String、StringBuilder和StringBuffer
一、String
1、String概述
String代表字符串,Java中的所有字符串字面量都是它的实例,如"abc"。String对象是不可变的,一旦创建就不可以再被更改。String被设计为final的,是因为其设计者不希望String被继承而遭到更改。
在不同的JDK版本中,String类的实现略有不同。JDK的设计者对String做了大量的优化,来节约内存空间,提升 String 对象在系统中的性能。
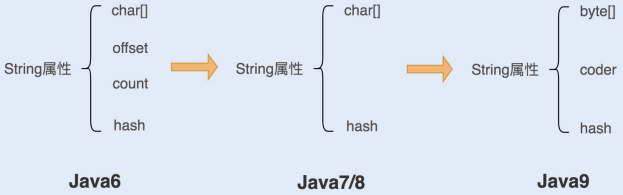
在java6及之前,String是对char数组进行了封装。主要哟四个成员变量:char 数组、偏移量 offset、字符数量 count、哈希值 hash。String 对象是通过 offset 和 count 两个属性来定位 char[] 数组,获取字符串。这么做可以高效、快速地共享数组对象,同时节省内存空间,但这种方式很有可能会导致内存泄漏。
java7和java8中,String类中不再有offset和count两个变量。这样能稍微减少String对象的内存占用,同时能String.substring()方法不再共享char[],从而解决了使用该方法可能导致的内存泄露问题。
从java9开始,工程师将 char[] 字段改为了 byte[] 字段,又维护了一个新的属性coder,它是一个编码格式的标识。一个 char 字符占 16 位,2 个字节。这个情况下,存储单字节编码内的字符(占一个字节的字符)就显得非常浪费。JDK1.9 的 String 类为了节约内存空间,于是使用了占8 位,1 个字节的 byte 数组来存放字符串。
2、字符串常量池(String Pool)
intern()方法是一个native方法,底层调用的是C++的 StringTable::intern 方法。当调用 intern 方法时,如果字符串常量池中已经存在该字符串,则返回池中的字符串;否则将此字符串添加到常量池中,并返回字符串的引用。使用intern()方法时一定要注意,不同的JDK版本可能会得到不同的结果。
看看下面一段程序。
/**
* 下面程序执行结果在JDK6和JDK7中是不同的。
* 在jdk6中,输出:false,false。在jdk7中,输出:true,false。
*/
public class RuntimeConstantPoolOOM {
public static void main(String[] args) {
String str1 = new StringBuilder("计算机").append("软件").toString();
System.out.println(str1.intern() == str1);
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2.intern() == str2);
}
}关于“java”这个字符串是何时首次被放入常量池的,可参考知乎R大的回答:如何理解《深入理解java虚拟机》第二版中对String.intern()方法的讲解中所举的例子?
字符串常量池的内存区域
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
运行时常量池的一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是说,除了预置入Class文件中常量池的内容能进入方法区运行时常量池,运行期间也可以将新的常量放入池中,这种特性被开发人员利用得比较多的便是String 类的intern()方法。

需要注意的是:在java6及之前版本中,字符串常量池存在于方法区中,而由于方法区有内存大小的限制而可能会抛出OutOfMemory。因此,jdk7已经将字符串常量池移到正常的堆中了。
3."+" 操作符
当用"+" 操作符来对多个字符串进行拼接时,实际上编译器将其优化为StringBuilder的append操作了。所以,实际上原有的String实例没有变化,而只是生成了新的StringBuilder实例。当需要进行大量字符串的拼接(包括修改)操作时,可以考虑直接使用StringBuilder来实现。
4.hashcode()方法和equals()方法
equals方法
public boolean equals(Object anObject) {
//当前String与anObject内存地址相同,则说明是同一个对象,返回true
if (this == anObject) {
return true;
}//否则,不是同一个对象
//anObject是String类型才进行比较
if (anObject instanceof String) {
String anotherString = (String) anObject;
//当前String的长度
int n = value.length;
//长度相等才进行比较
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//依次按位进行比较
while (n-- != 0) {
//一旦出现不相等情况,停止比较。返回false
if (v1[i] != v2[i])
return false;
i++;
}
//按位比较完成,如果都相等,说明两者必然相等。返回true
return true;
}
}
//①anObject不是String,没有可比性。返回false
//②anObject是String,但两者长度不等。返回false
return false;
}hashCode方法
public int hashCode() {
//当前String的hashCode
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
