内存中是连续的),往往读取数据都是按照一个个数据块进行读取的,以此来提高IO效率。
cache line (缓存行)
上面是个多核的CPU的内存读取模型
CPU读取数据时,会就近原则取数据,取不到最后会从内存中再一步步存回L1缓存
CPU->L1->L2->L3->MEMORY->L3->L2->L1->CPU
cache line 为 缓存行 ,每次读取数据都会读取一个缓存行,而不是单个数据大小的内容。
缓存行越大,局部性空间效率越高,但读取时间慢
缓存行越小,局部性空间效率越低,但读取时间快
取一个折中值,目前CPU缓存行大多使用:64字节
多个CPU读取同一缓存行内的数据存在数据一致性问题:
对于这个问题,不同的CPU使用不同的缓存一致性协议,单位都是以缓存行读取的。
Intel:MESI协议 www.cnblogs.com/z00377750/p…
- M:Modified
- E:Exclusive
- S:Shared
- I:Invalid
伪共享问题:
缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
缓存行对齐:
因为有缓存行的存在,就出现了一种编程设计方式,叫做缓存行对齐!
对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,就可以使用缓存航对齐的编程方式
JDK7中,很多采用long padding提高效率(就是一个数据的前后塞满Long类型,一个Long占8字节)
JDK8,加入了@Contended注解(实验)需要加上:JVM -XX:-RestrictContended
CPU的乱序执行特性:

当CPU得到的多个指令间没有依赖关系,那么CPU会在等待某条指令操作时优先执行另一条指令,上图有个很好的例子,烧开水的时候,人可以去洗茶杯茶壶,这样就可以提高喝茶的整体效率了~
但是,当在多线程场景中,CPU乱序执行可能就会出现问题
这里简单快速的解释一下(主要跟JVM有关)
1、由于JAVA创建对象时,有个中间态,处于中间态时,对象并没有完成全部的初始化。
2、如果此时,在中间态时,发生了CPU乱序执行,初始化对象指令还未执行,对象就被另一个线程使用,就会导致拿到没有初始化完成的对象。
(DCL单例就是解决这个问题,所以DCL单例必须使用volatile修饰对象, volatile可以禁止重排序,并且线程透明)
禁止乱序执行:
CPU层面上,要如何禁止指令的重排序呢?答案就是内存屏障。,对某部分内存做操作前后做出内存屏障,屏障前后指令不可乱序执行。
Intel CPU可以使用三种原语( lfence sfence mfence ),或者Lock指令来实现。
1、lfence -> loadfence 在lfence指令前的读操作必须在lfence指令后的读操作前执行,sfence -> storefence 在sfence指令前的写操作必须在sfence指令后的写操作前执行, mfence -> mixedfence 在mfence指令前的读写操作必须在mfence指令后的读写操作前执行
2、Lock指令比较狠,它属于X86 CPU指令,它会直接锁住内存总线(Memory BUS)
JVM层面上,JVM规范了他的内存屏障实现
1、loadload屏障 loadload屏障前的load1指令必须先于loadload屏障后的load2指令前完成,不可互换
2、storestore屏障 。。。。。。类推
3、loadstore屏障 loadstore屏障前的load1指令必须先于loadload屏障后的store2指令前完成,不可互换
4、storeload屏障 。。。。。。类推
举个栗子:JVM对volatile的实现,保证了可见性和禁止乱序
store1
storestore (等前面的store1写指令完成后才能开始volatile的写指令)
volatile写指令
storeload (等前面的volatile写指定完成后才能做后面的读指令)
load1
loadload (等前面的load1写指令完成后才能开始volatile的读指令 )
volatile读指令
loadstore (等前面的volatile读指令完成后才能做后面的写指令)
JVM同时也规定了指令重排序的必须遵守的8条规则,称之为Happens-Before规则(这个知道就好,不用细扣)
Happens-Before的规则包括:
- 程序顺序规则
- 锁定规则
- volatile变量规则
- 线程启动规则
- 线程结束规则
- 中断规则
- 终结器规则
- 传递性规则
as-if-serial:不管硬件什么顺序,单线程执行的结果不变,看上去好像是serial顺序执行
SingleThreadPool 可以实现单线程的队列任务
WC - Write Combining 合并写技术
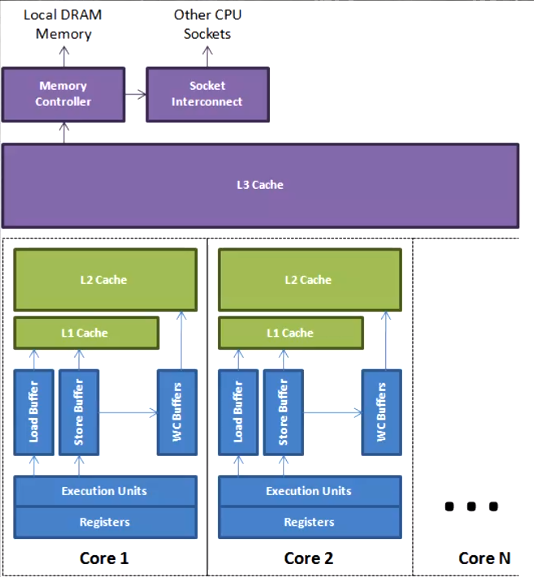
为了提高写效率,CPU在写入L1缓存时,同时用WC写入L2缓存
Registers和L1缓存间存在极小空间的缓冲区,Load Buffer, Store Buffer
但是还有一个直接通向L2缓存,那就是WC Buffer,这块缓冲区一般大小为4个字节。在写入L1缓存的同时,写入一个WC BUFFER,写满该缓存区后,直接更新到L2缓存
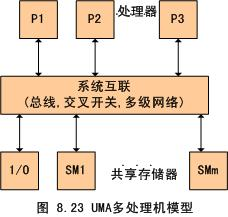
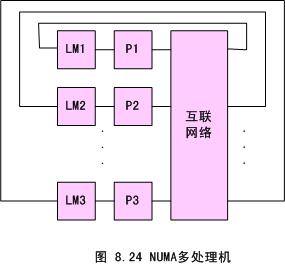
UMA 和 NUMA
均匀存储器存取(Uniform-Memory-Access,简称UMA)模型、非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型,这些模型的区别在于存储器和外围资源如何共享或分布。
结束语
CPU相关的知识就记录到这,总的来说,一些知识点解释了JVM的一些底层细节,也非常有趣,作为以后了解JVM原理时的基础知识,还是非常有学习意义的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号