202108082148 (未完待续)mysql覆盖索引与回表查询
select id,name where name='shenjian'
select id,name__,sex_* where name='shenjian'
多查询了一个属性,为何检索过程完全不同?
什么是回表查询?
什么是索引覆盖?
如何实现索引覆盖?
哪些场景,可以利用索引覆盖来优化SQL?
画外音:本文试验基于MySQL5.6-InnoDB。
一、回表查询
1.1 innodb索引分两类:聚集索引和普通索引
-
聚集索引:叶子节点存储行记录,因此必须有且只有一个聚集索引
(1)若定义了PK,PK字段是聚集索引
(2)若没有定义PK,第一个not NULL unique列是聚集索引
(3)否则会创建一个隐藏的row-id作为聚集索引
画外音:所以PK查询非常快,直接定位行记录。 -
普通索引:叶子节点存储主键值
画外音:注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:
_t(id PK, name KEY, sex, flag);_
_画外音:id是聚集索引,name是普通索引。_
表中有四条记录:
_1, shenjian, m, A_
_3, zhangsan, m, A_
_5, lisi, m, A_
_9, wangwu, f, B_
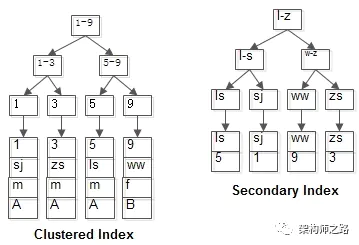
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
1.2回表查询:先定位主键值,再定位行记录
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。
例如:
select * from t where name='lisi';
是如何执行的呢?
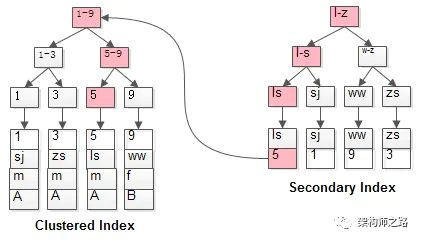
如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号