//hash = s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}二、StringBuilder/StringBuffer
1.线程安全
StringBuffer相比StringBuilder,前者是线程安全的,因为使用了同步,相应的也会增加性能开销。所以StringBuffer相比StringBuilder,后者性能更高点。
//StringBuilder中的append方法
public StringBuilder append(String str) {
super.append(str);
return this;
}
//StringBuffer中的append方法(多了同步)
public synchronized StringBuffer append(String str) {
super.append(str);
return this;
}2.扩容
StringBuilder和StringBuffer两者实现源码基本类似,扩容方法也是如此,下面则以StringBuilder的append方法为例,来看看是如何扩容的。
public StringBuilder() {
//初始容量默认为16
super(16);
}
public StringBuilder(int capacity) {
//可以指定初始容量
super(capacity);
}
public StringBuilder(String str) {
//使用字符串来构造时,初始容量为字符串长度length+16
super(str.length() + 16);
append(str);
}
private StringBuilder append(StringBuilder sb) {
if (sb == null)
return append("null");
int len = sb.length();
int newcount = count + len;
if (newcount > value.length)
//扩容
expandCapacity(newcount);
sb.getChars(0, len, value, count);
count = newcount;
return this;
}
//扩容
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
//现字符串长度+追加字符串长度之和 与 现长度的2倍+2 之间取最大值
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
//Arrays.copyOf方法
public static char[] copyOf(char[] original, int newLength) {
//生成新的字符数组
char[] copy = new char[newLength];
//本地方法,拷贝数组效率高
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
} StringBuffer在内部维护一个字符数组,当使用缺省的构造函数来创建StringBuffer对象的时候,StringBuffer的容量被初始化为16。StringBuilder和StringBuffer默认的初始容量都是16。当然也可以指定初始容量,此时实际初始容量则是指定容量与16之间取最大值。另外,如果是使用其它字符串来初始化,则初始容量为字符串的长度+16。
当在追加字符串时,如果现有容量不足以容纳追加的字符串,则此时会进行扩容。 扩容时会重新创建一个新的字符数组,然后填充数据,再将新字符数组返回,填充数据使用的是Arrays.copyOf()方法,它是一个本地方法,拷贝效率非常高。需要说明,扩容后的容量是在现有字符串长度+追加字符串长度之和 与 现有字符串长度的2倍+2 之间取最大值。
当在使用StringBuilder/StringBuffer进行大量拼接字符串的操作时,我们可以指定合适的初始容量,以防止其频繁进行扩容,从而增加效率。
为什么建议手动指定初始化容量?
当使用缺省的构造函数来创建StringBuffer对象的时候,StringBuffer的容量被初始化为16。
当StringBuffer达到最大容量的时候,则会进行扩容,将自身容量增加到当前的2倍再加2,也就是(2*旧值+2),即2*16+2 = 34
当StringBuffer再次满时,继续扩容,就会将容量增加到2*34+2 = 70。
每次达到最大容量时,就不得不创建一个新的字符数组,然后重新将旧字符和新字符都拷贝一遍,这也太昂贵了。所以总是给StringBuffer设置一个合理的初始化容量值是一个很好的建议,这样会带来立竿见影的性能增益。
测试题
1.下面代码创建了几个对象?
String s = new String("abc");①"abc"
如果常量池中存在"abc"这个对象,就会直接返回该实例,否则会创建"abc"对象。
②new String("abc")
会在堆上创建对象,参数中的"abc"这个对象就是①中的"abc"
③String s
会在栈上创建引用s,并指向②中创建的对象。
2.剖析下面代码的内存分配。
String str1 = “abc”;
String str2 = “abc”;
String str3 = “abc”;
String str4 = new String(“abc”);
String str5 = new String(“abc”);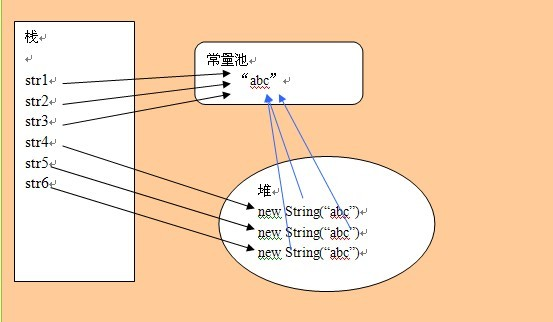
总结:
1.String,StringBuilder,StringBuffer之间的区别。
2.intern方法的作用?字符串常量池的原理?
3.StringBuilder/StringBuffer初始容量?如何扩容?扩容后的容量?
